The AI-Native Employee Handbook
In the previous piece, I argued that employee handbooks are CLAUDE.md files for humans — three companies generating over $1M per employee, all solving the same problem: how to encode taste into a system that runs without you. The key finding: writing for humans is harder than writing for agents, because humans need motivation, have egos, forget things, and — uniquely — can genuinely push back.
This piece asks the next question: what does the AI-native company's handbook actually look like?
My team at Compute Labs is three people doing the work of fifteen. Not because we're smarter — because each person has strong Will (taste, judgment, direction) and AI handles all Skill. After two months, one thing became clear: this isn't an efficiency gain. The reason the team exists has changed.
Three arguments:
1. AI-native companies hire for one thing: Will. Taste, judgment, direction, curiosity. Resumes are Skill documents — all depreciating. Screening must be redesigned from scratch.
2. The handbook's core shifts from "how to do things" to "how to judge." MrBeast's handbook teaches video production. The AI-native handbook teaches how to evaluate agent output, make judgment calls, and collaborate with AI. The handbook itself is a prompt engineering tutorial.
3. The hardest page to write is the evaluation standard. There's no GAAP for taste. Until there is, the handbook is permanently incomplete.
1. Who to Hire: The Will Profile
In Dao Rises, Skill Fades, I argued that Will (direction, judgment, taste) is appreciating while Skill (execution, technical craft) is depreciating. The AI-native company takes this to its logical extreme — hire only for Will, never for Skill.
The traditional resume is a Skill document. Years of experience, languages mastered, frameworks used, projects completed. All depreciating assets.
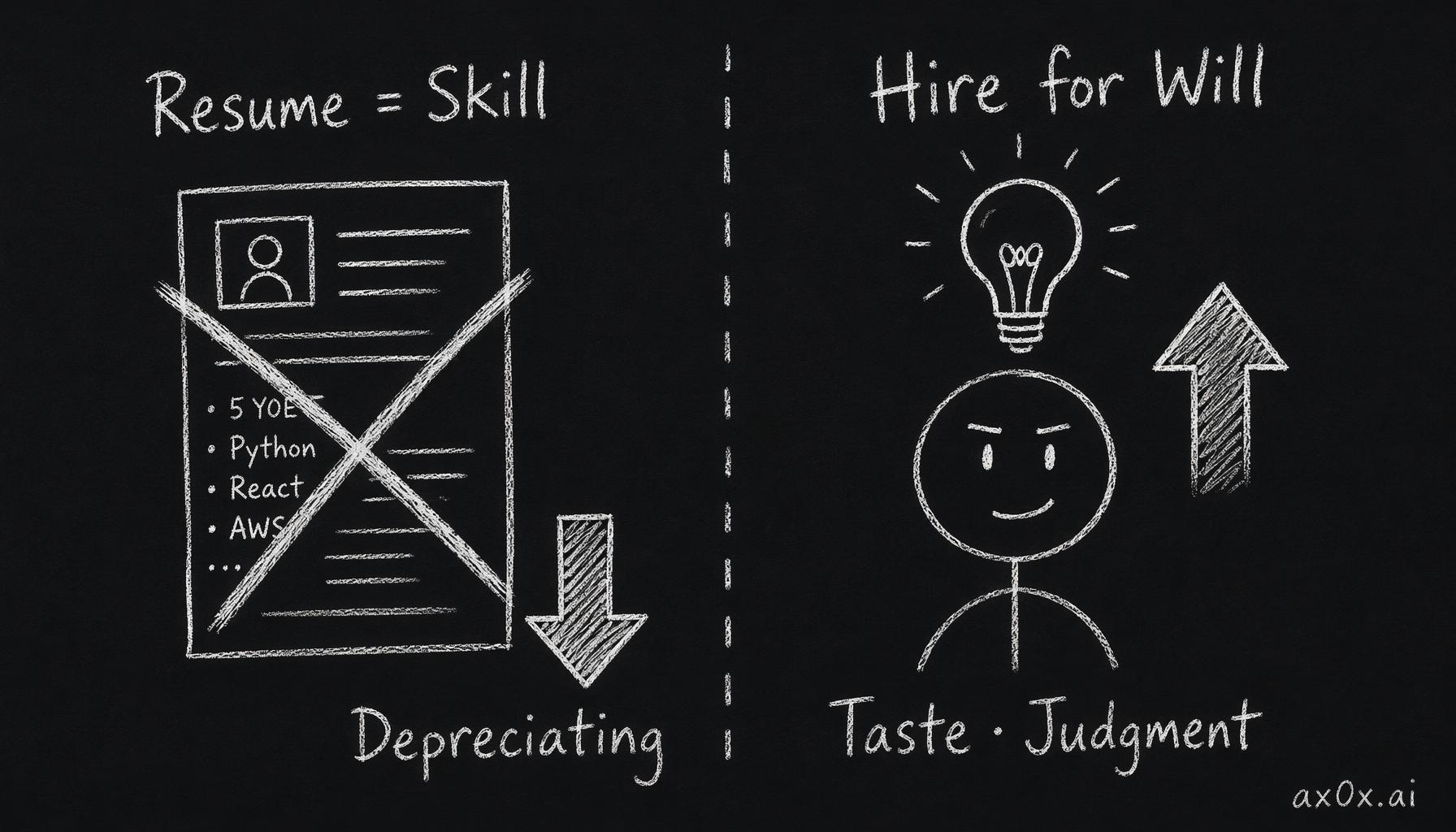 The hiring inversion — a resume is a depreciating Skill document, while the AI-native company hires only for appreciating Will (taste and judgment).
The hiring inversion — a resume is a depreciating Skill document, while the AI-native company hires only for appreciating Will (taste and judgment).
The AI-native company wants people who look like this:
They have their own judgment about what's worth doing. Not waiting for someone to define requirements. They see problems, form opinions, judge priorities. This has nothing to do with seniority — some people have it in year one, some never develop it.
