Day 29: What I Learned Building a Product I Know Nothing About
29 days. 1,134 commits. 109 pull requests. 9 product verticals. One developer who still can't explain what a Heavenly Stem is without looking it up.
This final diary entry isn't a summary — the series articles cover that. This is about the last two days of infrastructure work that made the platform production-ready, and the hardest technical problems I saved for last.
The Portal Theme Bug (PR #67 — 30 files)
Every app has its own CSS theme: .theme-hub with deep blues, .theme-tarot with mystic purples, .theme-bazi with traditional reds. Nine different visual identities across 9 apps.
React portals broke all of them.
createPortal(content, document.body) renders DOM nodes at the root of the document, completely outside the app's theme wrapper div. CSS variables scoped to .theme-hub are invisible to modal and dropdown content because CSS inheritance follows the DOM tree, not the React component tree.
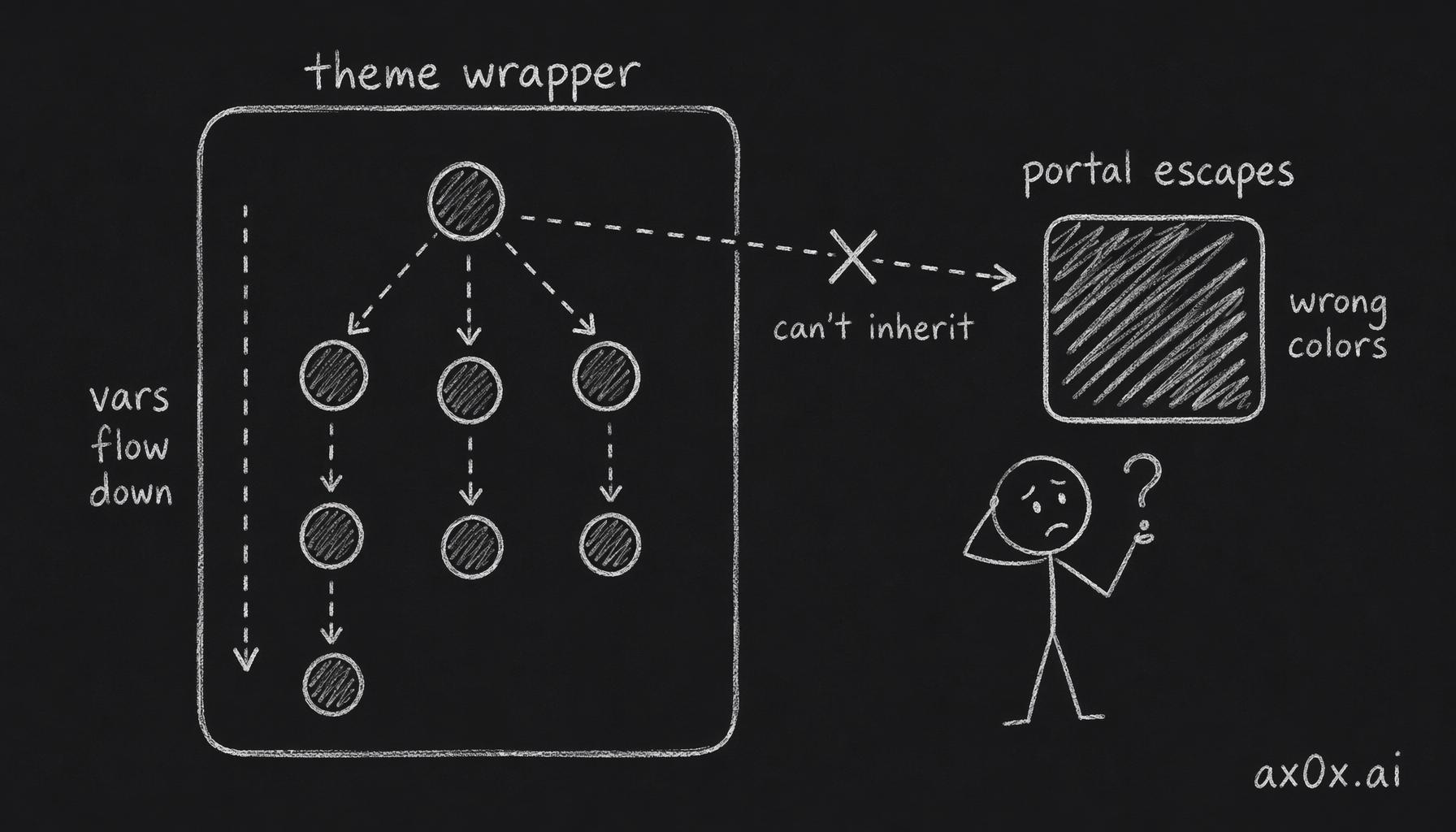 A React portal renders the modal at the DOM root, outside the theme wrapper, so the CSS variables flowing down the DOM tree never reach it and the modal renders with the wrong colors
A React portal renders the modal at the DOM root, outside the theme wrapper, so the CSS variables flowing down the DOM tree never reach it and the modal renders with the wrong colors
The first fix (PR #64) was hacky: each modal component used closest('.theme-hub') to detect which theme it was in and hardcoded a .theme-hub-overlay class. This required per-component patching for all 13 portal-using components across 9 themes. It didn't scale.
