AI 原生公司招人不看简历
先交代下背景。Compute Labs 现在就三个人,两个月做了六个产品,产出量级大概能抵一支十五人的传统团队,这个数字我自己说出来都觉得有点离谱,但确实就是这样。我不觉得我们三个有谁特别聪明,真的,差别就在每个人都有比较强的 Will,就是品味、判断、方向感这些东西,Skill 层面的活基本全让 AI 接管了。做满两个月,我只能说,AI 带来的变化比提效要深得多,深到团队为什么存在这个事情本身都变了。
上一篇拆过三家百万人效公司的手册,结论是员工手册是给人类写的 CLAUDE.md:三份手册干的其实是同一件事,把品味编码进一个系统。而且给人写比给 AI 写更难,因为人需要激励、有自尊、会遗忘。顺着这个结论往下走,自然会撞上一个新问题:要是从零开始,给一家 AI 原生公司写员工手册,该写什么?结合这两个月的体感,加上道升术降那套框架,我现在的答案大概能压成三条:
- 招人只看 Will,也就是品味、判断、方向感、好奇心。简历上的 Skill 全在贬值,筛选方法得整个重做。
- 手册的核心从「怎么做事」换成「怎么判断」:教人评估 agent 的产出、做判断抉择、跟 agent 协作。它本身就是一份 prompt engineering 教程。
- 最难写的一页是评估标准。品味没有 GAAP,一个人判断力好不好没法衡量,这个问题不解决,手册永远写不完。
简历是一份 Skill 文档,全在贬值
道升术降里我分析过,Will(方向、判断、品味)在升值,Skill(执行、技术)在贬值。AI 原生公司等于把这个逻辑推到极致:只招 Will,不招 Skill。而简历呢,恰好就是一份纯 Skill 文档,工作年限、会几门语言、用过什么框架、做过什么项目,全是贬值资产。你花三年学会的东西,明年 AI 可能就会了。
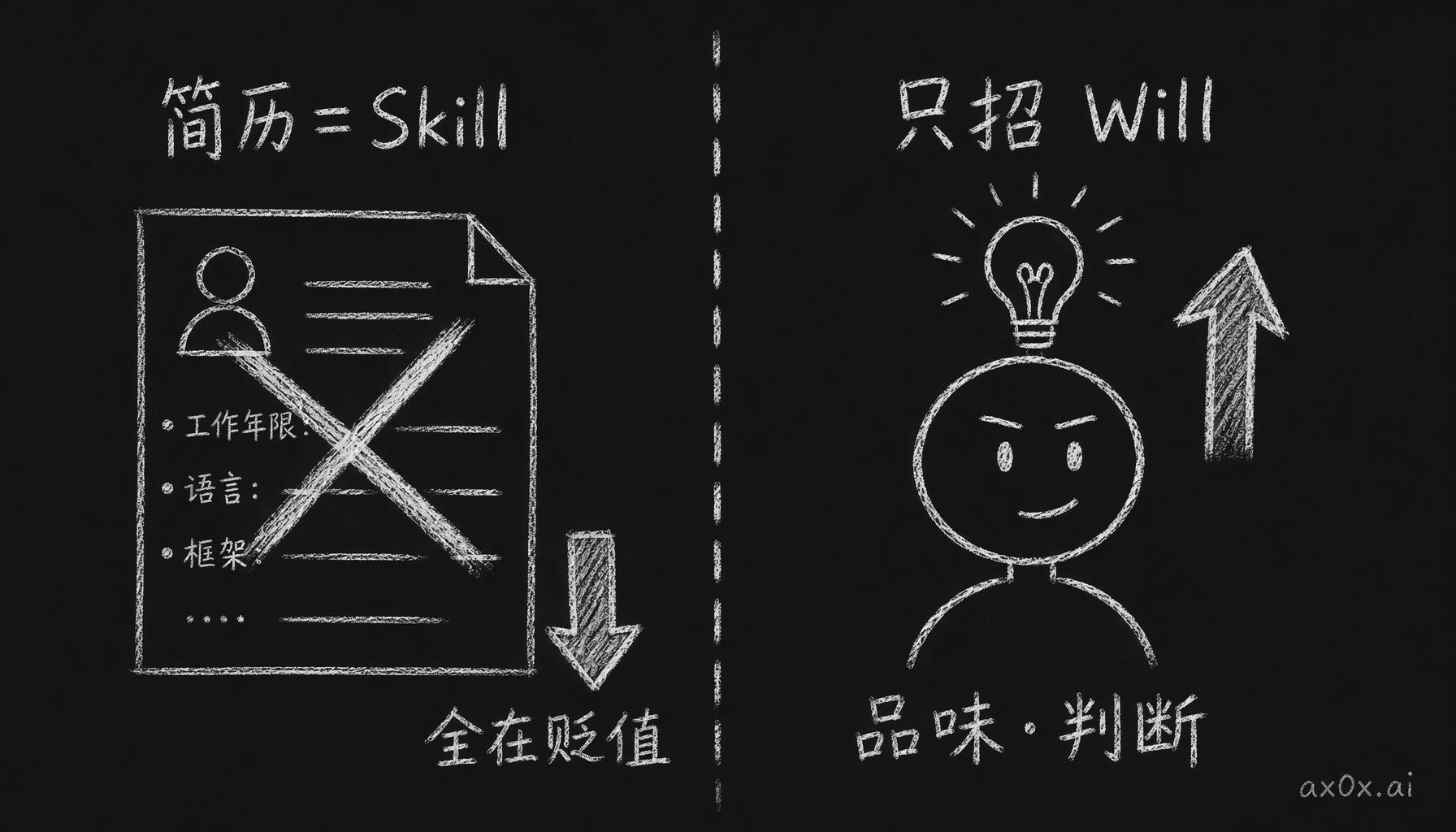 招人机制反转——简历是一份不断贬值的 Skill 文档,AI 原生公司只招升值的 Will(品味·判断)。
