488 AI Stories a Day: Why My Editorial Policy Is a Markdown File, Not a Prompt
How much AI content ships every day? Eighty-plus cs.LG papers on arXiv. Thirty-plus tweets from the seven accounts I track. A hundred-plus articles across Chinese and English tech press. Plus GitHub trending, a few dozen WeChat accounts, and r/LocalLLaMA. Yesterday my subscription list pulled 488 items.
I read about 15 of them. The remaining 473 translate to: I miss three stories I should have seen, and burn time on ten that don't matter.
Two months ago I stopped relying on willpower. I built something called AX Radar. 488 in, ~15 out. The 473 in between get filtered by an editorial policy written in Markdown.
Live: news.ax0x.ai. Source: github.com/xingfanxia/newsroom.
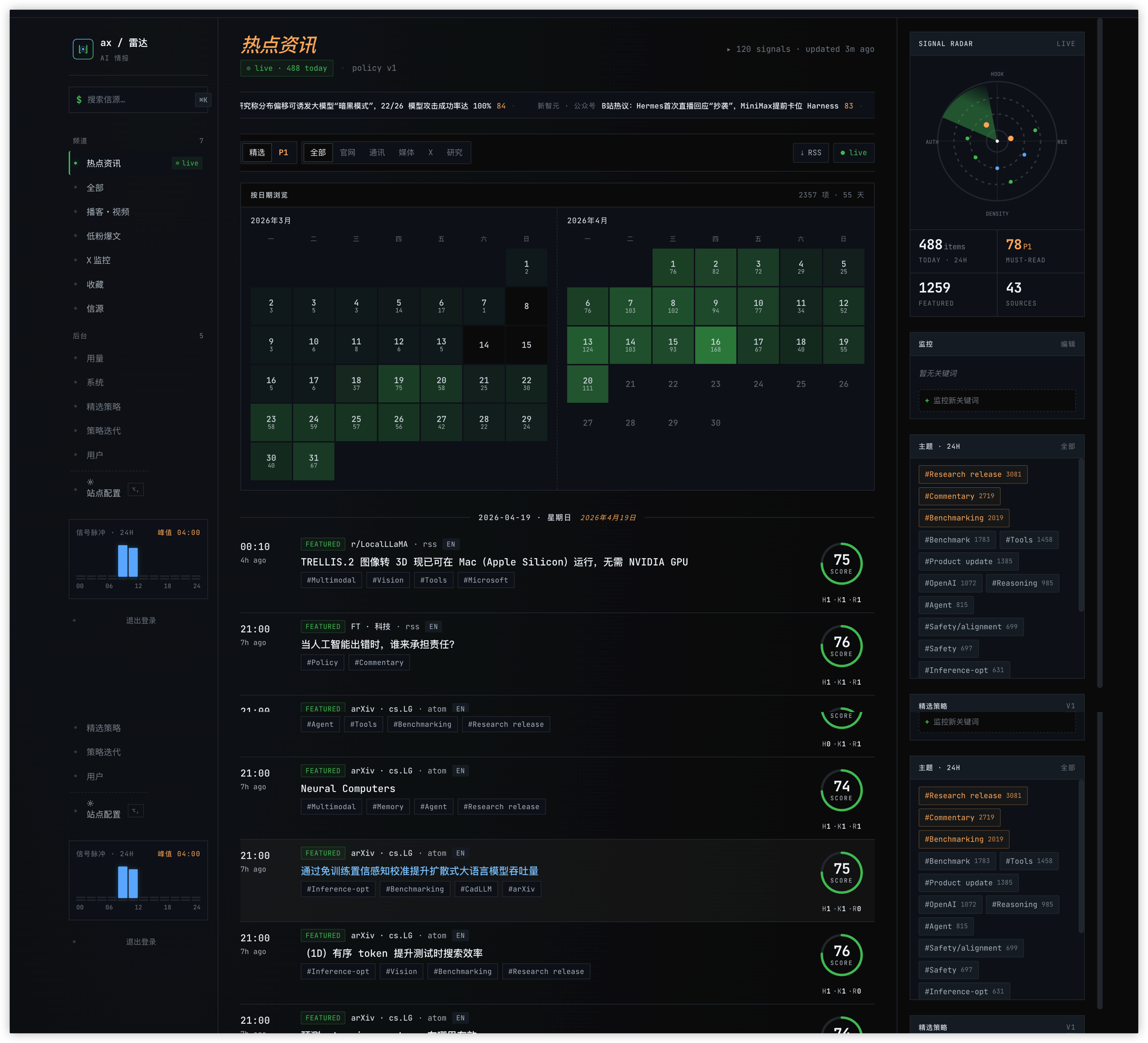 AX Radar main feed: HKR rings, calendar heatmap, right-rail topic cluster
AX Radar main feed: HKR rings, calendar heatmap, right-rail topic cluster
Aggregators Aren't the Answer. Filters Are.
Hot feeds, AI Weekly, various Telegram channels — I've tried all of them. They do the same thing: aggregate other people's tastes into "mainstream taste", then push that back at me.
The deeper problem: in AI, there is no mainstream.
I care about model internals (architecture, inference optimization, data strategy) and agent product design. Aggregators surface marketing announcements, funding rounds, and founder one-liners. Open any "Today's AI Hot List" and it's either OpenAI shipping a consumer feature or another company closing a round. The signals I actually want — a small arXiv paper reframing an idea, a tweet leaking internal practice — don't rank on trending.
