What I Learned Shipping a Real Product as a Solo AI-Augmented Developer
In Part 1, I explained why. In Part 2, the technical build. Now the honest lessons — not the "everything went great" version, but the real one.
Lesson 1: AI Can Bridge a Domain Knowledge Gap (With One Big Caveat)
The core hypothesis was: can AI completely bridge a domain knowledge gap?
Yes. With one caveat that changes everything.
The codebase has 20,000 lines of BaZi calculation logic. 1,000+ dream symbols with cultural context. 78 tarot cards with detailed interpretation frameworks. A zodiac calculator, TaiSui analysis engine, and annual stars mapping system with 162 passing domain tests. All researched and implemented through AI. Users who practice BaZi say the calculations are correct. People familiar with tarot say the interpretations are nuanced.
But here's the caveat: you need to know HOW to ask questions at the right level of abstraction. I spent the first few days asking Claude to teach me the domain — not to write code, to explain concepts. "How does BaZi work" gives you a Wikipedia overview. "What are the specific Five Elements interaction rules that determine if a Day Master is strong or weak" gives you implementable logic.
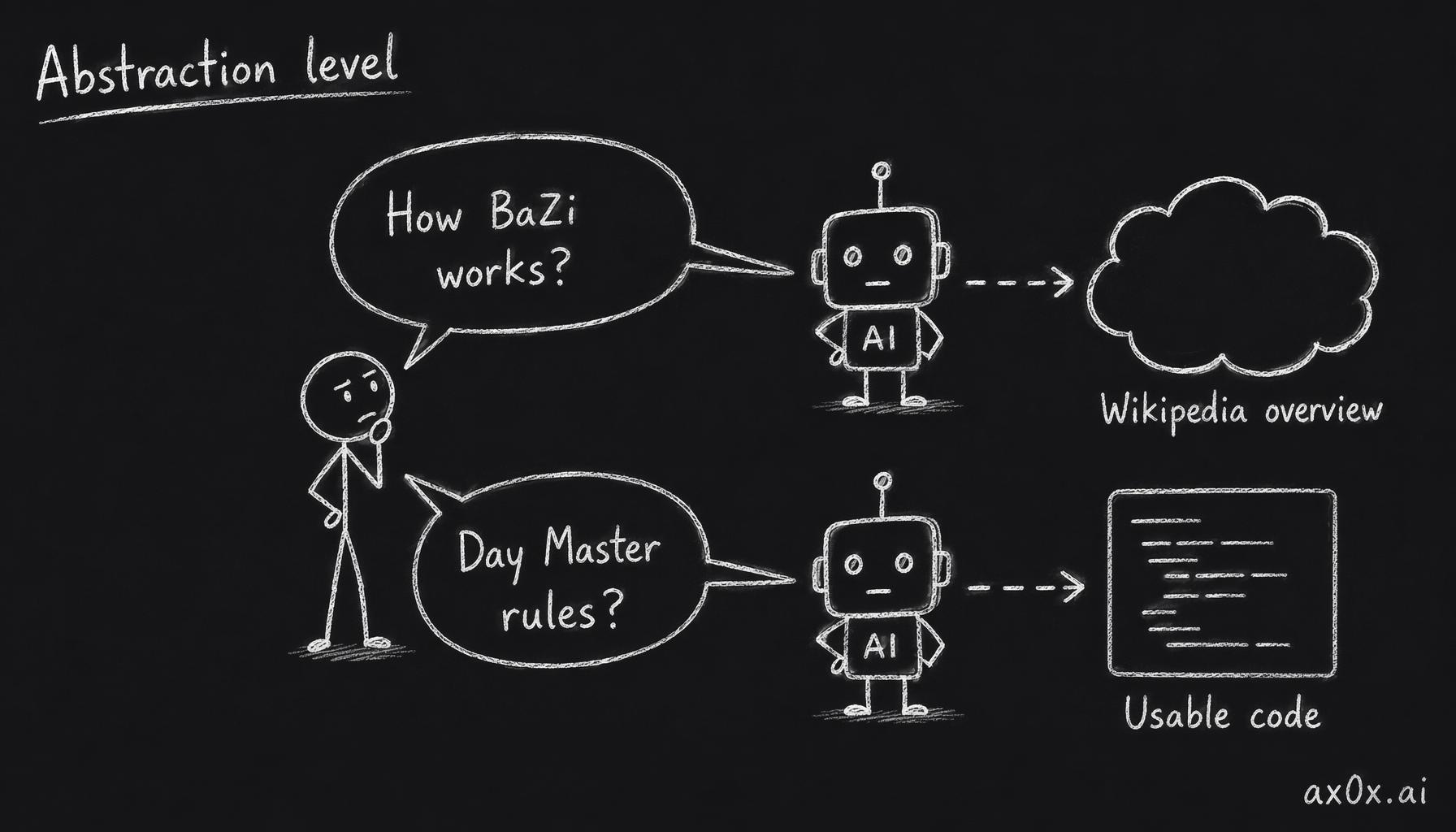 The same AI gives a Wikipedia overview when asked at the wrong abstraction level, but implementable code when asked at the level of specific rules
The same AI gives a Wikipedia overview when asked at the wrong abstraction level, but implementable code when asked at the level of specific rules
Once I had a mental model, I could ask implementation-level questions. Without that model, I would have built a fancy calculator with no real depth.
Zero knowledge is possible. Zero curiosity is not.
Lesson 2: The AI Tone Problem Is Harder Than Any Engineering Problem
PR #38 tells the story. Users reported that AI interpretations were "讨好型" — people-pleasing. Everything was positive. Every reading said you'd be successful. Health was always fine. Relationships were always promising.
Real fortune-tellers aren't like that. They tell you when your chart shows obstacles. They point out unfavorable months. They say "this year's 太岁 (TaiSui) is in direct conflict with your birth year — here's what to watch for."