They have their own standard for what "good" looks like. Looking at 40 experiment results and knowing which three matter — that's taste. Reading a draft proposal and feeling where the framing is wrong — that's taste. Finding the signal in noise — still taste. Taste isn't a talent. It's the accumulated output of observation, judgment, mistakes, and correction over time.
Their first response to not understanding something is to go understand it. Cross-domain curiosity is a leading indicator of Will. People who want to understand everything tend to develop better judgment than deep specialists, because judgment needs reference frames — the more you've seen, the better you calibrate.
They can form independent opinions and express them under pressure. The previous piece showed that the biggest difference between human and agent CLAUDE.md is pushback. Humans can genuinely disagree. AI-native companies need this MORE than traditional ones, because when most execution is done by agents, agent sycophancy becomes a systemic risk. Human pushback is the only error-correction mechanism.
2. How to Screen: Four Interviews
Traditional interviews test Skill. Whiteboard coding, system design, "tell me about a project you worked on." All testing what you've done, not how you think.
The AI-native interview is fundamentally different.
Taste test. Show the candidate ten products, ten designs, ten strategies. Rank, critique, explain. No right answers. Two things to evaluate: can they see things the existing team can't? Is their taste complementary or overlapping?
Taste overlap is a team's most hidden trap. Five people with identical taste produce output that covers one angle. AI already makes execution homogeneous — if taste is also homogeneous, the team has no reason to exist.
Judgment simulation. Present a real, ambiguous scenario with incomplete data — from the company's own history. "Here's what we knew at the time. What would you have decided? Why?" Then reveal what actually happened.
Quality of reasoning under uncertainty matters far more than getting the "right" answer. Strong candidates say "I'd first confirm X, because X determines whether the direction is A or B" — they're structuring the uncertainty. Weak candidates guess an answer and rationalize it.
