claude 现在能自己查我的雷达了
上一篇(第一篇)讲的是我自己怎么用 AX 雷达:每天打开 news.ax0x.ai,扫一遍首屏,点进去看深度解读。用了一阵之后发现一个问题——整个雷达只有一个网页入口,是给人看的,claude 看不见。
在 claude code 里问「今天雷达上有啥值得看」,它只能老老实实说查不到,让我截个图。也正常啊,模型手里没有我的订阅列表,也没法调出我精选的那 15 条,雷达对它来说就是不存在的东西。
所以这周给雷达加了一套 agent 能用的入口:一套 HTTP API,一个 MCP server,再加一份 claude code 的 skill。加完之后在 claude code 里打「brief 我一下这周的雷达」,它自己查到 30 条 featured,按信源分组,还引用编辑点评。中间没有胶水代码,也不用截图。
改动本身不算大,2 个 commit,大概 1600 行代码,摊到 20 个文件里,出来是 8 个 REST endpoint、7 个 MCP tool 加 1 个 resource。集成测试写了 14 个,真跑 Postgres 的那种,用 Request 对象直接打路由,不起 HTTP server。这些入口背后接的还是同一份数据:库里 6821 条已加工条目、59 个信源,30 天跑了 6.8 万次 LLM 调用。
一个后端,两层薄壳
这次没建两个后端。HTTP API 和 MCP server 共用同一层 SQL 查询,上面各包一层薄壳,这个决定我现在觉得挺对的。
为什么两个都要做啊?因为它们解决的是不同的接入成本。
HTTP API(/api/v1/*)是兜底。OpenAI 的 function calling、Gemini 的 tools、n8n、LangChain,反正任何会讲 REST 的 agent runtime 都能接。MCP 现在还没普及到所有 runtime,有个 REST 接口在,谁都能用。
MCP server(/api/mcp)是给支持 MCP 的客户端走的快路。claude desktop、cursor、claude CLI 都会自动发现 MCP——在 claude_desktop_config.json 里粘一段 JSON,工具就出现了。不装 SDK,不写胶水代码,也不用部署什么 middleware。