So aggregators solve dedup and ranking. The missing piece is filtering and scoring. The first runs on traffic; the second runs on explicit editorial judgment.
Can that judgment be outsourced to popularity-weighted scoring? No. Popularity weighting surfaces mainstream taste. I want mine.
488 In, 15 Out: What the Pipeline Looks Like
The radar has four stages. Each runs independently, each caches separately.
- Fetcher: 50 sources, pulled by cadence buckets (hourly / daily / weekly). RSS, Atom, RSSHub (which covers WeChat accounts, 36Kr, Huxiu, Bilibili), arXiv native API, X API v2, plus some scraping fallback. Each item dedupes on
(source_id, external_id); raw HTML goes intoraw_items. - Normalizer: clean HTML, extract author, parse timestamps, resolve canonical URL (strip UTM, follow redirects). Output: clean
itemsrows. - Enricher: parallel LLM calls produce Chinese + English summaries, three-axis tags (capability / entity / topic), and a 3072-dim embedding. Model is Azure OpenAI gpt-5.4 standard.
- Scorer: a second LLM pass reads the current editorial policy (more on that in a minute) and scores each item 0–100, bucketed into
featured/all/P1/excluded.
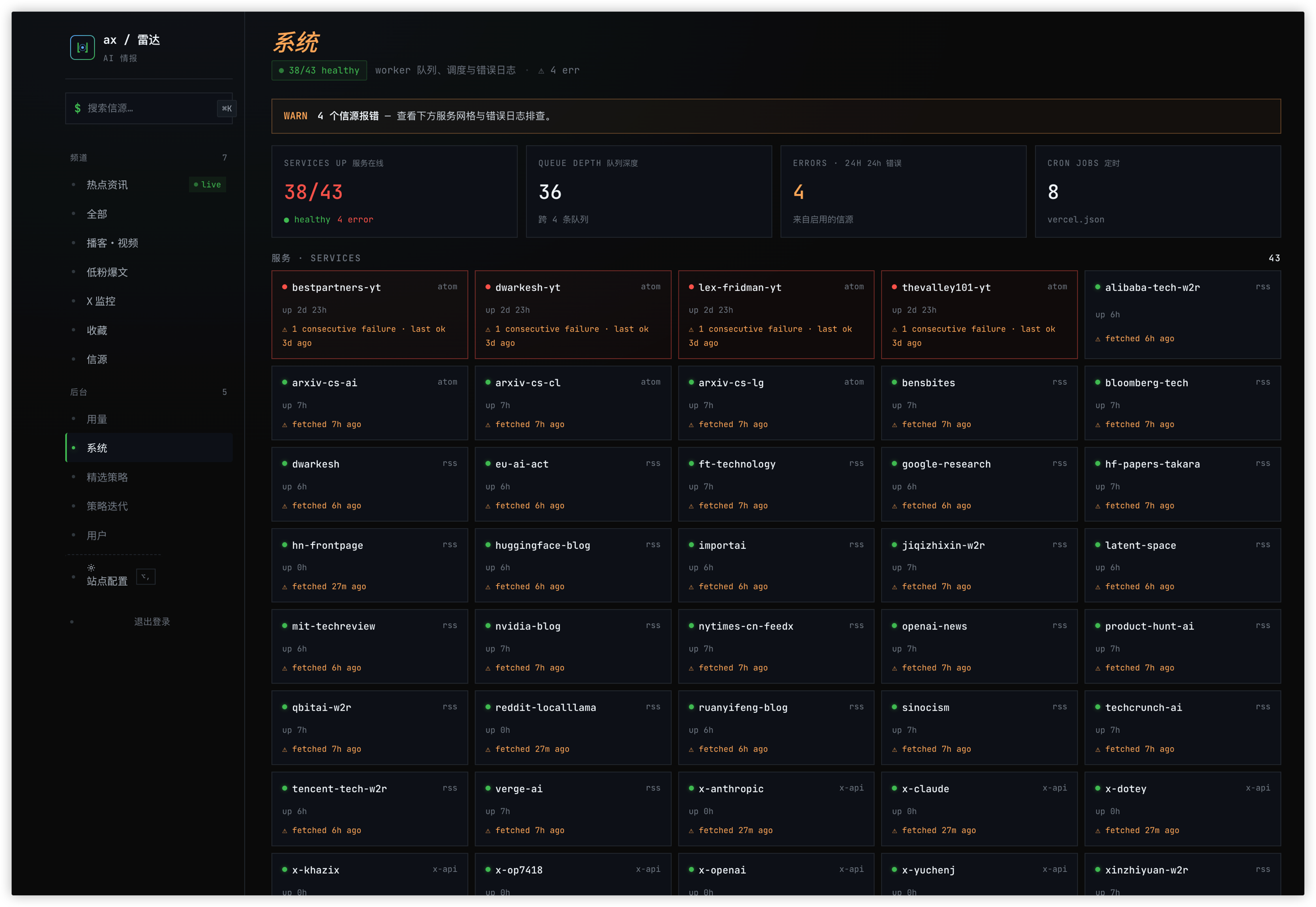 System page: 43 source services with uptime, queue depth, and error logs
System page: 43 source services with uptime, queue depth, and error logs
Each stage writes to its own table and caches by (item_id, version). An item enriched once doesn't re-enrich; a policy change re-scores but doesn't re-enrich. That cost separation is what makes the whole system viable at single-operator budget.
