From 5 Standalone Apps to a Unified Platform in 29 Days
In Part 1, I explained why I decided to build a fortune-telling platform with zero domain knowledge. Now let me tell you how it actually happened — not the highlight reel, but the architectural decisions, the gnarliest bugs, and the infrastructure that made 39 commits/day sustainable.
Phase 1: Five Apps Become One (Days 1-4)
I started with 5 separate Next.js apps in 5 separate repos. BaZi, astrology, tarot, dream interpretation, divination. Each had its own auth, its own Supabase client, its own Tailwind config. Users had to log in five times.
Day 1 was Turborepo setup. 21 commits. Conceptually simple — move apps into apps/, extract shared code into packages/ — but every import path broke. Steps 4 and 5 (fix imports, verify builds) took 80% of the time.
Day 2 was CSS hell. When I unified the Tailwind config into packages/config, every app that relied on custom design tokens broke. Not in an obvious "red error" way — in a subtle "why is this button 2px smaller" way. 38 commits, each fixing a visual regression.
But Day 2 also produced the first real wins: four shared packages extracted — PDF generation, chat history, shared chat UI, and common React hooks. Seeing duplicated code across 5 apps collapse into a single source of truth is deeply satisfying.
Day 3 added MBTI personality test as app #6. Also built WeChat browser detection — a critical piece because a huge percentage of Chinese internet traffic goes through WeChat's built-in browser. The user agent sniffing needed hardening because WeChat's UA string varies across Android, iOS, and desktop.
Day 4 was 56 commits — the unified API package. packages/api standardized how all apps talk to AI models. 52 API routes migrated into a consistent pattern: auth check, credit deduction, model selection, SSE streaming, error handling. Claude Code migrated all 52 by looking at one example. An hour of wall-clock time vs. a full day manually.
Also shipped on Day 4: GDPR compliance, bilingual legal docs, and the first version of a DFA-based sensitive word filter. The filter was critical — metaphysics content naturally includes terms (算命, 破财, 桃花劫) that trigger naive keyword filters. I needed a proper allowlist approach.
Phase 2: Testing, Branding, and the Cat (Days 5-10)
The Testing Sprint
Vitest across the monorepo. Priority order:
-
Shared packages first — the API streaming helper, Supabase client, credit management. These are load-bearing walls.
-
Domain calculation logic — BaZi calculations, tarot card draws, Liuren divination rolls. I can't personally verify correctness (zero domain knowledge), but I can verify deterministic inputs produce expected outputs.
-
API routes — integration tests with mock auth tokens.
GitHub Actions CI: lint, type-check, build, test on every PR. By the time I started formal milestones, the test suite had grown to 1,922 tests across 34 files.
The Brand
PanPanMao (盼盼猫). The calculating cat. The fortune-telling cat. Once the cat theme clicked, everything cascaded. Each app got a cat-themed treatment. The credit currency became dried fish treats (小鱼干). Because what else would you pay a cat with?
Stripe
Four USD credit packages at various tiers with a "Most Popular" anchor tier. The credit abstraction matters — people are more willing to spend 5 fish treats than a dollar amount. Pre-inserted inactive CNY packages for China market launch.
Phase 3: The Hard Engineering (Days 12-19)
Xiangshu: Palm and Face Reading with In-Browser ML
The most technically ambitious feature. PR #1 tells the story: 56 files changed, 6,881 lines added.
MediaPipe runs entirely in the browser. No server round-trip for detection. The hooks architecture:
-
useMediaPipeLoader— lazy WASM loading (~3MB) with module-level cache -
useFaceDetector— real-time BlazeFace at 60fps for camera preview -
useFaceLandmarker— 478-point face mesh, runs once on capture -
useHandLandmarker— 21-point hand landmarks, runs once on capture
PR #50 later localized the WASM and model files to app-hosted assets under public/mediapipe/ because users in China couldn't reliably reach cdn.jsdelivr.net and storage.googleapis.com. PR #35 added GPU→CPU fallback for palm detection on devices where WebGL failed.
The multimodal AI prompt was extensive — raw photo plus annotated photo plus landmark measurements go to Claude or Gemini. You can't just say "read this palm." The prompt has four layers: role definition → knowledge injection (the five officials, three sections, twelve palaces) → cross-validation → structured output format.