PR #67 was the proper fix:
-
ThemeProvider— React context that app layouts set to declare their active theme class -
useThemeClass()— hook to read the active theme from context -
ThemedPortal— drop-in replacement forcreatePortal(content, document.body)that wraps portal content with the correct theme class plus dark mode class via MutationObserver
9 app layouts updated, 13 portal components migrated, all per-component hacks removed. Clean, scalable, correct.
This is one of those bugs that's invisible in development (you only test one app at a time) but painfully obvious in production (user opens a modal and it's the wrong color).
Resilient AI Streaming (PR #105 — 56 files)
The biggest infrastructure PR of the project. Problem: if a user's connection drops mid-stream (common on mobile, especially in China), they lose their entire reading and their credits.
Solution: server-side stream buffering. All 19 AI streaming routes now buffer chunks to a stream_buffers DB table via StreamBufferManager. The architecture:
AI Provider ──stream──▶ Server (ReadableStream)
│
┌──────┴──────┐
│ │
SSE to Client Periodic flush
(real-time) to Supabase DB
│ │
▼ ▼
User sees Buffer saved
live stream for recovery
If the client disconnects, they can recover the full response via GET /api/stream/{id}. A unified useAIStream hook replaced 3 inconsistent SSE consumption patterns across 14 components. Cron job at /api/cron/cleanup-streams removes expired buffers every 15 minutes.
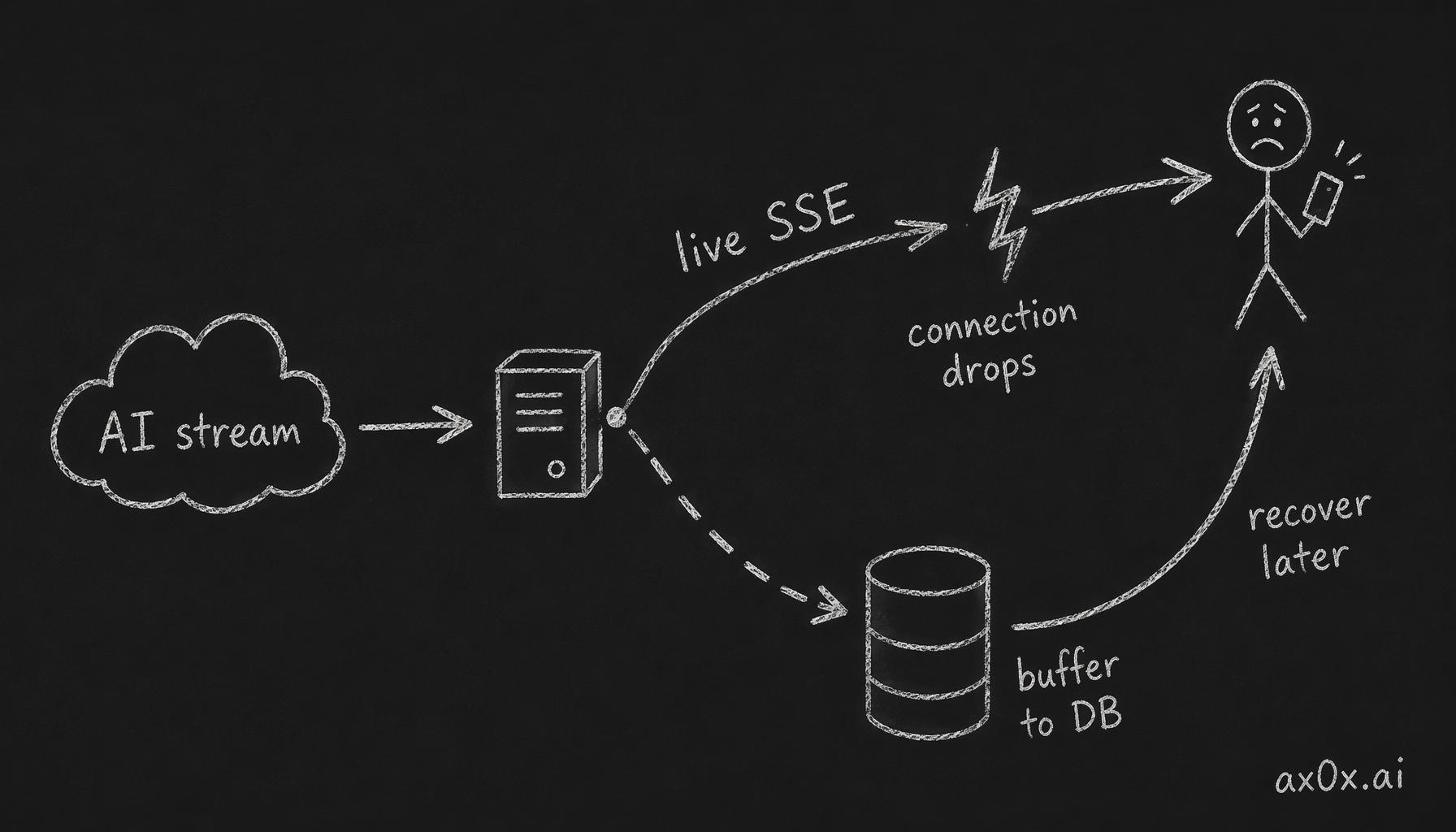 The AI stream forks on the server into two paths: live SSE to the user and a periodic flush into a DB buffer, so if the connection drops the full result can be recovered later from the database
