AX Radar Needed a Second Face. One for Agents.
Part 1 walked through AX Radar from my side (read it here). At that point it had exactly one face: a web dashboard at news.ax0x.ai where I'd scan the feed, click into items, and save anything worth returning to.
The problem: Claude couldn't see that face.
I'd ask Claude Code "what's on the radar worth reading today?" and it'd shrug and ask for a screenshot. The model had no access to my subscription list, my curated 15, or the editorial commentary. As far as any LLM was concerned, the radar didn't exist.
This week I gave it a second face: an HTTP API, an MCP server, and a Claude Code skill. Now I type "brief me on this week's radar" and Claude Code pulls 30 featured items, groups them by source, cites the editor's analysis. No glue code, no screenshots.
Ship stats:
- 2 commits, ~1,600 LOC, 20 files touched
- 14 integration tests hitting real Postgres (synthetic
Requestobjects into route handlers — no HTTP server, no curl, no mocks) - 8 REST endpoints + 7 MCP tools + 1 resource
- Covering 6,821 enriched items, 59 sources, $443 across 68k LLM calls over 30 days
1. Two Faces, One Backend
The one thing I didn't do: build two backends. The HTTP API and the MCP server share the same SQL query layer.
Why ship both? Because they solve different integration costs.
HTTP API (/api/v1/*) is the fallback. OpenAI function calling, Gemini tools, n8n, LangChain — any agent runtime that speaks REST can hit it. MCP isn't universally supported yet, so HTTP API is the long-tail guarantee.