Over the last thirty days: ~68,000 LLM calls, total cost in the low three figures USD. For a solo project, that's comfortable.
Cost structure worth noting: enrich is the biggest line item (about half), score is second (about a third), and commentary, embed, and newsletter together stay under a fifth. Embed volume looks big, but the dollar cost is trivial — text-embedding-3-large runs two orders of magnitude cheaper than text generation.
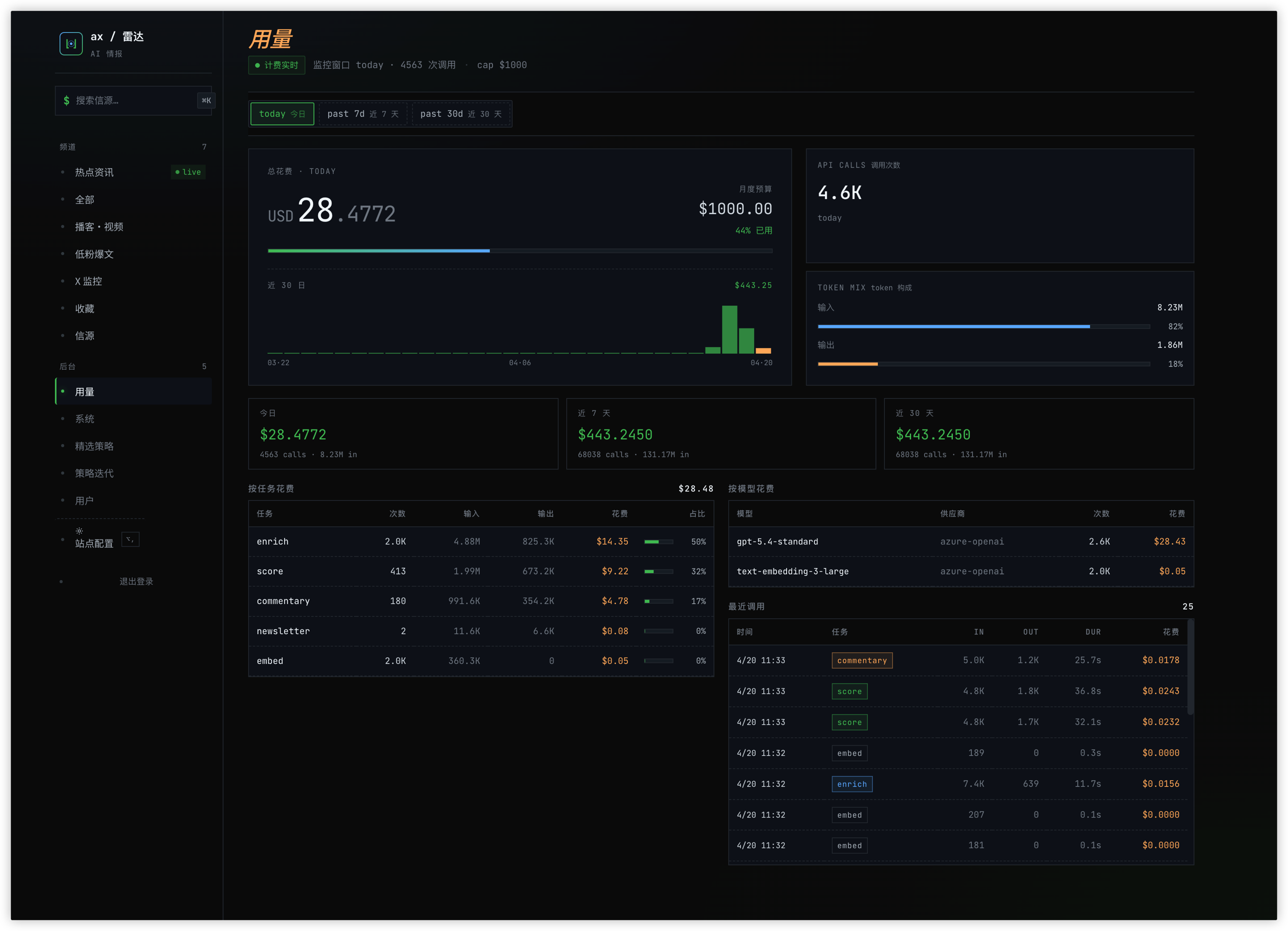 Usage page: today's spend, monthly cap, cost breakdown by task and by model
Usage page: today's spend, monthly cap, cost breakdown by task and by model
The Key Call: The Editorial Policy Must Be Human-Readable
The standard way to build an AI news filter is to bake the rules into the Scorer's prompt. Most open-source projects do it this way.
Three problems with that:
- Prompts are black boxes. You change them, but you can't say exactly what changed.
- Prompts aren't diff-able. You can't compare v2 to v1 line by line.
- Prompts are one-off. Change teams, change projects, change models — your tuning experience evaporates.
The radar goes a different way: the editorial policy is a 600-line Markdown file called editorial.skill.md. It spells out:
- Role: your reader is an industry-literate professional; don't explain "ChatGPT is OpenAI's AI tool."