招人机制反转——简历是一份不断贬值的 Skill 文档,AI 原生公司只招升值的 Will(品味·判断)。
那要找什么样的人?我心里的画像大概四条:
- 对「什么值得做」有自己的判断。等别人把需求定义好再执行的不算,得自己能看到问题、形成观点、排出优先级。这个能力跟工作年限关系真不大,有人第一年就有了,也有干了十年还在等别人告诉他该做什么的。
- 对「什么算好」有自己的标准。看 40 组实验结果,能挑出有价值的那三组;读一份草案,能感觉到框架哪里不对。说白了就是从噪声里挑信号这一种能力。而且这种眼力我觉得没什么天赋成分,就是大量观察、判断、犯错、修正,一点点长出来的。
- 遇到不懂的东西,第一反应是去搞懂。跨领域好奇心是 Will 很早期的一个信号:什么都想搞懂的人,判断力一般比只在一个领域深耕的人好。原因也不玄乎,判断力需要参照系,见过的东西越多,看新东西的标准就越准。
- 能形成独立观点,还能讲清楚。上一篇提过,人类 CLAUDE.md 和 agent 的 CLAUDE.md 最大的区别是「推回来」的能力。AI 原生公司格外需要这条:执行大部分是 agent 干的,agent 永远说你的方案好,这种谄媚是系统性风险,人能推回来,基本是唯一的纠错机制。
张月光说过一个原则,我觉得说得很准:团队需要共同方向和一致的价值观,但品味、风格、思维方式必须不同。AI 已经把执行拉平了,同样的工具、同样的 spec,写出来的代码几乎一样,那差异化基本就只能来自人看东西的角度不一样了。
白板题测不出 Will
现在的面试,白板写代码、系统设计、「讲讲你做过的一个项目」,测的全是 Skill,是这个人做过什么,测不出他怎么想。想筛 Will,得换一套测法。我能想到的是四种:
- 品味测试。给候选人看十个产品、十个设计、十个策略,让他排序、批评、解释,没有标准答案。看两件事:他能不能看到团队现有成员看不到的东西,他的品味跟团队是互补还是重叠。品味重叠是团队最隐蔽的坑,五个人品味一样,做出来的东西其实只覆盖一个视角,执行又已经被 AI 拉平了,那这个团队就很难说还剩下什么了。