The Credit Economy
PR #2 (M1 Foundation): 100 files changed. The key technical challenge was anonymous-to-authenticated account merging. New users start as anonymous Supabase users. When they redeem a code or sign in, their credits, readings, and chat history need to merge seamlessly. The redeem flow is a state machine: idle → checking → redeeming/logging_in → success/error.
The cross-tab credit sync used Supabase real-time subscriptions. The bug was subtle: buy credits in one tab, switch to another, see old balance, think purchase failed, buy again. Fix: real-time subscriptions update every tab within a second.
Standardizing the Streaming Layer
By this point I had 18 SSE streaming routes, each with its own ReadableStream implementation. PR #16 was a major refactor: migrated 15 routes to a shared createAIStreamResponse() helper, eliminating ~1,200 lines of duplicated boilerplate. The helper added lifecycle hooks: initEvents, onComplete, onError, refundCreditsOnError.
Three routes legitimately needed custom streaming: MBTI chat (accumulated-buffer-delta pattern for signal stripping), dream novel (multi-step generation protocol), and daily fortune (non-streaming with server-side caching).
The AI Tone Overhaul
PR #38 was triggered by real user feedback: interpretations were "讨好型" (people-pleasing). Too positive, too generic, didn't match real fortune-telling experience. The fix was a systematic prompt overhaul across all 6 domains:
-
Overall tone: from "整体偏积极正面" to "不要做讨好型解读,好的说好,不好的明确指出"
-
Health readings: from "混合分析" to "中立偏负面 — direct health warnings"
-
Negative indicators: use 凶/不利 directly, then give 化解方案 (mitigation strategies)
This was one of the few changes AI couldn't do alone. The tone calibration required human judgment about cultural expectations.
Phase 4: Milestones and Infrastructure (Days 20-29)
The Milestone Rush
Feb 12 was the most intense day: 15 PRs merged. M1 (credit economy), M2 (Daily Hub), M3 (PostHog analytics) all shipped.
The Daily Hub (PR #4) was an engagement architecture decision. Fortune-telling apps are event-driven — users come with a question, get an answer, leave. The Hub gives a reason to come back daily. Key insight: pre-generate content at midnight Beijing time via cron, not on-demand. When users open the Hub at 8 AM, it's instant. No spinner. The perceived quality difference is dramatic.