MCP server (/api/mcp) is the fast lane. Claude Desktop, Cursor, and the claude CLI auto-discover MCP servers. Paste one JSON block into claude_desktop_config.json and the tools show up — no SDK install, no glue code, no middleware.
Ship only the HTTP API and every Claude Desktop user has to hand-write a function wrapper. Ship only MCP and n8n users are out. So both.
The MCP layer is a thin adapter. It doesn't reimplement business logic. It calls the same query layer the REST routes call. Change the scoring policy, add a field, re-tune the cluster threshold — both surfaces see it at once. You never end up with v3 on one face and v2 on the other.
Two thin shims beat one monolithic integration.
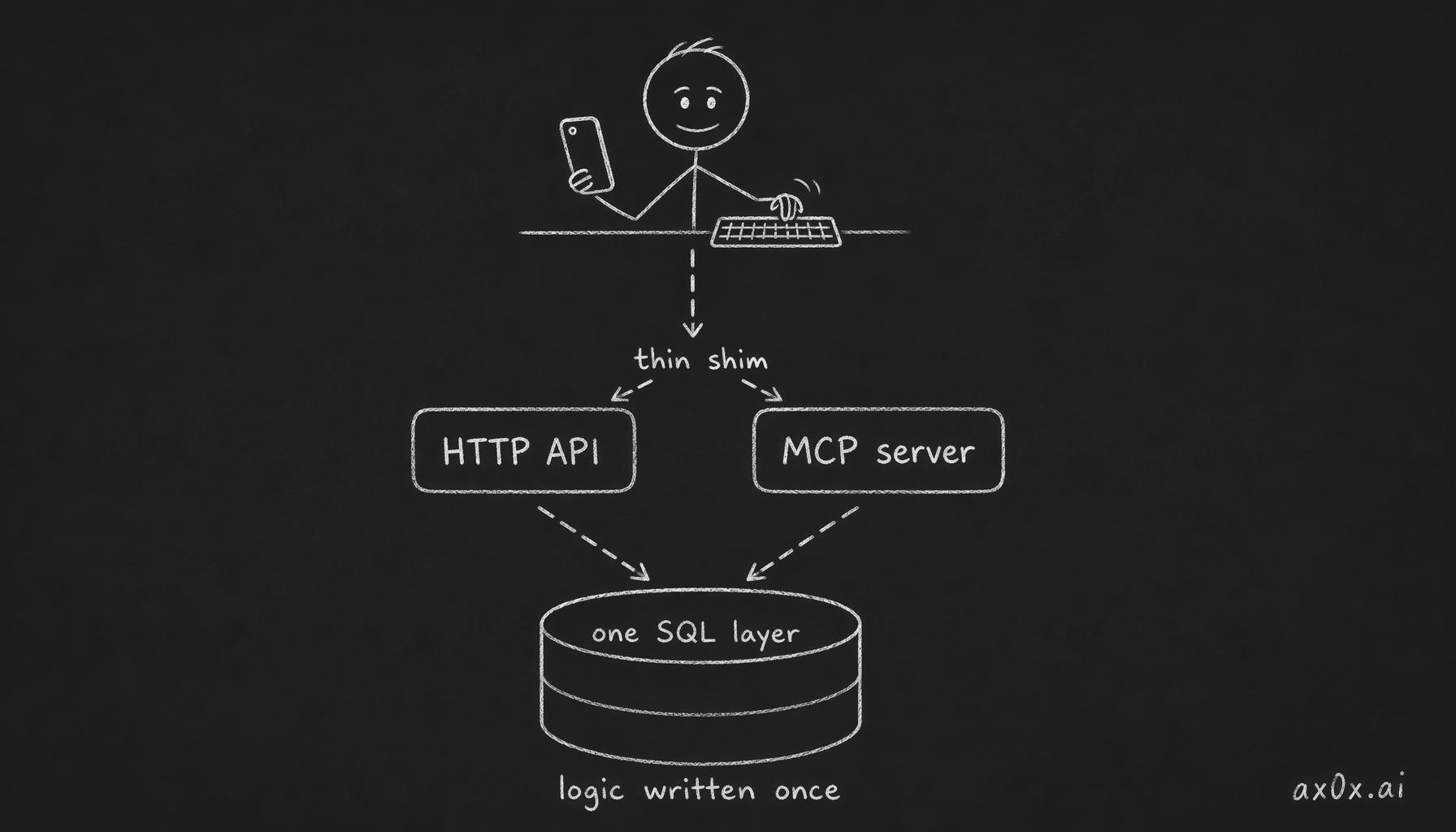 Two thin shells (HTTP API + MCP) sit over one SQL query layer, so business logic is written once and both surfaces stay in sync
Two thin shells (HTTP API + MCP) sit over one SQL query layer, so business logic is written once and both surfaces stay in sync
2. sha256, Not Bcrypt — Because Tokens Aren't Passwords
Auth uses Bearer tokens. Each token is 32 random bytes from crypto.randomBytes (256 bits of entropy). The database stores only the sha256 hash — never the plaintext.
The reflex when storing anything token-shaped is bcrypt. That reflex is wrong here.
Bcrypt is for low-entropy passwords. User passwords often carry 30–40 bits of entropy ("password123", "qwerty"). Bcrypt's deliberate slowness is the only thing that makes offline brute-force infeasible against a stolen hash dump.
API tokens carry 256 bits. You can't brute-force the heat death of the universe.