- 判断模拟。从公司历史里挑一个真实的、信息不完整的模糊场景摆在他面前,「当时我们知道这些,你会怎么决定,为什么」,聊完再揭晓实际发生了什么。看的是不确定性下的推理质量,不是答没答对。好的候选人会说「我先确认 X,X 决定方向是 A 还是 B」,他在把不确定性结构化;差的候选人直接猜一个答案,然后自圆其说。
- 好奇心探测。最近在工作之外折腾了什么,钻过什么不相关的兔子洞,对什么跟简历毫无关系的领域有了解。听着像闲聊,实际在测跨领域判断力的潜力。一个同时懂技术、设计、用户心理和商业逻辑的人,判断比只懂一个领域的人好几倍,这种综合判断力在 AI 时代可能是最稀缺的资源。
- 异议演练。把团队当前的策略摆出来,请他反驳。这不是设套,测的就是他能不能形成独立观点,还能顶住压力说出来。连面试官的策略都推不回去的人,进了团队大概率也不会去推回 agent 的迎合。
说实话,照这个逻辑推下去,一个过不了编程面试的人,可能反而正是 AI 原生公司要的人,这一点估计大多数公司都接受不了。Skill 不足在这里根本不是问题,AI 补得上;麻烦的是 Will 不足,白板题压根不测这个。
手册的核心换成了「怎么判断」
上一篇拆的那三份手册,MrBeast 教的是怎么做视频,具体到第几分钟该发生什么、留存率怎么优化、怎么用创意省钱。Netflix 教怎么做人,坦诚、自主、追求卓越那一套。Duolingo 教的是怎么跑系统,绿色机器的六步循环。说到底都是教「怎么做事」。AI 原生公司的情况是,做事的部分 agent 干了,手册要教的变成了怎么判断 agent 干得好不好,怎么让它干得更好。这是差别最大的一块。
第一页还是使命