The fix required changing prompts across all 6 domains. Health readings went from "混合分析" (mixed analysis) to "中立偏负面" (neutral-to-negative) with direct health warnings. Negative indicators shifted from diplomatic ("诚恳指出") to direct (凶/不利), followed by 化解方案 (mitigation strategies).
This was the single hardest thing to get right, and AI couldn't do it alone. Tone calibration requires understanding cultural expectations around honesty, empathy, and authority — the kind of emotional intelligence that current AI models struggle with. I had to manually iterate prompts, get user feedback, adjust, repeat.
Takeaway: AI is excellent at domain knowledge. It struggles with domain culture.
Lesson 3: Product Decisions Are Harder Than Engineering Decisions
Things I severely underestimated:
Landing page iteration. Three full redesigns. The first was warm brown/gold — cozy and approachable. Users thought it was a children's app. The second was clean and minimal. Users thought it was a tech demo. The third was dark luxury — deep blacks, gold accents, the cat as a mysterious oracle. Users said "trustworthy" and "professional." Three redesigns for a positioning problem, not a code problem.
Pricing psychology. I spent more time on credit package naming than on any API endpoint. The decision to call credits "小鱼干" (dried fish treats) instead of "tokens" or "credits" was a product decision that reduced the psychological pain of spending. People buy 5 fish treats more easily than they spend a dollar amount.
Referral incentive design. PR #46 changed referral bonuses from asymmetric (10 for referrer, 3 for referee) to symmetric (5/5). Users felt asymmetry was extractive — "I'm using my friend to get credits." Symmetric made sharing feel like giving a gift. Referral volume increased.
Conversion funnels. The UpgradePrompt component (PR #2) has 7 contextual trigger types, each tailored to its emotional moment — credit-depleted mid-reading is a very different moment from browsing the hub. Plus a 24-hour dismiss cooldown so users don't feel harassed.
Things I overestimated: architectural perfection, comprehensive test coverage. Cover critical paths and ship. Polish comes after product-market fit.
Lesson 4: The Agentic Coding Workflow Is Real (But Not What You Think)
97% AI-generated code does NOT mean 97% less work. It means 97% less typing and roughly 10x more shipping.