- The HKR scoring rubric (next section).
- What each score band from 0 to 100 represents, with concrete examples (95–100 is "every outlet is covering this tomorrow"; 85–94 is "must write today").
- Six hard exclusion rules: technical difficulty without an on-ramp, cloud-vendor promo, stale rerun, science-plus-AI with no agent or product angle, pure marketing, zero-sourcing opinion.
- Positive signal bumps (+3 to +5): substantive Anthropic update, Chinese flagship model release, cross-source cluster detected, first-person experiment with numbers, paper with a reproducible practical claim.
Every change writes a new row to policy_versions. The worker reads the current version on the next scoring pass. Rolling back is one SQL update.
Why this choice matters: it splits editorial judgment from scoring execution. Judgment is human work — I can read the file, edit it, argue about it with peers. Scoring is the model's work — it reads the Markdown and applies the rules. Both sides iterate independently.
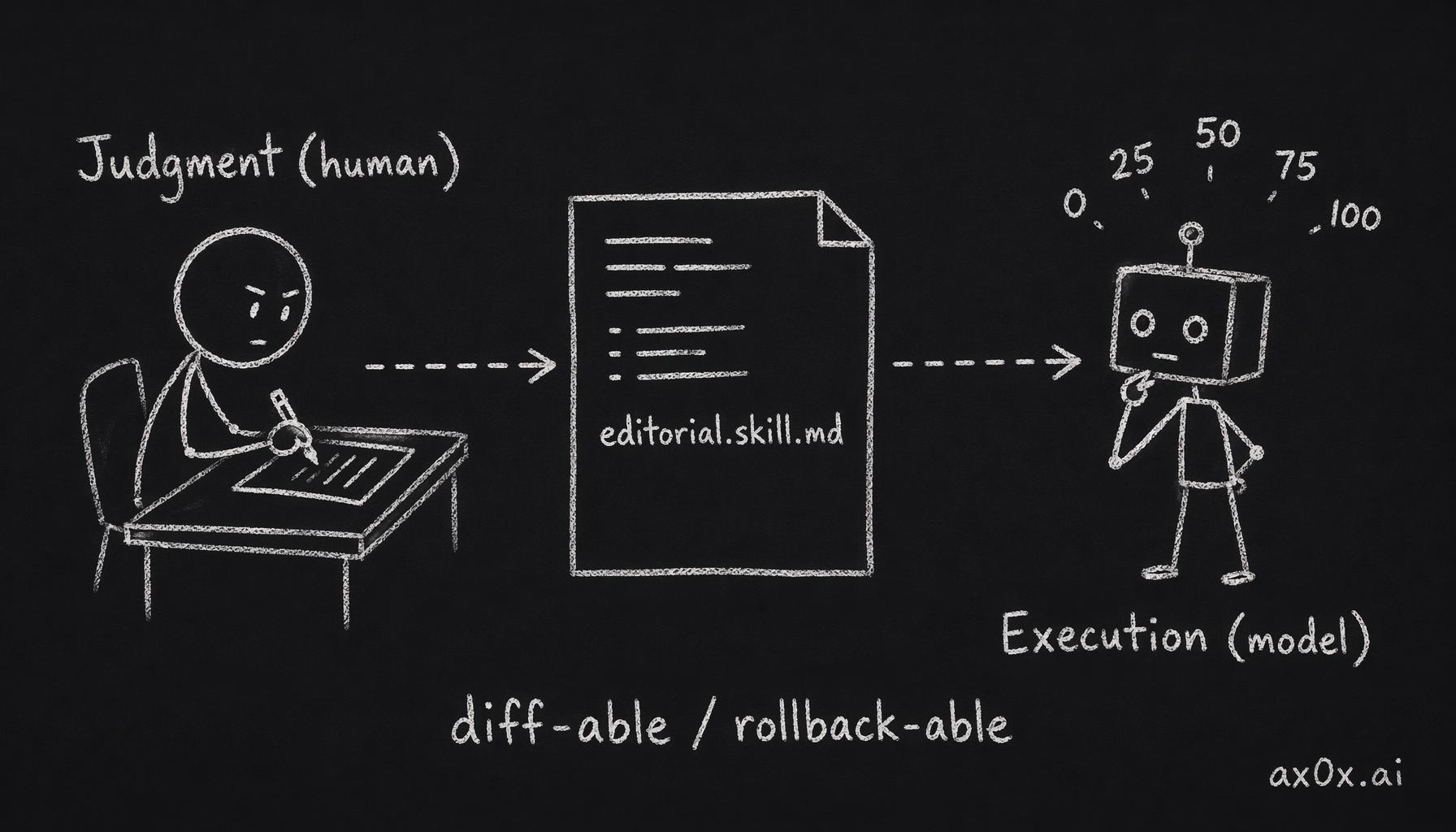 Editorial judgment lives in a human-readable Markdown file that a person edits, while the model just reads it and scores — the two sides iterate independently
Editorial judgment lives in a human-readable Markdown file that a person edits, while the model just reads it and scores — the two sides iterate independently
This is the one design decision in the project I'd keep no matter what else changed. Swap the database, swap the models, swap the frontend — the system survives. But if the policy were a prompt instead of a Markdown file, it would become untouchable after three months.