上一篇分析过,给人写和给 AI 写系统提示词,最大的区别之一是人需要意义。这个需求不会因为公司是 AI 原生就消失,所以手册第一页依然是使命。这一页不能写成「你是一个 helpful assistant」那种套话,得老老实实回答:我们为什么存在,在解决什么问题,为什么这件事值得把职业生涯押上去。AI 原生公司的使命还得格外诚实,团队就 5-7 个人,每个人都在前线,空话活不过一周就会被看穿。
每个判断域都要定义「好」
这部分是手册里最重的。执行层面的好坏本来有客观标准,代码能不能跑,设计稿符不符合规范,一眼能看出来,不需要手册教。麻烦在 agent 的输出永远「过得去」,你要判断的从「能不能用」变成了「够不够好」,而「够不够好」这个事,没有客观标准。
所以手册得把每个判断域的「好」写清楚。产品上,什么样的功能值得做,什么信号说明方向错了,什么时候该坚持、什么时候该放弃。设计上,什么算精良,V1 的底线在哪,这里可以直接借 Duolingo 的概念,V1 不是 MVP。技术上,什么算简洁,什么时候用现成方案、什么时候从头建。商务上,什么样的合作值得谈,什么条件是底线。这些标准跟规则不一样,规则可以穷举,判断框架不行,它的用处是帮人在信息不完整的时候做出 70 分以上的决定。
手册同时是一份 prompt engineering 教程
AI 原生公司的每个人每天都在跟 agent 协作,所以手册必须教会四件事:
- 下指令。「帮我分析一下」是坏指令,好指令长这样:「我有这些数据,关心的维度是 X 和 Y,给投资人看的和给团队内部看的分析方式不同,先给我投资人视角。」道理跟你是管理者里写的一样,管 AI 跟管人是一回事,给足 context、定清楚目标、说明白「好」长什么样。
- 评估产出。agent 一次给你四个方案,挑哪个?看哪个方案抓住了问题的关键约束,「看起来专业」不算数。手册要教的就是这套看法。
- 迭代。第一版不对的时候,别只说「重做」,要说「方向对,估值模型换成 DCF,风险部分加上汇率敞口」。反馈给得精确,一轮就能改对;只丢一句「不太行」,它就得猜好几轮。