Three New Products in One Day
Feb 15: 7 PRs merged. The 流年运程 (Annual Fortune) feature (PR #85) was a full new domain — zodiac calculator, TaiSui analysis, annual stars mapping, AI-powered fortune reading. 48 files, 162 domain tests. The domain knowledge package alone included star catalogs, star-year mapping tables, TaiSui rules, and zodiac personality profiles.
The Portal Theme Bug
PR #67 is one of my favorite engineering stories. Every app has its own CSS theme (.theme-hub, .theme-tarot, etc.). But React portals (modals, dropdowns) render via createPortal(content, document.body) — which places DOM nodes OUTSIDE the app's theme wrapper. CSS variables scoped to .theme-hub are invisible to portal content.
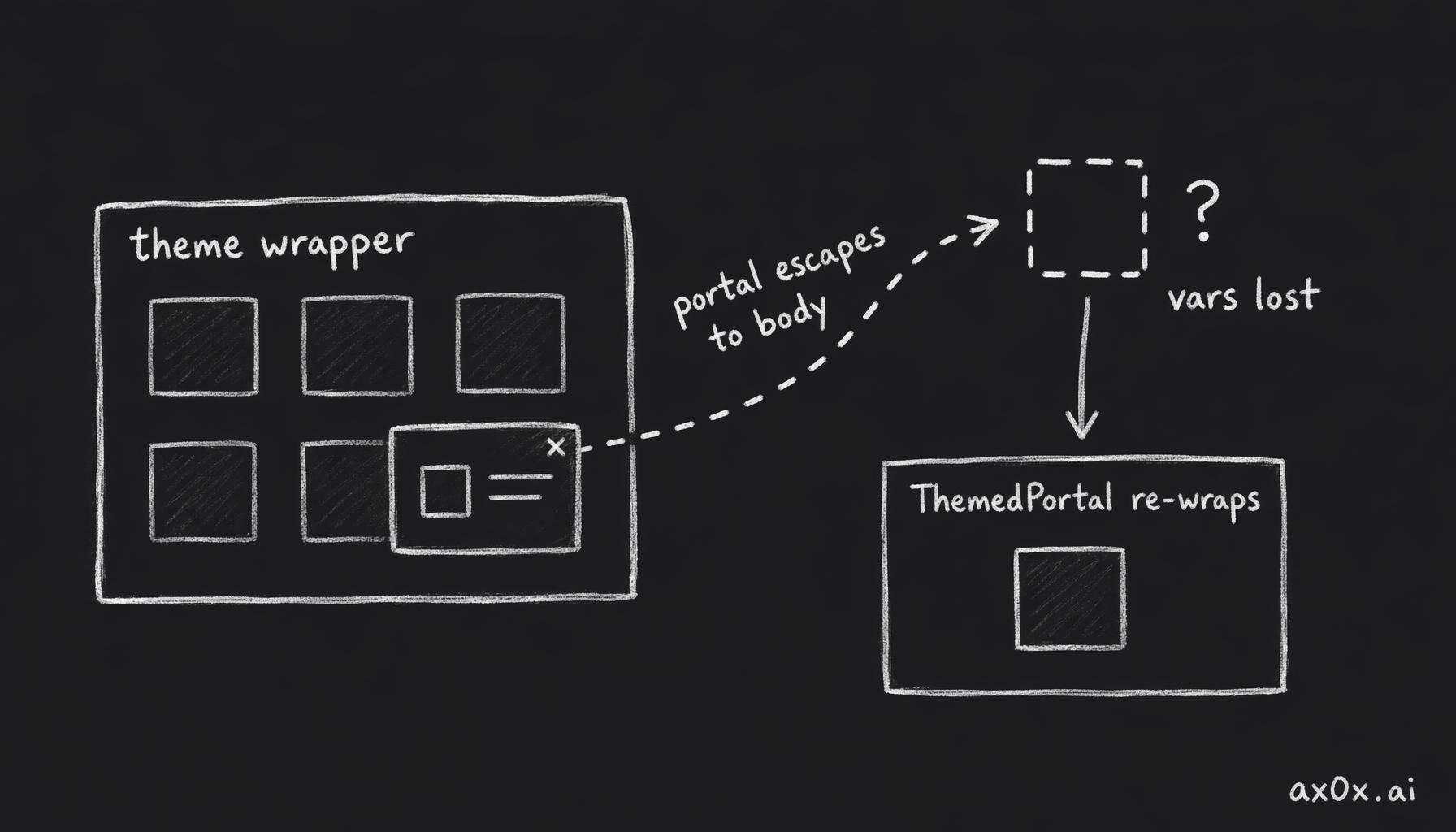 A React portal renders to body, outside the app's theme wrapper, so its CSS variables go missing; ThemedPortal re-wraps the theme class around portal content to fix it
A React portal renders to body, outside the app's theme wrapper, so its CSS variables go missing; ThemedPortal re-wraps the theme class around portal content to fix it
The initial fix (PR #64) was per-component: detect closest('.theme-hub') and hardcode a .theme-hub-overlay class. This doesn't scale across 9 themed apps and 13 portal-using components.
PR #67's solution: a ThemeProvider React context that app layouts set to declare their active theme class, plus a ThemedPortal component that wraps portal content with the correct theme class and dark mode class via MutationObserver. 9 app layouts updated, 13 portal components migrated. Clean, scalable, correct.
Resilient AI Streaming
The last major infrastructure PR (#105): server-side stream buffering. All 19 AI streaming routes now buffer chunks to a stream_buffers DB table via StreamBufferManager. If a client disconnects mid-stream, they recover the full response via GET /api/stream/{id}. A unified useAIStream hook replaced 3 inconsistent SSE consumption patterns across 14 components. Net result: -186 lines despite adding the entire resilience infrastructure. Cron job cleans up expired buffers every 15 minutes.