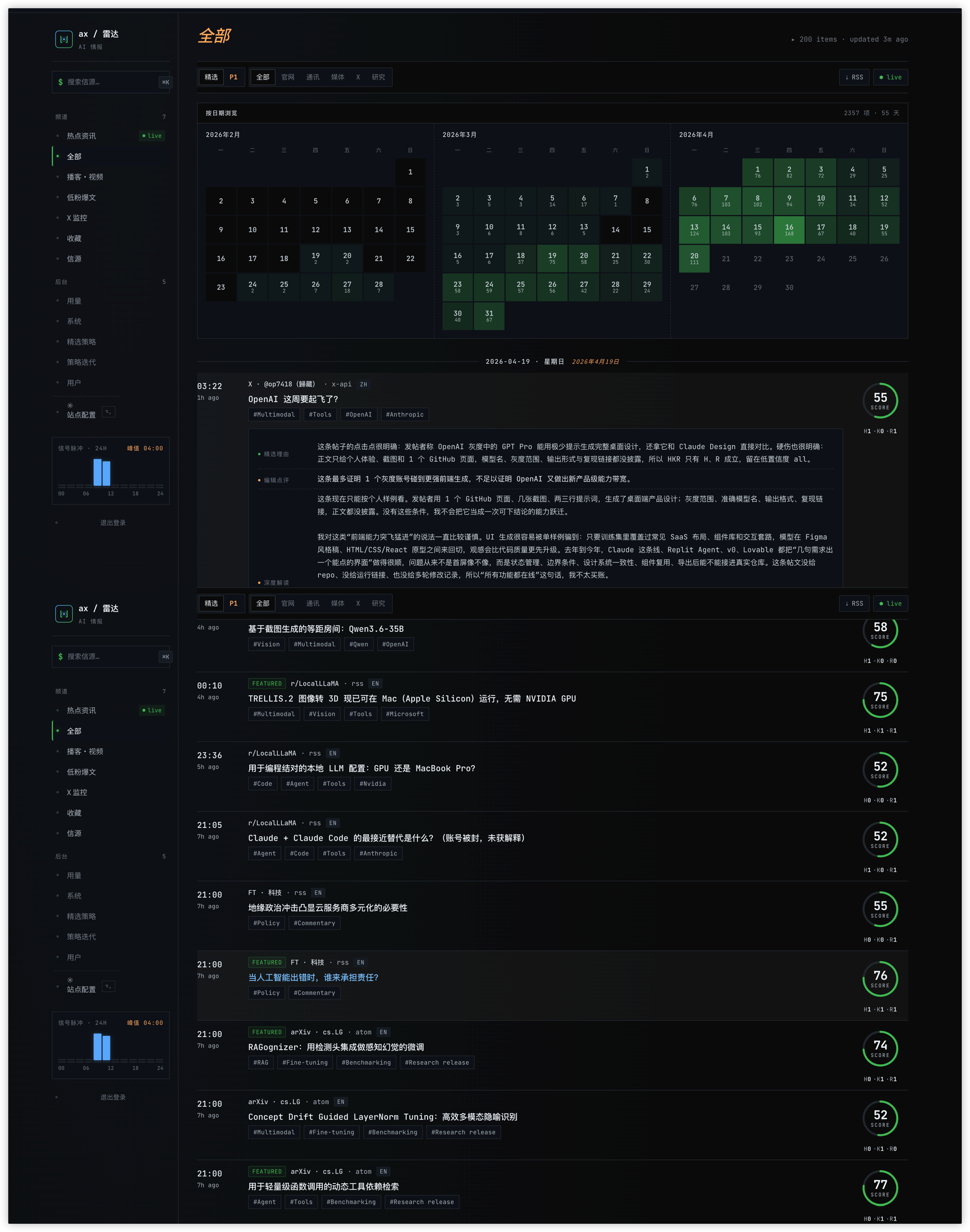 An all-feed X post with three-layer annotation: why-featured, editor's take, deep analysis
An all-feed X post with three-layer annotation: why-featured, editor's take, deep analysis
HKR: Scoring News Like You'd Score an Essay
The traditional approach is a single "importance" dimension. The problem is "importance" is too vague — important to whom, in what sense?
I borrowed the HKR framework (Hook / Knowledge / Resonance) from Khazix's essay-writing skill and ported it to news filtering:
- H — Hook: does the headline or angle make you want to click? Is there suspense, a twist, an angle you haven't seen? Marketing-speak doesn't count as a hook.
- K — Knowledge: after reading, do you walk away with a new number, a new mechanism, a new claim worth testing?
- R — Resonance: does it hit an identity nerve? Would the reader forward it to a peer?
Tiering rules:
- Featured: at least 2 of 3 axes hit.
- P1: all 3 hit, score ≥ 85.
- All: at least 1 of 3 hit.
- Excluded: 0 of 3, or any hard exclusion triggers.
The big win is that the judgment path is explainable. Open a featured story and see H ✓ K ✓ R ✗ in the sidebar — I immediately know this is a hook-plus-knowledge research piece that won't travel socially. Open a filtered-out story showing H ✗ K ✗ R ✗ and I don't need to dig into a prompt to guess why.