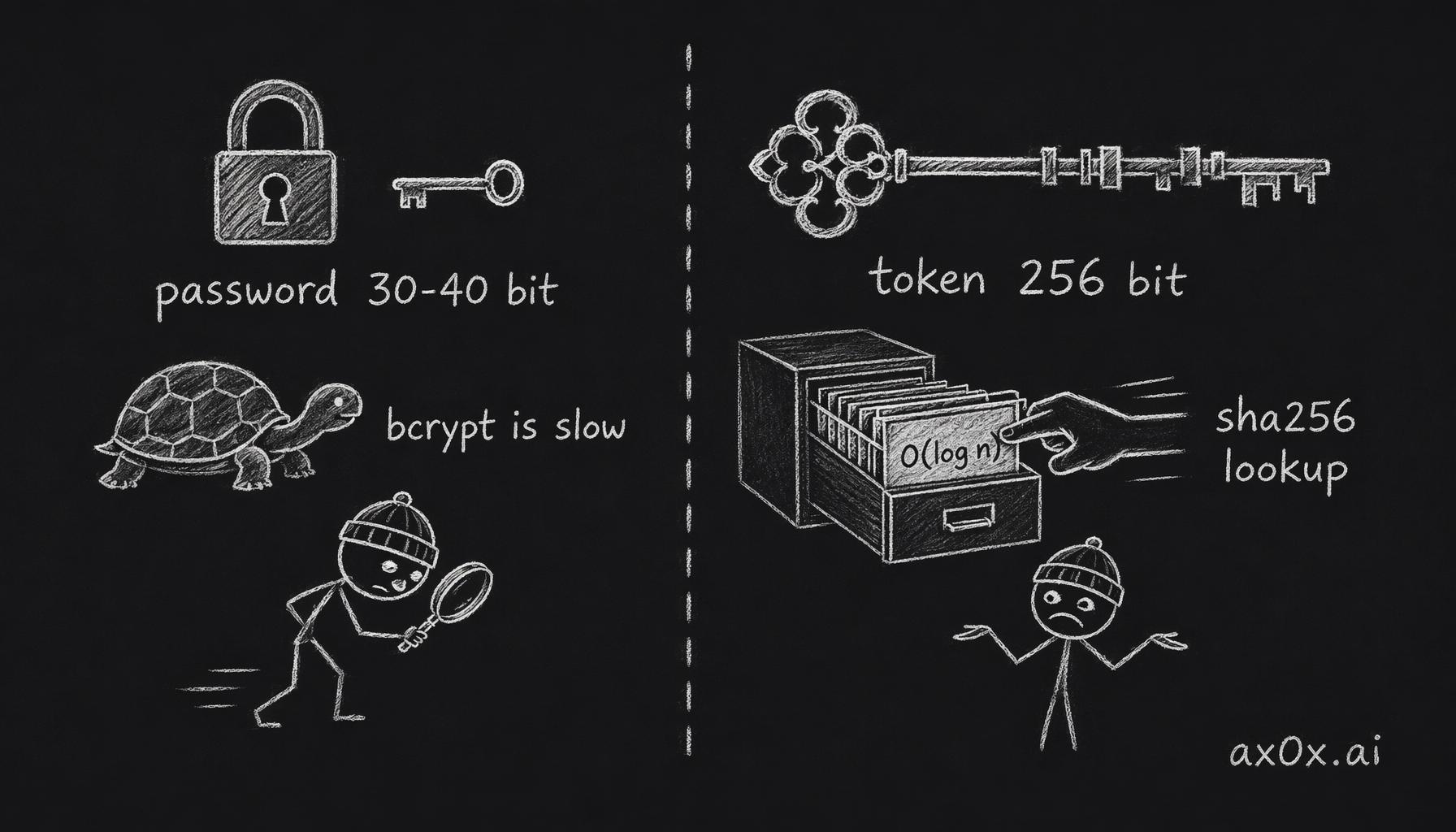 Low-entropy passwords need bcrypt's deliberate slowness to resist brute force; high-entropy random tokens can't be brute-forced, so sha256 plus an index gives O(log n) lookup
Low-entropy passwords need bcrypt's deliberate slowness to resist brute force; high-entropy random tokens can't be brute-forced, so sha256 plus an index gives O(log n) lookup
With sha256 + a unique index, per-request lookup is O(log n): SELECT * FROM api_tokens WHERE token_hash = \$1, one btree hop. Switch to bcrypt and the same lookup becomes a full-table scan with per-row comparison. The first time QPS spikes, that table melts.
sha256 is correct for high-entropy tokens the same way bcrypt is correct for low-entropy passwords. They're not substitutes. They solve different problems.
3. Semantic Search Rode Existing Infrastructure
When I started on the API, I braced for the hard part: semantic search. Do I add a vector DB? Spin up Pinecone? Tune HNSW parameters?
None of that. The M2 ship already had text-embedding-3-large 3072-dim vectors stored in halfvec(3072) with an HNSW index. Original purpose: cross-source dedup clustering — merging "same event, five outlets" into one row.