My daily workflow:
-
Architect — decide what to build, how it fits the existing system
-
Prompt — describe the feature to Claude Code with enough context about existing patterns
-
Review — every line. AI is more consistent than me at applying patterns but occasionally hallucinated API methods or imported non-existent packages
-
Prompt-engineer — the domain-specific AI prompts were 100% manual work
-
Test — verify edge cases AI didn't think about
-
Course-correct — when AI went down a wrong path, redirect
The claude/ and codex/ branches scattered throughout the git history are where AI agents proposed changes that I reviewed and merged.
Where AI outperformed me: consistency. Claude applied the createAIStreamResponse() pattern more uniformly across 15 endpoints (PR #16) than I would have. Humans get bored with repetitive patterns. AI doesn't. The createRouteCostLogger refactor (PR #21) touched 20 files with the same mechanical change — perfect AI territory.
Where AI struggled: anything requiring judgment calls about user experience. The content filter evolution (three iterations from block-everything to inline masking), the tone overhaul, the referral system redesign — all required human product sense.
Lesson 5: The Things Nobody Tells You About Solo Building
The freedom is intoxicating. No meetings. No standups. No Jira. Just git commit and ship. I went from idea to production in hours, not sprint cycles.
The blind spots are real. No one catches when you're building something users don't want. No one asks "are you sure?" The discipline of knowing when to stop iterating is harder alone. I rebuilt the landing page three times — a team would have caught the positioning problem on redesign one.
The compounding effect of good architecture is dramatic. The first product vertical was hard. By the ninth, adding a new vertical was nearly mechanical: create domain knowledge package, add API routes following the createAIStreamResponse() pattern, build UI components from the shared library, register in credits/history/analytics, deploy.
 A shared architecture foundation makes the first vertical hard and the ninth nearly mechanical, compounding until three new products ship in a single day
A shared architecture foundation makes the first vertical hard and the ninth nearly mechanical, compounding until three new products ship in a single day
On Feb 15, I shipped three entirely new products in one day (child naming, compatibility analysis, annual forecast). That's only possible because the foundation absorbed complexity.
CI as your co-reviewer. Without a team, I leaned heavily on automated quality gates. TypeScript strict mode. 2,021 tests. GitHub Actions on every PR. When I introduced agent teams with Claude Code, I added hooks that blocked teammates from going idle with uncommitted changes and blocked task completion if TypeScript errors existed.
Lesson 6: China Market Compliance Is Non-Trivial
PR #83 separated legal pages into Chinese and English versions with China AI regulatory compliance: 生成式AI暂行办法, 深度合成规定, 算法推荐规定. Added PIPL cross-border transfer mechanisms, sensitive PI consent, automated decision-making transparency, data breach response procedures.
The content filter needed dual architecture (PR #104): aggressive input filter for ads+politics+porn+criminal content, but a relaxed output filter that excludes the "ads" category — because fortune-telling naturally generates words like 兼职, 招聘, 桑拿 that are flagged as advertising by blunt keyword filters.
If you're building for Chinese users: plan for this from the start, not as an afterthought.
The Meta-Lesson
The era of the solo AI-augmented builder is real. But "AI-augmented" is the wrong frame. It implies AI is a supplement. What actually happened:
-
I was the product person (100% human: positioning, pricing, tone, conversion design)
-
I was the architect (90% human: system design, package boundaries, data model)
-
I was the code reviewer (100% human: every line reviewed before merge)
-
AI was the execution engine (95% AI: writing code, applying patterns, mechanical refactors)
-
AI was the domain expert (100% AI: fortune-telling knowledge, calculation logic, cultural context)
The minimum viable team for a multi-product platform has collapsed from "5 engineers, 1 PM, 1 designer" to "1 engineer with good taste and access to AI tools."