你只做 HTTP API 的话,claude desktop 用户每次都得自己手写一个 function wrapper;只做 MCP 的话,n8n 用户就接不上了。所以两个都做。
关键在 MCP 那层是薄壳,它不重新写业务逻辑,直接调 API 那层的 Postgres query。这样打分策略改了、字段改了、cluster 去重的阈值改了,两边跟着一起变,反正逻辑就一份。
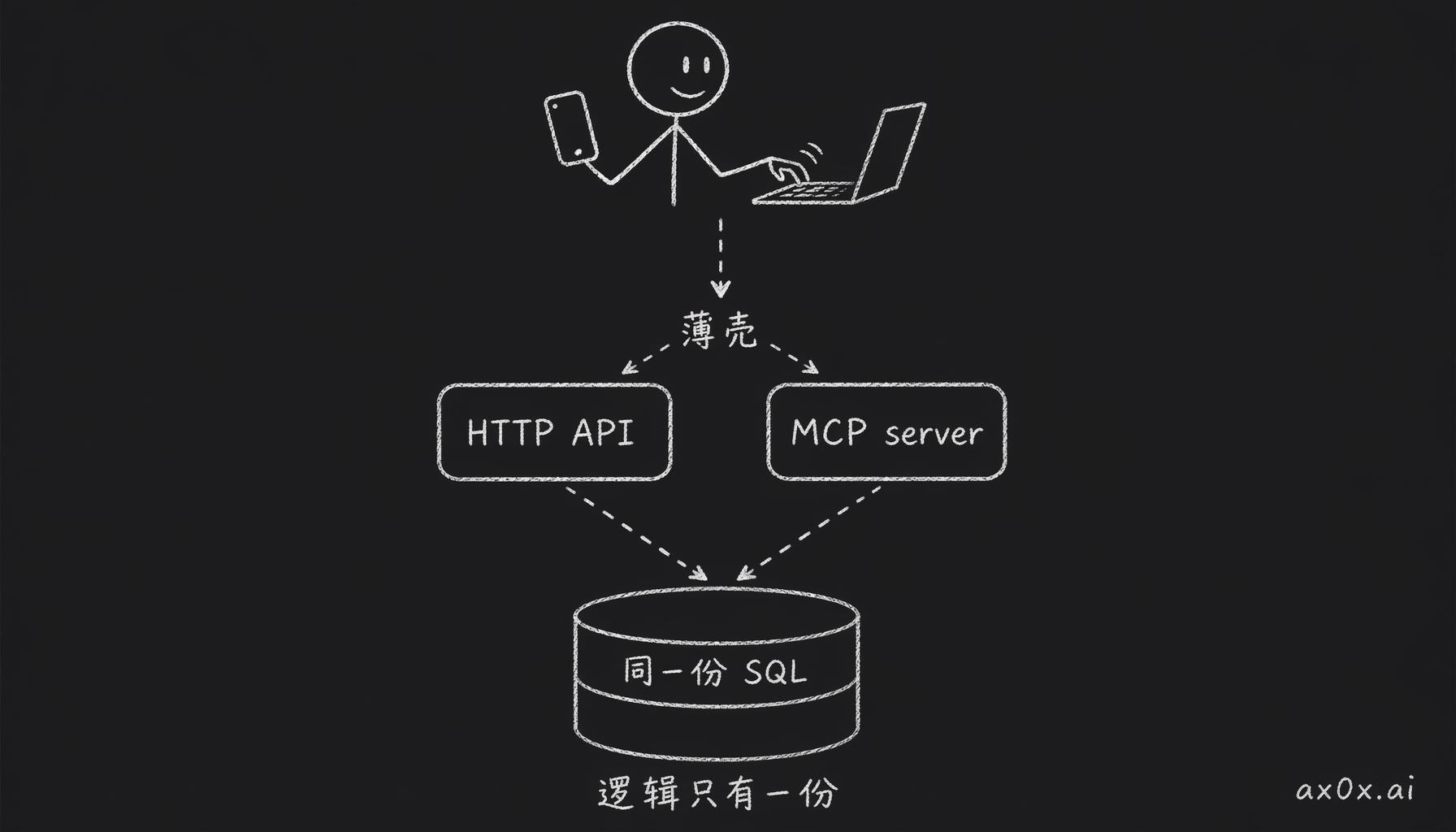 一个 SQL 查询层上包两层薄壳(HTTP API + MCP),业务逻辑只写一份,两个入口自动同步
一个 SQL 查询层上包两层薄壳(HTTP API + MCP),业务逻辑只写一份,两个入口自动同步
token 只存 sha256
鉴权用的是 Bearer token。每个 token 是 32 字节随机值(crypto.randomBytes(32),256 bit 熵),数据库里只存 sha256 哈希,不存明文。
一开始也想过要不要上 bcrypt,想了想没上,这里 bcrypt 不合适。
bcrypt 是给低熵密码用的。用户密码经常只有 30 到 40 bit 熵,「password123」「qwerty」这种,bcrypt 故意算得慢,就是为了让撞库撞不动。API token 不一样,它是 256 bit 熵的随机值,本来就撞不出来,不需要靠算得慢来保护。
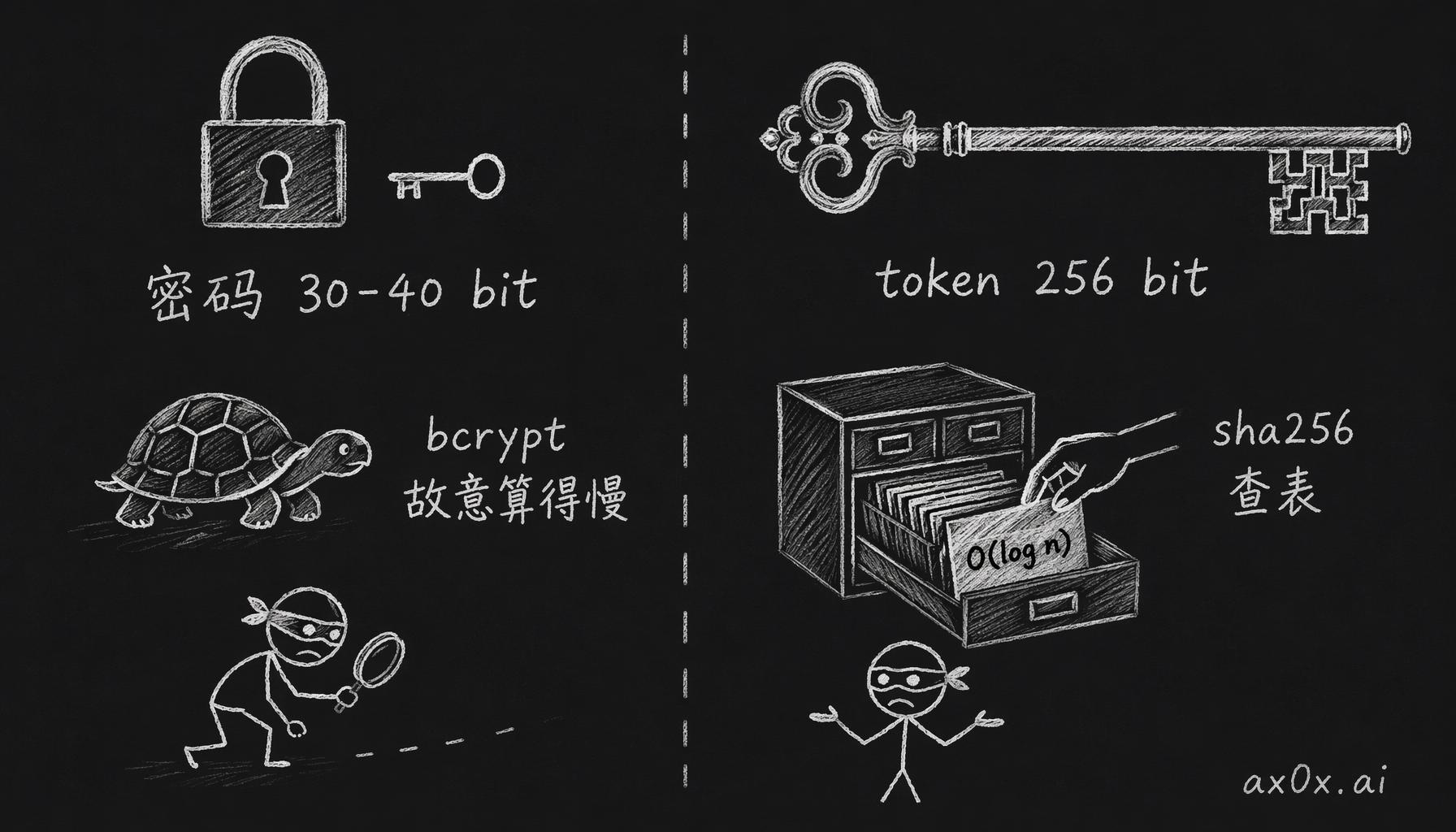 低熵密码要靠 bcrypt 故意算得慢来防撞库,高熵随机 token 本就撞不出来,sha256 加索引即可 O(log n) 查表
低熵密码要靠 bcrypt 故意算得慢来防撞库,高熵随机 token 本就撞不出来,sha256 加索引即可 O(log n) 查表
用 sha256 加唯一索引,每次请求验 token 就是一趟 btree 索引查表,SELECT * FROM api_tokens WHERE token_hash = \$1,O(log n) 的事。换成 bcrypt 你没法建索引,只能全表扫、逐行比对,QPS 一上去这张表就顶不住了。
语义搜索基本没花力气
动手写 API 之前我本来有点担心语义搜索这块:要不要单独加个向量库啊?是不是得上 Pinecone?HNSW 参数怎么调?
结果都不用。M2 那会儿就已经把 text-embedding-3-large 的 3072 维 embedding 塞进 halfvec(3072) 列了,还带 HNSW 索引。当时装它是为了跨源去重聚类——同一个事件被 5 家信源同时报道的时候,合并成一条。