Curiosity probe. What have they explored recently that wasn't required by their job? What rabbit holes have they gone down? What do they know about that has nothing to do with their resume?
This isn't small talk. It tests the potential for cross-domain judgment. Someone who simultaneously understands technology, design, user psychology, and business logic makes decisions several times better than a single-domain expert. In the AI era, that kind of comprehensive judgment may be the scarcest resource.
Dissent exercise. Present the team's current strategy and ask the candidate to argue against it. Not a gotcha — a genuine test of whether they can form independent opinions and hold them under pressure.
If they can't push back on the interviewer's own strategy during an interview, they won't push back on agent sycophancy once hired. The last thing an AI-native company needs is a nodding machine — agents are already the world's best nodding machines.
The hardest thing for most companies to accept: someone who "fails" a traditional coding interview might be exactly the person you need. Traditional interviews filter for insufficient Skill. In an AI-native company, insufficient Skill isn't a problem — AI fills that gap. The real problem is insufficient Will, and traditional interviews don't test for it at all.
3. What the Handbook Says: From "How to Do" to "How to Judge"
This is where the AI-native handbook diverges most from tradition.
MrBeast's handbook teaches you how to make videos — what minute mark you're on, how to optimize retention, how to save money with creativity. Netflix's teaches you how to be a professional — candor, autonomy, excellence. Duolingo's teaches you how to run a system — the Green Machine's six steps.
The AI-native handbook doesn't teach any of that. Because "doing things" is the agent's job. The handbook teaches how to judge whether the agent did well, and how to make it do better.
3.1 Mission — Humans Still Need WHY
The previous piece established that the biggest difference between human and agent system prompts is motivation. Humans need meaning. This doesn't disappear because the company is AI-native.
Page one is still the mission. Not "you are a helpful assistant" — but "why we exist, what problem we're solving, why this is worth betting your career on."
The difference: an AI-native company's mission needs to be exceptionally honest. With only 5-7 people, everyone is on the front line. Bullshit doesn't survive a week.
3.2 Taste Standards — What "Good" Looks Like in Each Domain
This is the handbook's most important section. Traditional handbooks don't need this — execution-level quality has objective standards (does the code run? does the design match the spec?). In an AI-native company, agents handle execution, and agent output is always "good enough." The question isn't whether it works. It's whether it's good.
The handbook defines "good" for each judgment domain:
Product judgment: What makes a feature worth building? What signals indicate a wrong direction? When to persist vs. abandon?
Design judgment: What counts as polished? Where's the V1 floor? (Borrowing Duolingo's concept — V1, not MVP.)
Technical judgment: What counts as "simple"? When to use existing solutions vs. build from scratch?
Business judgment: What partnerships are worth pursuing? What terms are non-negotiable?
These aren't rules — rules can be enumerated. These are judgment frameworks that help you make 70+ point decisions with incomplete information.
3.3 Agent Collaboration — The Handbook IS a Prompt Engineering Tutorial
Everyone at an AI-native company works with agents daily. The handbook must teach how.
How to give instructions. Not "help me analyze this" — but "I have this data, I care about dimensions X and Y, the audience is investors not the internal team, start with investor framing." This is exactly what You Are the Manager described: managing AI requires the same skills as managing people — context, objectives, success criteria.
How to evaluate output. The agent gives you four options. How do you judge which is best? Not by which "looks professional" — by which captures the problem's key constraints. The handbook teaches this thinking.
How to iterate. When the first draft misses, don't say "redo it." Say "direction is right, but switch the valuation model to DCF and add FX exposure to the risk section." Precise feedback fixes in one round. Vague feedback causes five rounds of guessing.
How to counter sycophancy. Agents will say your plan is good. Your plan might not be. The handbook mandates: before every major decision ships, run a red team. A set of agents with explicitly adversarial system prompts. "How could this fail?" "What are we not seeing?" The red team's job isn't to help — it's to tear apart. The team then judges which objections are structural.