Exposing it for search was: embed the query the same way, then ORDER BY embedding <#> \$q. Negative inner product ranks identically to cosine distance on unit vectors, and skips the renormalization step.
About 24 lines of SQL, one embed() call per query. p50 latency: ~250ms end-to-end. Most of that is the embedding call (~150ms); the SQL runs in ~80ms. Cost: $0.00002 per query.
The lesson isn't specific to search: if the infrastructure you ship early is designed generically, later features cost 24 lines of SQL. HNSW had been sitting in the database since M2, serving dedup. Search rode the existing rails — no new build-out.
4. MCP Tells the Agent Tools Exist. The Skill Tells It When to Use Them.
MCP exports tool signatures: name, params, return shape. It doesn't export semantics.
Claude calls ax_radar_feed and gets importance: 72 back. Is 72 high or low? What does HKR mean? When do you use lexical vs semantic search? Which sources carry editorial commentary? None of that is in the protocol. Those are operator decisions, and they live in a Claude Code skill at ~/.claude/skills/ax-radar/SKILL.md.
The skill's description field is tuned for specific trigger phrases: "brief me on the radar", "save this for me", "search the radar for X". Match one and the skill auto-loads into context before any tool call. The skill body is pure domain knowledge:
- What HKR's three axes mean; featured vs P1 thresholds
- When to use semantic vs lexical search (gist vs exact-string)
- Guardrails: don't blast the feed into the transcript; don't save items speculatively;
ax_radar_saverequires explicit operator intent; YouTube sources never scoreexcluded(an operator policy) - Config snippets for three MCP clients (Claude Desktop, Cursor,
claudeCLI)
Skills are the most under-appreciated layer in agent tool design. MCP is the pipe. The skill is the manual. Without the manual, the agent uses the pipe like a kid with a wrench — the tool is there, but they're hitting the wrong things.
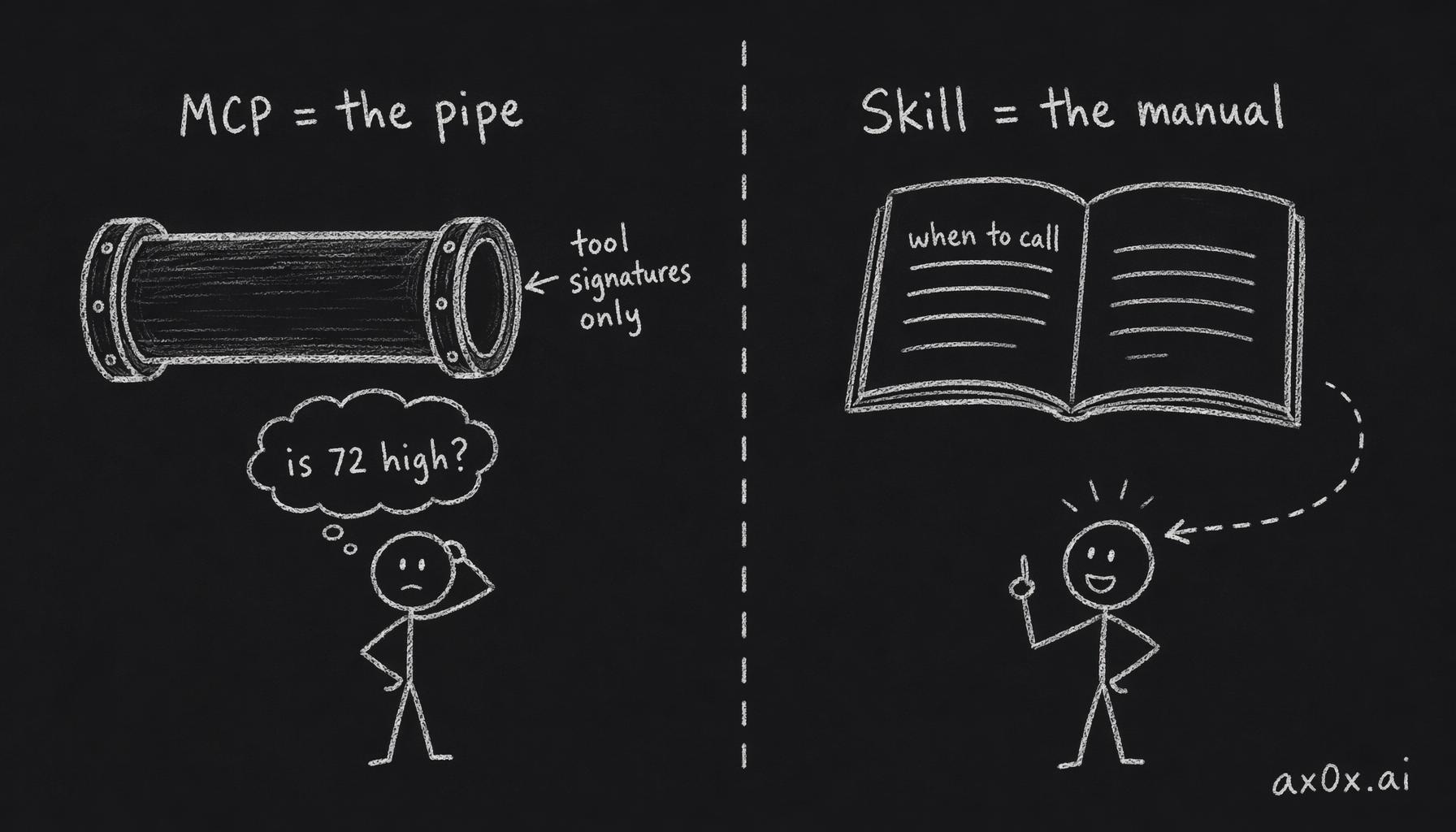 MCP only exports tool signatures (the pipe); the skill carries the domain knowledge that tells the agent when to call and how to read results (the manual)
MCP only exports tool signatures (the pipe); the skill carries the domain knowledge that tells the agent when to call and how to read results (the manual)