Knowledge-without-hook stories sink into the "all" list rather than hitting the front page. Hook-without-knowledge pieces get excluded outright — that's clickbait. All-three stories pin at the top. That tiering logic lives in the policy file and stabilizes within a week of feedback.
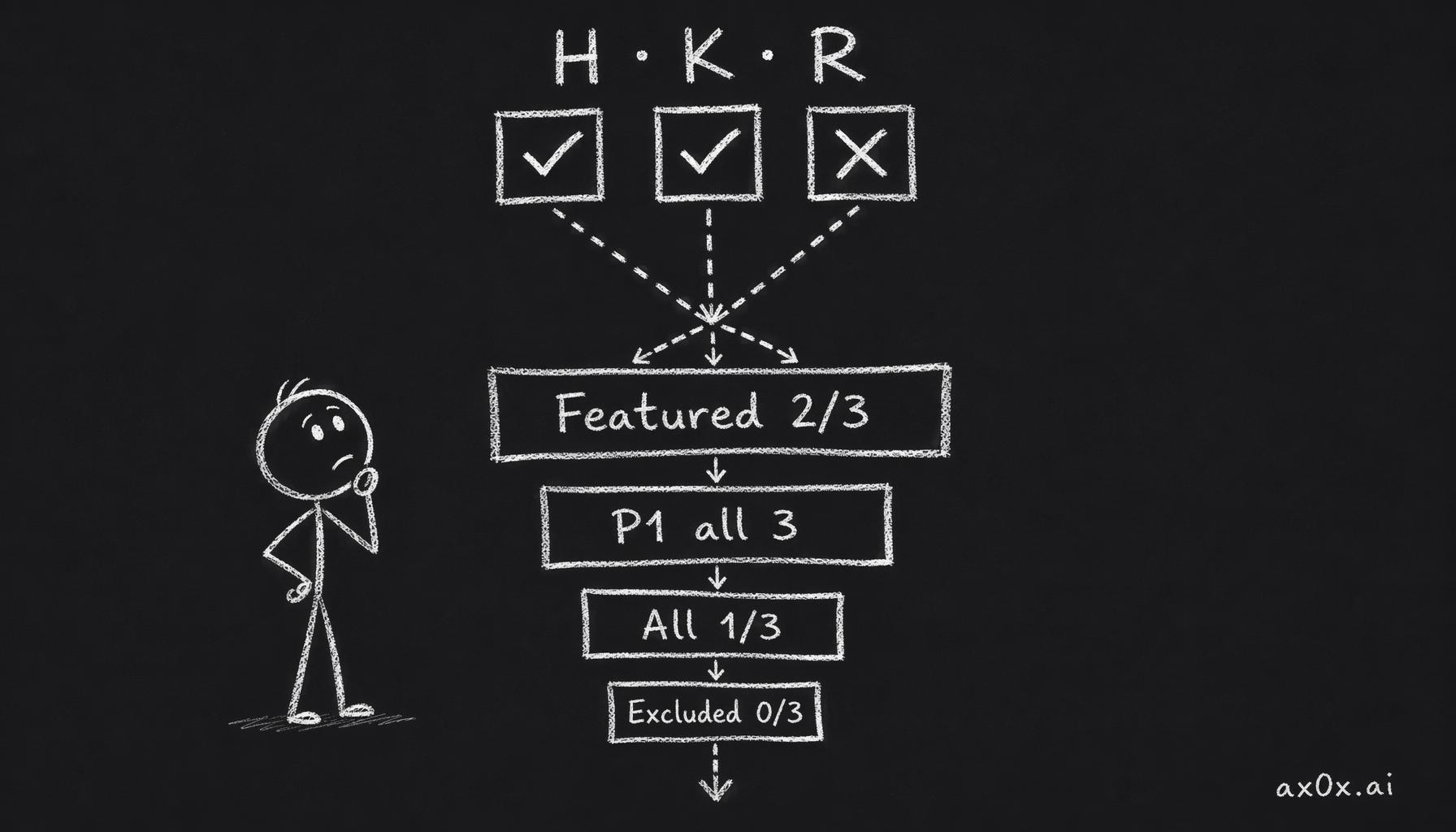 Each of the three axes H, K, R hits or misses, and how many hit decides which of four tiers — featured, P1, all, excluded — a story lands in
Each of the three axes H, K, R hits or misses, and how many hit decides which of four tiers — featured, P1, all, excluded — a story lands in
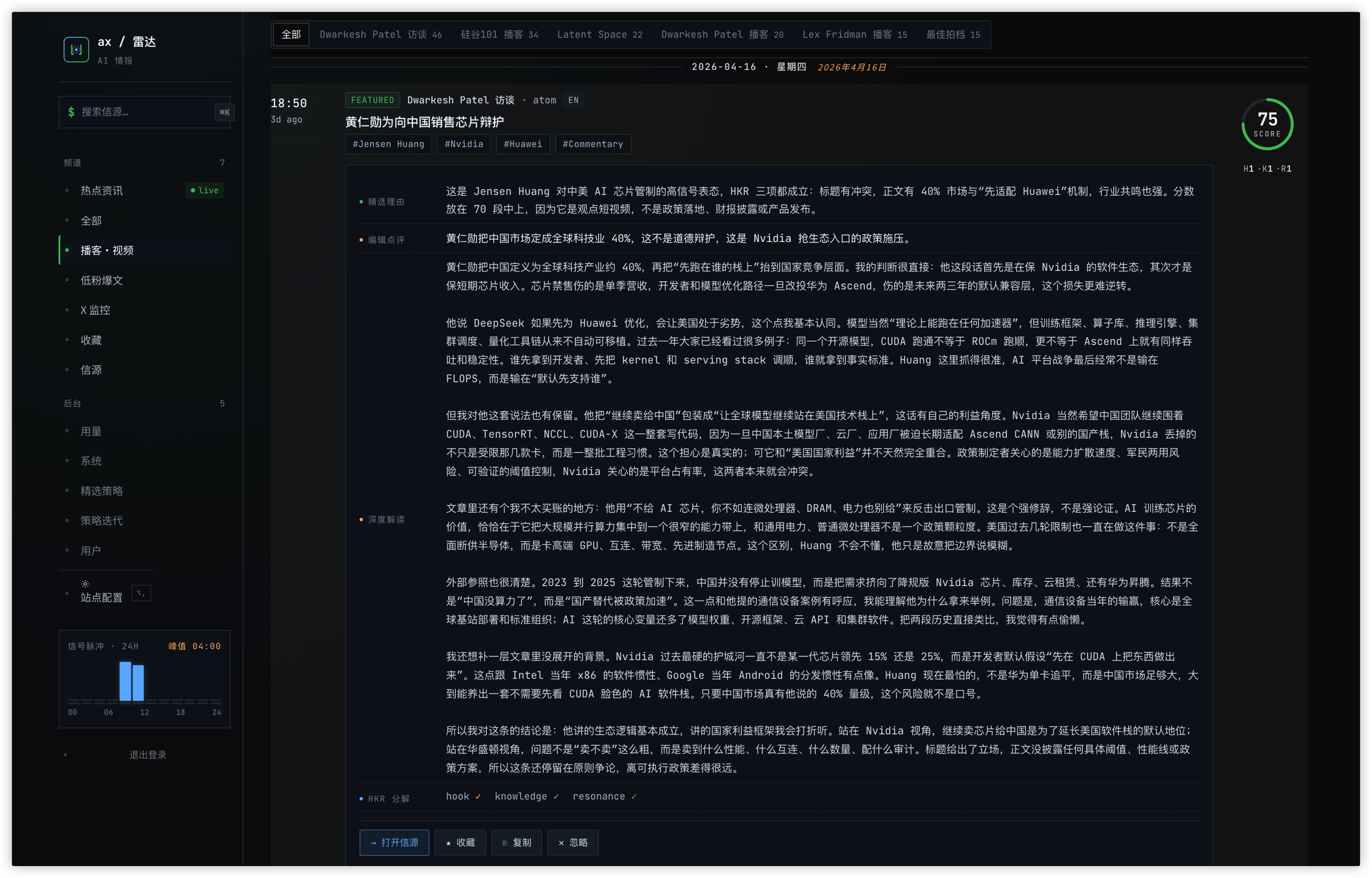 A Dwarkesh podcast item with full HKR axis breakdown and deep commentary
A Dwarkesh podcast item with full HKR axis breakdown and deep commentary
The Agent Edits the Policy, Not the News
The radar's admin panel has a page called "Policy Iteration." The workflow:
- I scroll the main feed and react — thumbs up, thumbs down, star, sometimes with a one-line note.
- When I've accumulated a batch (50-ish reactions over a week), I hit "Policy Iteration" and click
Generate Draft. - A Claude Agent session starts with three tools: read current policy, read a feedback sample, write a new draft.
- The system prompt constrains it: read the policy + read feedback + propose minimal changes + explicitly list "what I did NOT change, and why." The last part exists to stop the agent from overfitting to recent feedback and breaking general rules.
- The UI renders the diff in monospace. Green additions, red deletions, threshold tweaks, new exclusion rules. I click
Applyif it looks right. - The new version writes to
policy_versions. The next Scorer cron picks it up automatically.
Two design points worth calling out.
The agent is a deputy editor, not the editor-in-chief. It doesn't decide the policy. It reads the current policy, reads feedback, and proposes revisions. Final approval stays with me. This separation is critical for AI-assisted workflows — the moment you let an agent directly modify production-facing policy, debugging cost explodes.