Content Filter Evolution
The content filter went through three iterations:
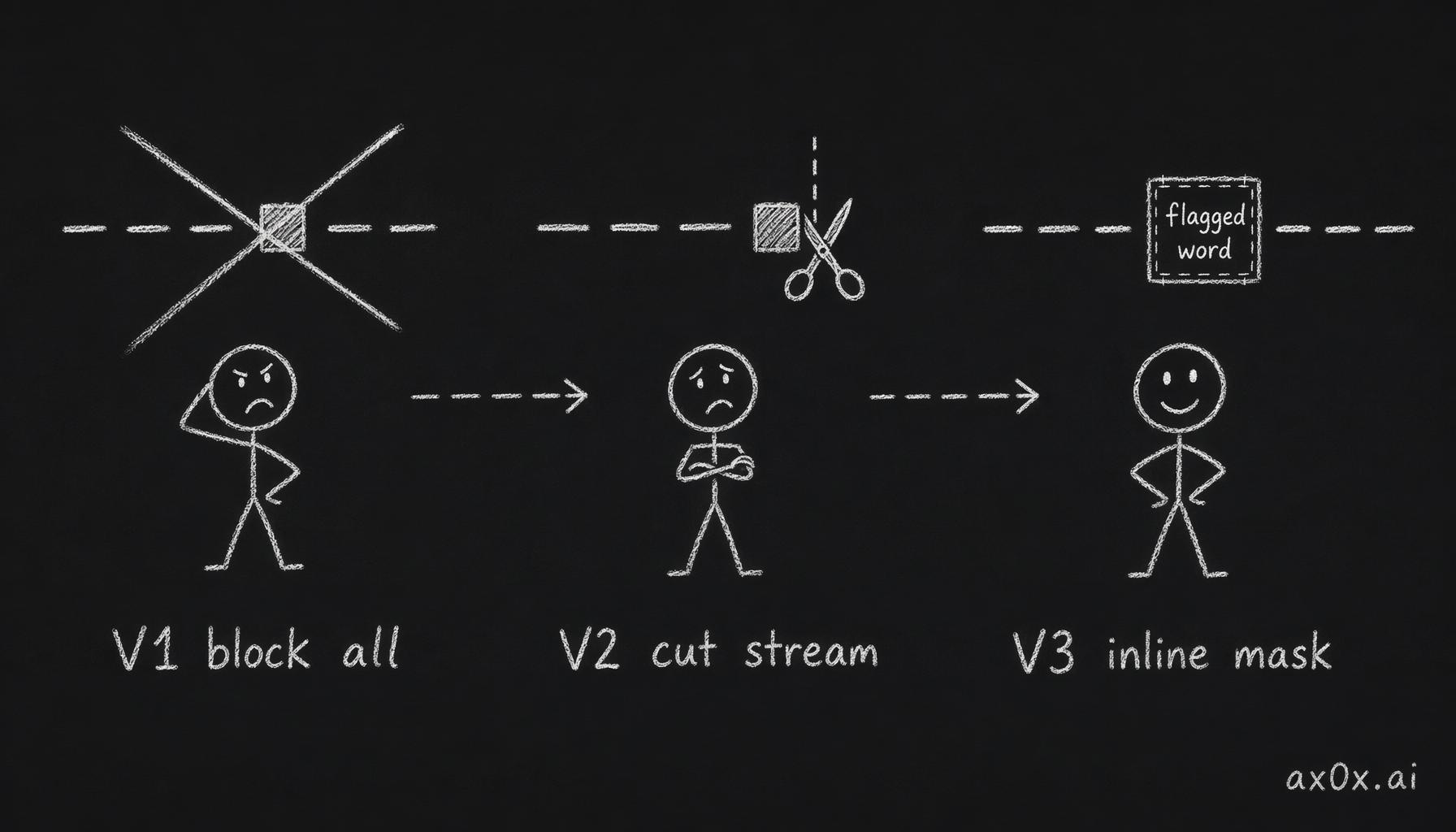 Three versions of the content filter: V1 blocks the whole message, V2 truncates the whole stream on a hit, V3 masks inline without breaking the stream
Three versions of the content filter: V1 blocks the whole message, V2 truncates the whole stream on a hit, V3 masks inline without breaking the stream
-
V1 (Day 4): DFA-based keyword filter. Blocked entire messages containing sensitive words.
-
V2 (PR #78): Stream-aware filter. But it truncated the entire stream when a sensitive word appeared — users lost their credits and got a partial reading.
-
V3 (PR #104): Inline masking. Sensitive words replaced with
**检测到违禁词**instead of killing the stream. Dual-filter architecture: aggressive input filter (ads+politics+porn+criminal) but relaxed output filter (excludes "ads" category to prevent false positives on fortune-telling terms like 兼职, 招聘, 桑拿). Boundary-safe masking handles words that span chunk boundaries.
The Velocity Numbers
-
1,134 commits in 29 days (39/day average, 98 peak)
-
109 PRs filed, 66 merged with detailed descriptions
-
9 product verticals with real business logic
-
85 API endpoints including 19 SSE streaming routes
-
~284,000 lines of code across 16 packages
-
2,021 tests passing at final count
-
0 zero-commit days
The shared packages were the velocity multiplier. Adding a new vertical gets auth, credits, AI model selection, content filtering, streaming, error handling, and UI components for free. The marginal cost of a new product is almost entirely prompt engineering.