5. What "Brief Me on This Week's Radar" Actually Does
User side: one sentence in Claude Code.
System side:
- Claude Code's skill loader scans skill descriptions, matches "brief me on the radar" against the ax-radar skill, loads the skill into context.
- Skill content tells Claude: for "what's happening this week" questions use
ax_radar_feed; prefer the markdown resourceax-radar://todayover raw JSON for briefings; group by source; flag items withhas_commentary: true. - Claude calls
tools/call ax_radar_feed {tier: "featured", limit: 30}through the MCP endpoint. - MCP server verifies the Bearer token (sha256 lookup, ~5ms), runs
getFeaturedStoriesagainst Postgres, returns 30 items as JSON. - Claude calls
resources/read ax-radar://todayfor the pre-formatted markdown briefing. - Claude structures its response using the markdown skeleton, citing
item_idandeditor_analysisfields.
End-to-end: a few seconds. I typed one sentence. This path didn't exist a week ago.
6. What's Not Shipped
No webhook push yet. The agent pulls on demand — I ask, it queries. Push ("new P1 item, alert me") is a v2 item, not today.
No multi-user scoping. One Bearer token per radar instance. Everyone sees the same editorial policy. If this goes to teams, I'll need org_id columns and row-level policies.
No agent-to-agent. Conceptually the pipeline is: one agent scrapes X/arXiv and feeds the radar, a second agent consumes the radar and drafts my morning digest. Only the second half exists right now.
Tail
This ship didn't build anything new. The API is a thin shim over existing SQL. The MCP server is a thin shim over the API. The skill is a thin manual sitting above MCP. The value isn't in any single layer — it's in the shape: one backend, multiple surfaces.
Most products ship one face — web or mobile — and call it done. But if your data is worth anything, it will eventually have non-human consumers: other agents, internal services, a partner's pipeline. Those consumers don't use a web UI. They want a stable contract — HTTP, MCP, gRPC, webhook — pick the ones that fit.
The back half of product-building isn't adding features. It's adding access modes. One face for humans, one for agents, maybe a third for partners. The backend stays the same.