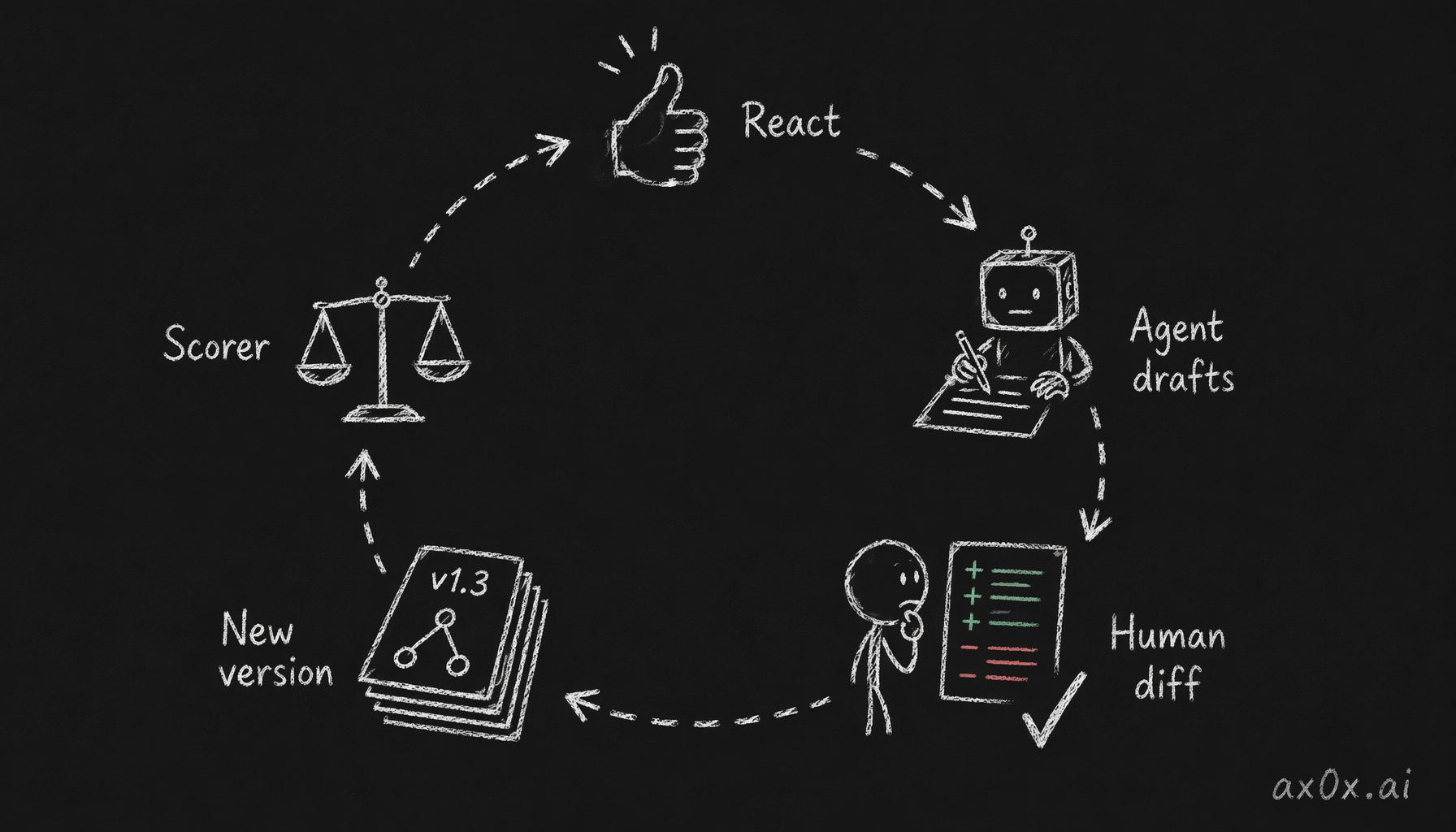 Reactions become feedback, the agent drafts a new policy, the human reviews the diff and applies it as a new version, the scorer uses it — a closed loop where final approval always stays with the human
Reactions become feedback, the agent drafts a new policy, the human reviews the diff and applies it as a new version, the scorer uses it — a closed loop where final approval always stays with the human
Policies have versions and parent relationships. policy_versions stores parent_version — v7 descends from v6, not from scratch. This gives the policy a genealogy. When something regresses, you can trace which generation introduced the drift. Same logic as a Git commit tree, just at policy-file granularity instead of code.
Three Things I Haven't Solved
Low-follower viral detection isn't wired up yet. X's search/all endpoint can reverse-query by follower threshold (author <50k followers + engagement rate above X), but I'm blocked on API tier quota. Zhihu, Jike, and Xiaohongshu have unstable data APIs; the scraping fallback is in progress. When this ships it'll be very useful — the real early signals in AI often come from 3k-follower engineers, not 300k-follower influencers.
Cross-source clustering UI isn't fully connected. The backend already runs a 0.88 cosine-distance near-dup merge over a 48-hour window. A story reported by five outlets should collapse to one row with an "also reported by N sources" chip. The frontend chip isn't hooked up yet, so users still see same-event duplicates on the front page sometimes.
Score calibration drifts on model swaps. I swapped the Scorer model once (early it was Claude Haiku, now GPT-5.4 standard), and the 0–100 distribution shifted immediately — same policy, same stories, mean score off by 5 points between models. A model swap requires recalibrating the entire score band. This is the pit most similar projects will fall into.
Tail
I've been running the radar for two months. Reading news feels inverted now — before, I scanned everything, worried about missing things. Now I read ~15 curated items and stay confident I didn't miss what mattered.
But the deeper lesson isn't filtering. It's treating editorial judgment as a versioned artifact.
Before, I ran on gut feel. "This is interesting" — forward it. "This is noise" — skip. Gut feel is un-diffable and unsharable. Now I have a 600-line Markdown file spelling out exactly why I click, exactly why I skip, which rules are hard and which are nudges. When I discuss taste with peers, I don't cite examples. I send a commit diff.
This "crystallize intuition into a file" pattern will spread. A PM's taste, a designer's judgment, an editor's nose — none of it is magic. All of it is a versionable policy file. The radar is a news filter, but filtering news and building products aren't really different: judgment should always be readable, editable, rollback-able.