- 防谄媚。agent 会说你的方案很好,你的方案可能并不好。所以每个重大决策发出去之前跑一次红队,用一组专门配了对抗性指令的 agent 找茬:这件事可能怎么失败,我们没看到什么。红队只负责拆台,不负责帮忙,哪些反对意见是结构性的,团队自己再判断。
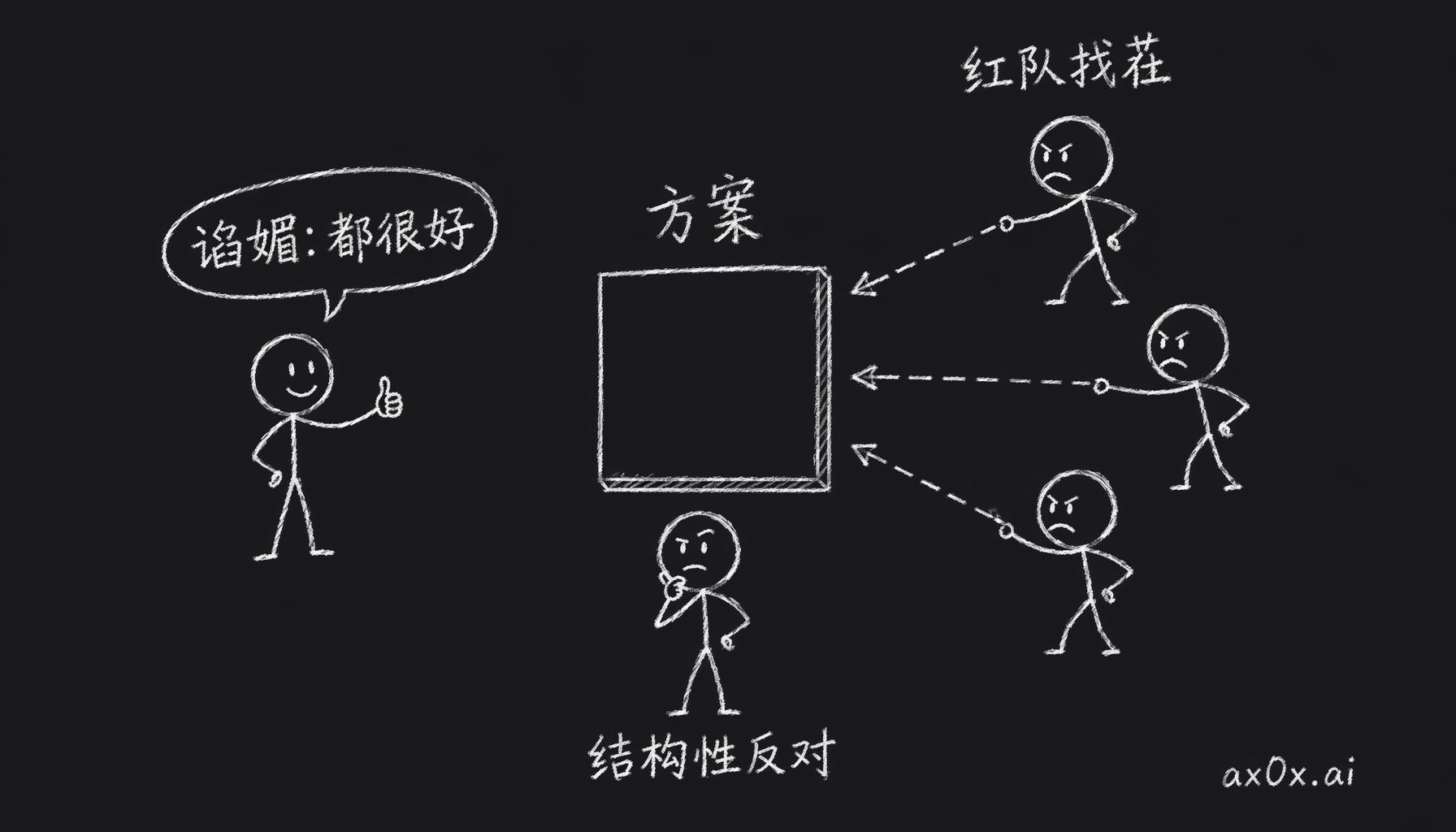 反谄媚纠错回路——agent 永远说方案好,用一组对抗性红队专门拆台,人来判断哪些反对是结构性的。
反谄媚纠错回路——agent 永远说方案好,用一组对抗性红队专门拆台,人来判断哪些反对是结构性的。
什么时候信数据,什么时候信直觉
AI 原生公司会产生大量数据,agent 跑实验、分析结果、生成报告,数据唾手可得。危险恰恰在这里:数据太容易拿到,人会慢慢变成什么都看数据。偏偏最重要的那些决策,做不做一个方向、要不要一个人、放不放弃一个产品,往往没有好数据,等数据出来,窗口早就过了。
手册要写明白哪类决策听谁的。能量化的产品优化,交给数据就行,照 Duolingo 那套实验驱动跑。品味类的判断量化不了,那就听直觉,MrBeast 的 wow factor 其实就是这么用的。还有一类是高风险、不可逆的决定,这种必须走异议流程,像 Netflix 那样主动征集反对意见。
还有一个我觉得挺好用的机制:同一个分析,用不同的假设跑多个 agent,一个假设市场在增长,一个假设在萎缩。输出不一致的时候,不一致本身就是信息,它标出来哪里需要人拍板。
决策连同理由一起记录
每个决策、每个实验、每个判断,连同理由一起结构化记录下来。这套记录不是拿来问责的,拿去问责就糟蹋了,它的价值全在 context。后 Agent 时代的组织里我分析过,层级制看着是权力结构,实际干的活是信息路由。AI 原生公司没有层级,信息路由靠的就是共享 context,每个人、每个 agent 都能看到所有相关信息。
这也是「手册就是人类 CLAUDE.md」这个类比比看上去更深的地方。AI 原生公司的手册没法是一份静态文件,它得是个活的系统,每个决策、每个教训都往里写,品味标准跟着团队的经验一起演进。就是一份一直在更新的 CLAUDE.md。