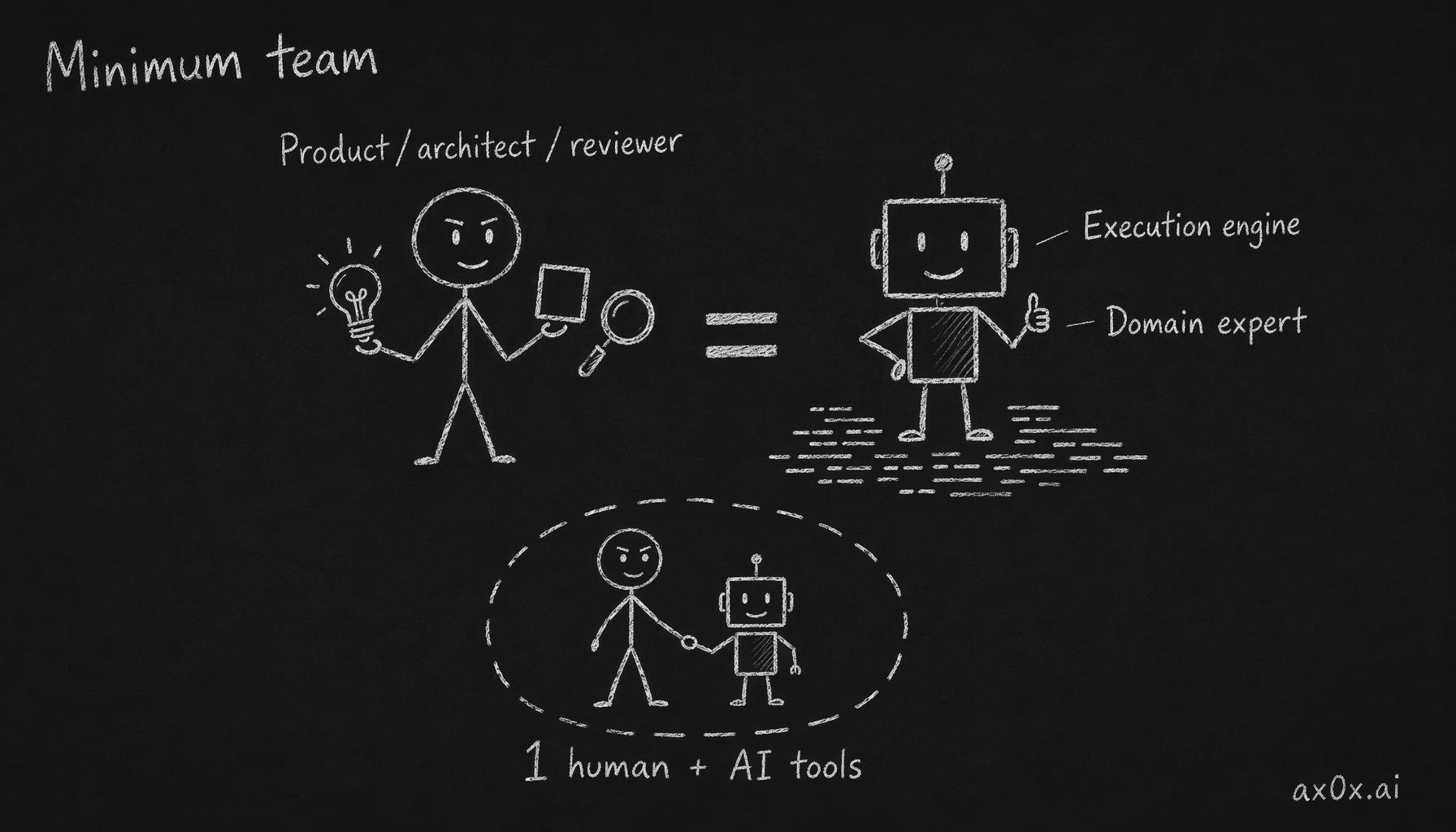 The human owns product, architecture, and code review while AI is the execution engine and domain expert, collapsing the minimum viable team to one person plus AI tools
The human owns product, architecture, and code review while AI is the execution engine and domain expert, collapsing the minimum viable team to one person plus AI tools
The engineers who thrive won't be those who type fastest. They'll be those who architect best, review most critically, and ask the sharpest questions.
PanPanMao is live at panpanmao.ai. 1,134 commits, 109 PRs, 9 product verticals. I still can't read a palm.