The AI stream forks on the server into two paths: live SSE to the user and a periodic flush into a DB buffer, so if the connection drops the full result can be recovered later from the database
The surprising result: net -186 lines despite adding the entire resilience infrastructure. The unified hook was simpler than the 3 patterns it replaced.
The Content Filter v3 (PR #104 — 14 files)
The content filter went through three iterations over the project:
-
V1: DFA keyword filter. Blocks entire messages containing sensitive words.
-
V2: Stream-aware filter (PR #78). But it truncated the entire stream when a word appeared — users lost credits and got partial readings. Terrible UX.
-
V3 (PR #104): Inline masking. Sensitive words replaced with
**检测到违禁词**inline, stream continues uninterrupted.
The v3 architecture is dual-filter:
-
Input filter (aggressive): blocks ads, politics, porn, criminal content before AI processing
-
Output filter (relaxed): same categories MINUS "ads", because fortune-telling AI naturally generates words like 兼职 (part-time work), 招聘 (recruitment), 桑拿 (sauna) that are flagged as advertising by blunt keyword filters
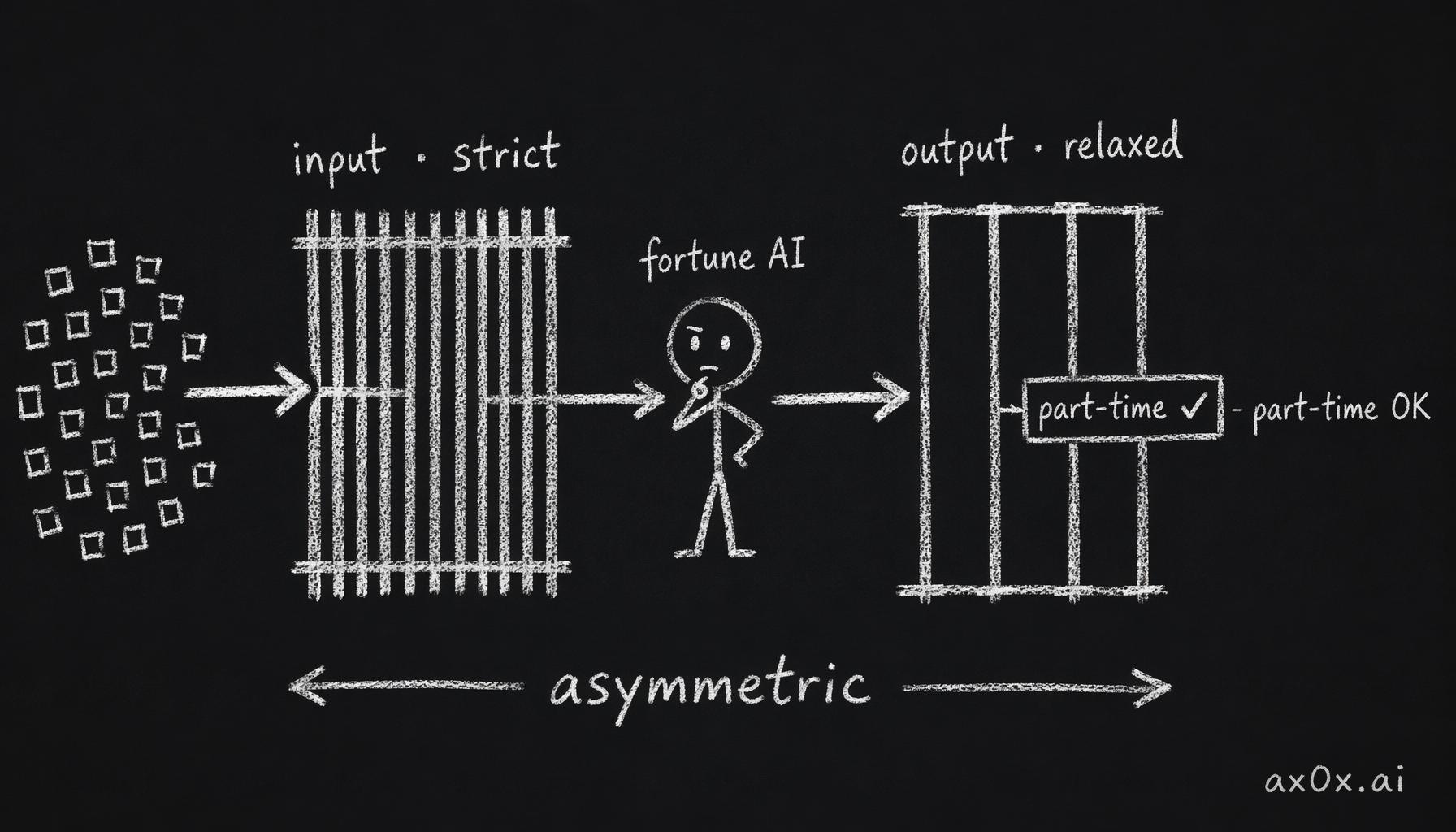 The dual content filter is asymmetric: the input side is aggressive and blocks everything, the output side is relaxed and drops the ads category because the fortune AI legitimately generates words like part-time and recruitment
The dual content filter is asymmetric: the input side is aggressive and blocks everything, the output side is relaxed and drops the ads category because the fortune AI legitimately generates words like part-time and recruitment
The stream filter does boundary-safe masking: it masks the full accumulated buffer before splitting into released/holdback portions, ensuring words that span chunk boundaries are caught.