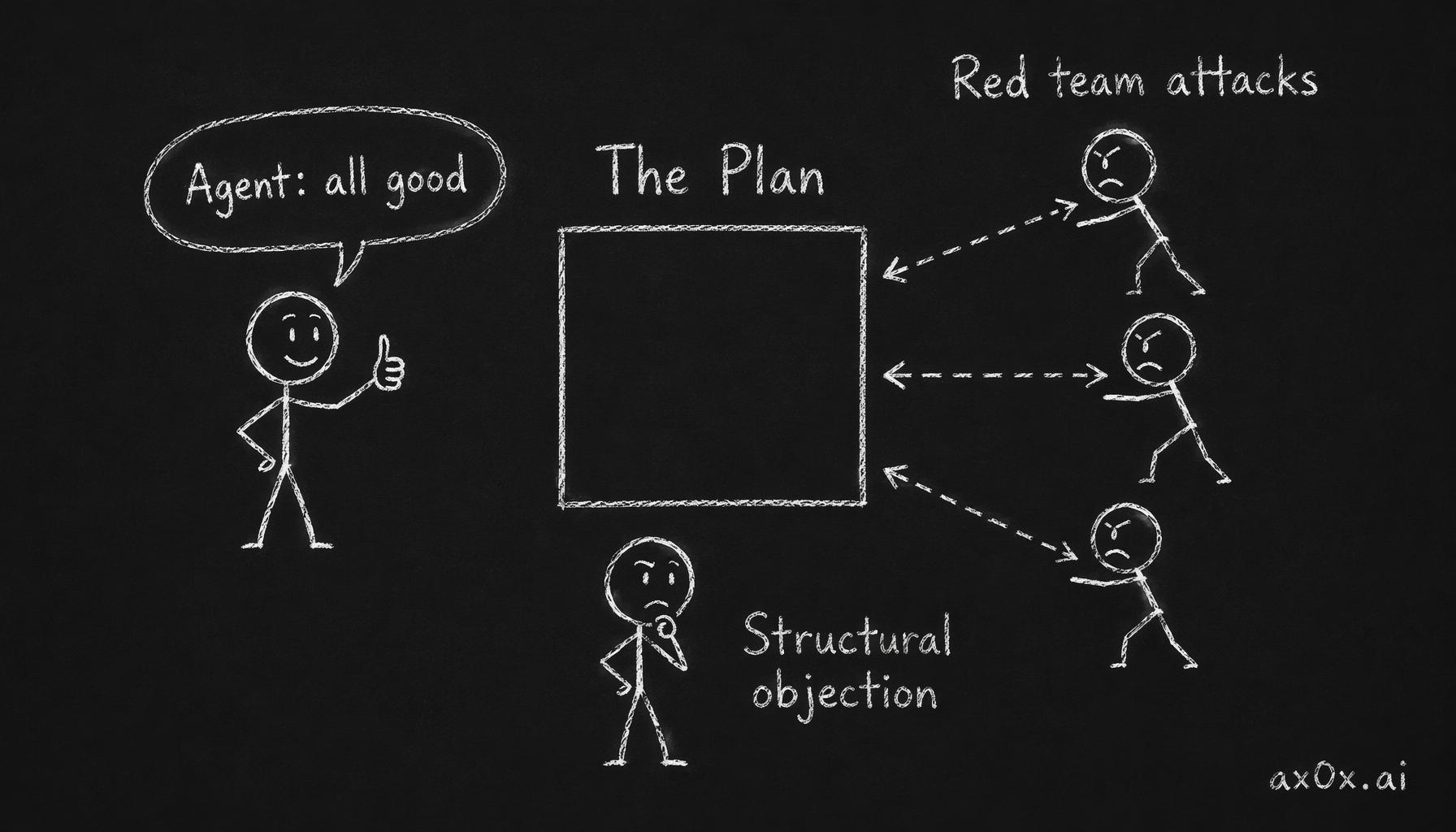 The anti-sycophancy correction loop — agents always approve, so an adversarial red team tears the plan apart and humans judge which objections are structural.