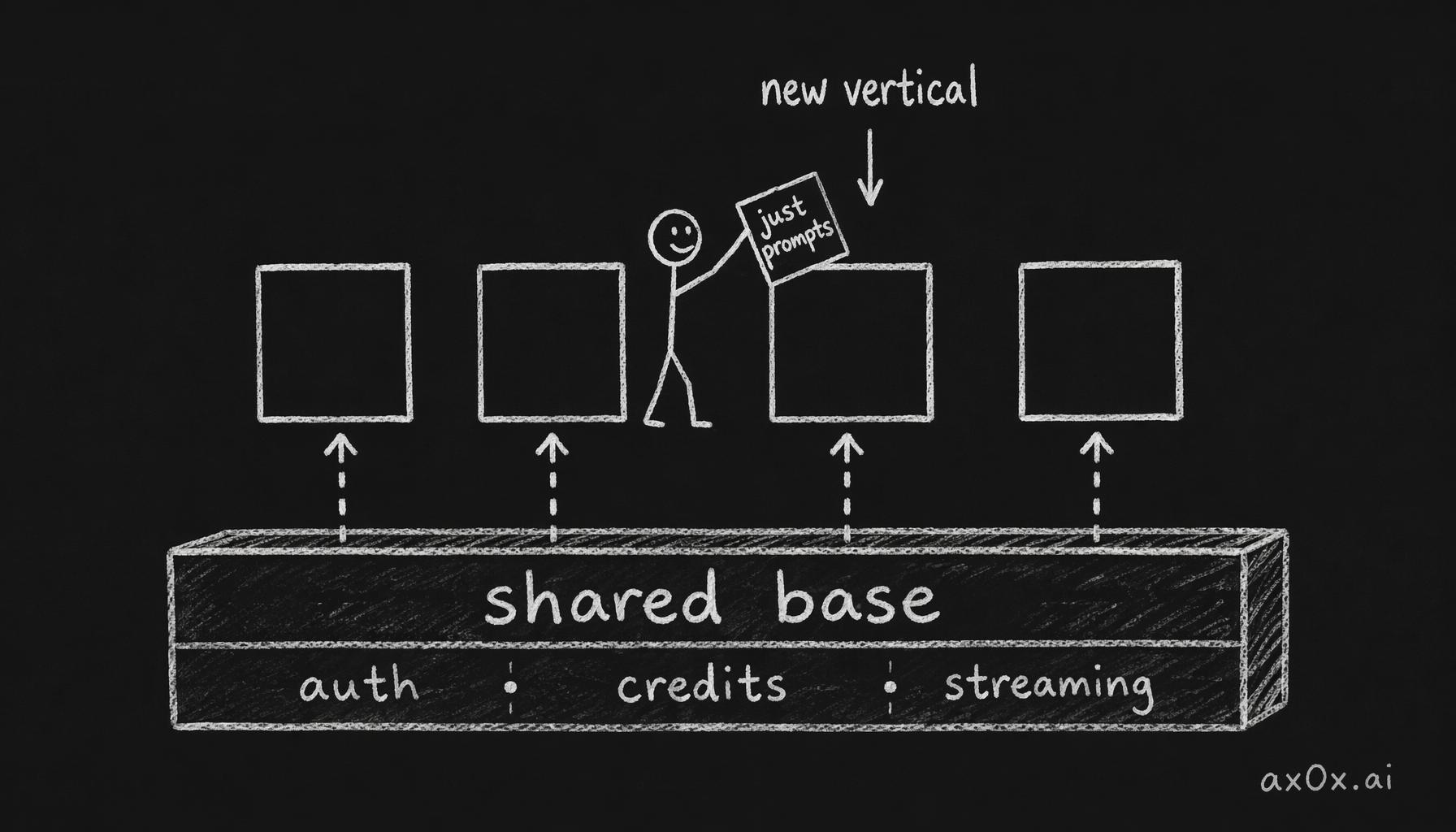 Once shared packages become a foundation, adding a new vertical only costs prompt engineering — auth, credits, and streaming come for free
Once shared packages become a foundation, adding a new vertical only costs prompt engineering — auth, credits, and streaming come for free
In Part 3, I share the honest lessons — what surprised me, what I got wrong, and what this taught me about the future of building.