158 tests across 6 test files.
The i18n Centralization (PR #102 — 10 files)
By this point, label definitions were scattered across 3 consumers: the history management modal, the credits history mapping, and the history config. 180 lines of inline label maps duplicated in slightly different formats.
PR #102 consolidated everything into two central files in packages/i18n/src/labels/: features.ts (app names, short labels, subtype labels, icons, time filters, history titles) and actions.ts (~60 credit action labels). Net: -223 lines from consumers, +607 lines in central source of truth. Future label additions need changes in one place.
China AI Regulatory Compliance (PR #83 — 9 files)
Separated legal pages into Chinese and English versions with a language toggle UI and browser language auto-detection. Added China AI regulatory compliance:
-
生成式人工智能服务管理暂行办法
-
深度合成管理规定
-
算法推荐管理规定
Plus PIPL cross-border transfer mechanisms, sensitive personal information consent, automated decision-making transparency, and a 5-step data breach response procedure with 72-hour regulatory notification.
If you're building AI products for Chinese users, this is non-optional and non-trivial.
By the Numbers
What's Next
This was never about fortune-telling. It was about testing a hypothesis: can one engineer, augmented by AI, build a real, multi-product platform from scratch in a domain they know nothing about?
The answer is yes. The domain knowledge gap was bridgeable. The velocity was real. And building a product — the whole product, not just the engineering — is the most fun I've had in years.
Full series: Part 1 (Why), Part 2 (How), Part 3 (Lessons) cover the condensed story. These diary entries are the raw, day-by-day version.