The anti-sycophancy correction loop — agents always approve, so an adversarial red team tears the plan apart and humans judge which objections are structural.
3.4 Decision Protocols — When to Trust Data vs. Judgment
AI-native companies generate enormous data. Agents run experiments, analyze results, produce reports. Data is cheap and abundant.
The danger: when data is easy to get, you start checking data for everything. But the most important decisions — whether to pursue a direction, whether to hire someone, whether to abandon a product — often lack good data. By the time the data arrives, the window has closed.
The handbook specifies: when data decides (Duolingo's experiment-driven model — for quantifiable product optimization), when gut decides (MrBeast's "wow factor" — for unquantifiable taste calls), and when the dissent protocol decides (Netflix's "farming for dissent" — for high-stakes irreversible choices).
A concrete mechanism: run the same analysis with multiple agents configured with different assumptions. One assumes the market is growing, another that it's shrinking. When outputs diverge, the divergence IS the information — it reveals the judgment call the team needs to make.
3.5 Context Records — A Living CLAUDE.md
Every decision, every experiment, every judgment call along with its rationale — recorded in structured form. Not for accountability. For context.
In When AI Delivers Results, I argued that hierarchy's essence isn't power — it's information routing. AI-native companies have no hierarchy. Information routing happens through shared context. Everyone and every agent sees all relevant information.
This is why the "handbook as human CLAUDE.md" analogy runs deeper than metaphor. The AI-native handbook isn't a static document. It's a living system — every decision feeds in, every lesson updates it, every taste standard evolves with the team's experience. It's a continuously updated CLAUDE.md.
4. The Hardest Page: Evaluating Taste
Accounting has GAAP. Software has test suites. Medical coding has ICD-10.
Taste has nothing.
How do you evaluate whether someone has good judgment? You can measure outcomes — but outcomes depend on luck, timing, and a thousand variables beyond the judgment call itself. Good decisions can produce bad outcomes. Bad decisions can produce good outcomes. The feedback loop is noisy and delayed.
You can't optimize what you can't measure. If taste is the company's only asset and taste can't be reliably measured, how do you know if the company is good?
Partial answer: portfolio evaluation over time. Not "was this decision correct?" but "over 50 decisions, does this person's judgment systematically outperform chance?" This requires patience — years, not quarters — and the discipline to record every decision and track every outcome.
Netflix's keeper test is a coarse-grained version of taste evaluation: "knowing everything I know today, would I hire this person again?" It works, but it's qualitative, retrospective, and depends on the manager's own judgment. The AI-native company needs a more precise version — retrospective calibration. Six months ago we decided X. The data now shows Y. Were we right? Over time, this mechanism tells you where the team's taste is accurate and where it's miscalibrated.