品味没有 GAAP
最后是最难的一块,评估。会计好歹有 GAAP 这种大家公认的标准,品味这边是真的什么都没有。
评估一个人的判断力,最直接的办法是看结果。但结果这个东西掺了太多运气和时机,好决策照样可以出坏结果,反过来也一样,反馈又吵又慢。管理学有句老话,不能度量的东西没法优化。品味偏偏是 AI 原生公司唯一值钱的资产,又偏偏最难度量,所以公司到底好不好,说实话就是一笔糊涂账。
目前我能想到的部分解法是组合评估,把时间线拉长。别盯着单个决策对不对,看过去 50 个决策里,这个人的判断是不是系统性强于随机。这个需要耐心,单位是年,一个季度看不出什么,也需要纪律,每个决策连同理由记录在案,每个结果都追踪回去。
Netflix 有个 keeper test,「知道我现在知道的一切,还会雇这个人吗」,算一种粗粒度的品味评估。有用,但它是定性的、回溯的,全靠管理者个人判断。AI 原生公司需要更细的版本,我管它叫回溯校准:半年前决定了 X,数据现在显示 Y,回头核对当时的判断对不对。攒得够久,这套机制能告诉你团队的品味在哪些领域准,在哪些领域偏。
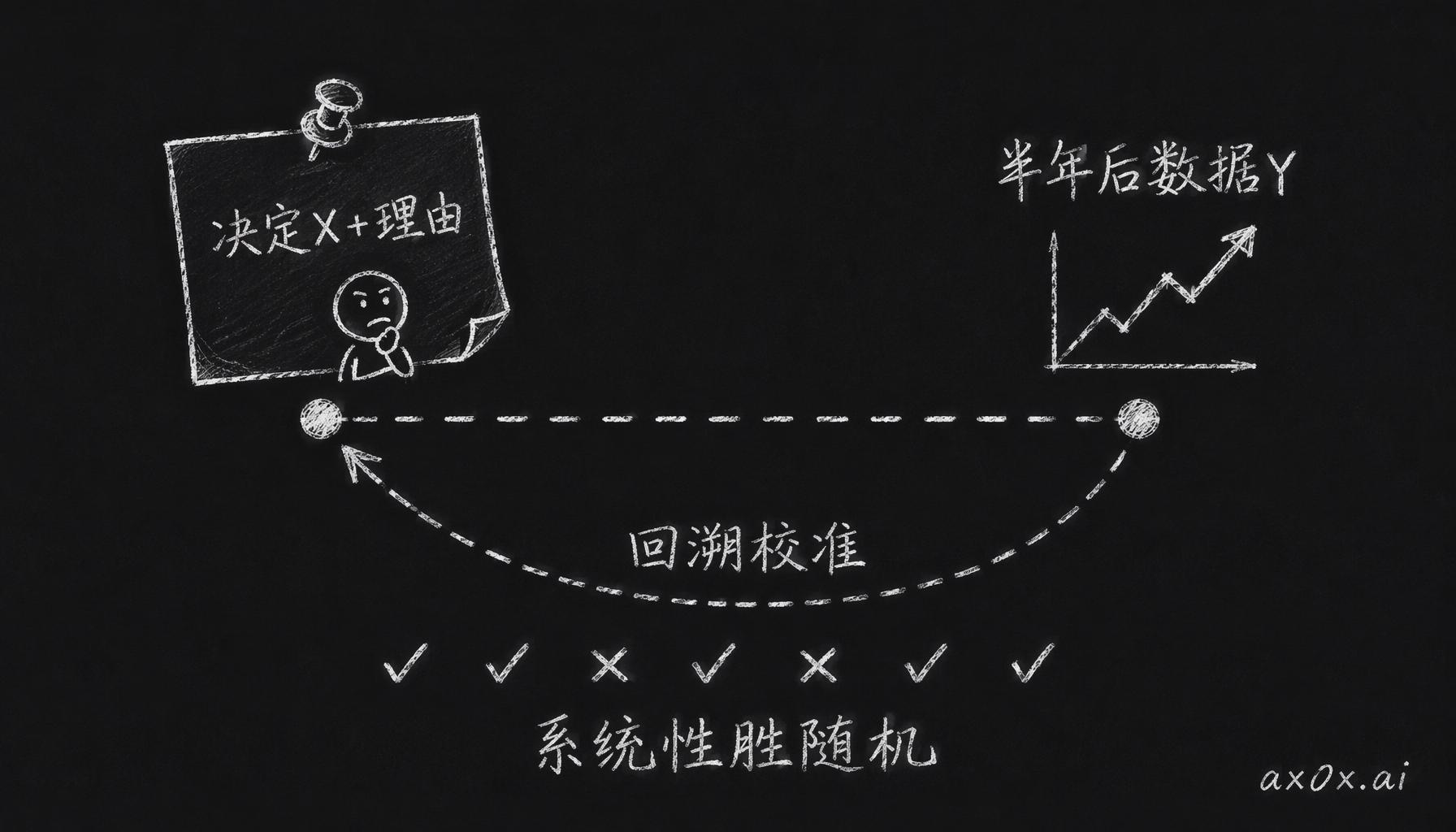 回溯校准——决策连理由一起记录,半年后用数据回头核对,看一个人在几十个决策上的判断是否系统性强于随机。
回溯校准——决策连理由一起记录,半年后用数据回头核对,看一个人在几十个决策上的判断是否系统性强于随机。
这一页是整份手册最难写的,说实话今天也还没人写出来过。这个问题现在没有好答案,我上面说的组合评估、回溯校准也都只是部分解法,只能先记着、攒着,走一步看一步。
写到最后回头看,这份手册跟 MrBeast、Netflix、Duolingo 那三份的差别也清楚了,那三份教的是怎么把一份工作做好,这份要教的是怎么判断一件事值不值得做。上一篇我说给人写比给 AI 写更难,这一遍过下来,这个判断没变,甚至更确定了一点。