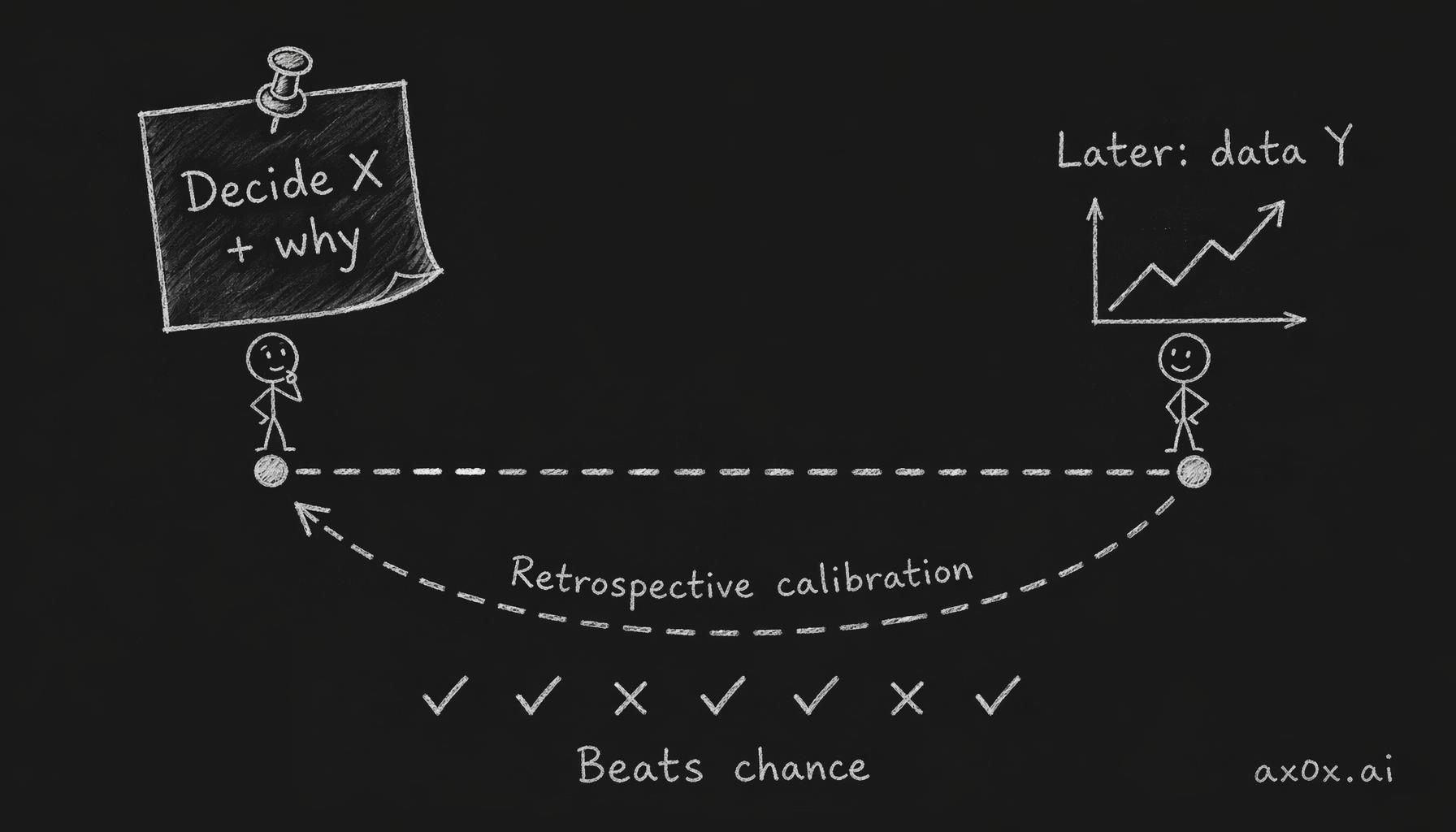 Retrospective calibration — record each decision with its rationale, check it against the data months later, and judge whether someone's calls beat chance across dozens of decisions.
Retrospective calibration — record each decision with its rationale, check it against the data months later, and judge whether someone's calls beat chance across dozens of decisions.
This is the hardest page in the handbook. Also the most important. Whoever builds it first — the "GAAP for taste" — unlocks the full potential of AI-native organizations.
The AI-native handbook has one fundamental difference from MrBeast's, Netflix's, and Duolingo's: traditional handbooks teach you how to do a job well. The AI-native handbook teaches you how to judge whether a job is worth doing at all.
The tool era's handbook was an operating manual. The outcome era's handbook is a judgment framework.
Writing for humans is still harder than writing for agents. Because you're not just encoding taste and judgment standards — you're encoding why a group of people chose to bet their best thinking on the same thing.