现在给搜索用,就是把 query 也 embed 一次,然后 ORDER BY embedding <#> \$q。用负内积排序,对单位向量来说跟余弦距离等价,还能省掉归一化那一步。
加起来大概 24 行 SQL,外加一个 embed 调用。p50 延迟 250 毫秒,其中 embed 调用占 150 毫秒,SQL 本身 80 毫秒,单次查询成本 $0.00002。
只能说基建这个东西,早年装的时候设计得通用一点,后面的新需求经常就变成 24 行 SQL 的事。HNSW 那个索引从 M2 开始就一直在那儿跑去重聚类,这次等于顺手多接了一个用途。
MCP 之外还得写一份 skill
MCP 协议导出的只有工具签名:名字、参数、返回结构。语义它不管。
agent 调完 ax_radar_feed,拿回来一个 importance: 72,它根本不知道 72 分算高还是算低。HKR 三个轴是什么意思?featured 和 all 该选哪个?什么时候用 lexical 搜索、什么时候用语义搜索?这些全是运营层面的决策,协议里没有地方放。
所以又写了一份 skill 文件,放在 ~/.claude/skills/ax-radar/SKILL.md。description 字段调得很具体,「brief me on the radar」「save this for me」「search the radar for X」,用户说到这些短语,skill 就自动加载进 context。skill 正文放的全是 domain 知识:
- HKR 三个轴分别代表什么,featured / P1 的阈值各是多少
- 什么时候用语义搜索:找「大意」的时候用;查精确字符串用 lexical
- 几条守则:别把整个 feed 灌进对话,会污染 context;保存要用户明确说了才存,别猜着存;YouTube 信源永远不会被 excluded(这是运营决策)
- 三种 MCP 客户端(claude desktop / cursor / claude CLI)的 config 模板
我感觉 skill 这层是做 agent 工具的时候最容易漏掉的一环。MCP 只负责让工具可以被调用,至于什么时候调、结果怎么解读,协议里没地方写,还得再给 agent 一份说明才行。
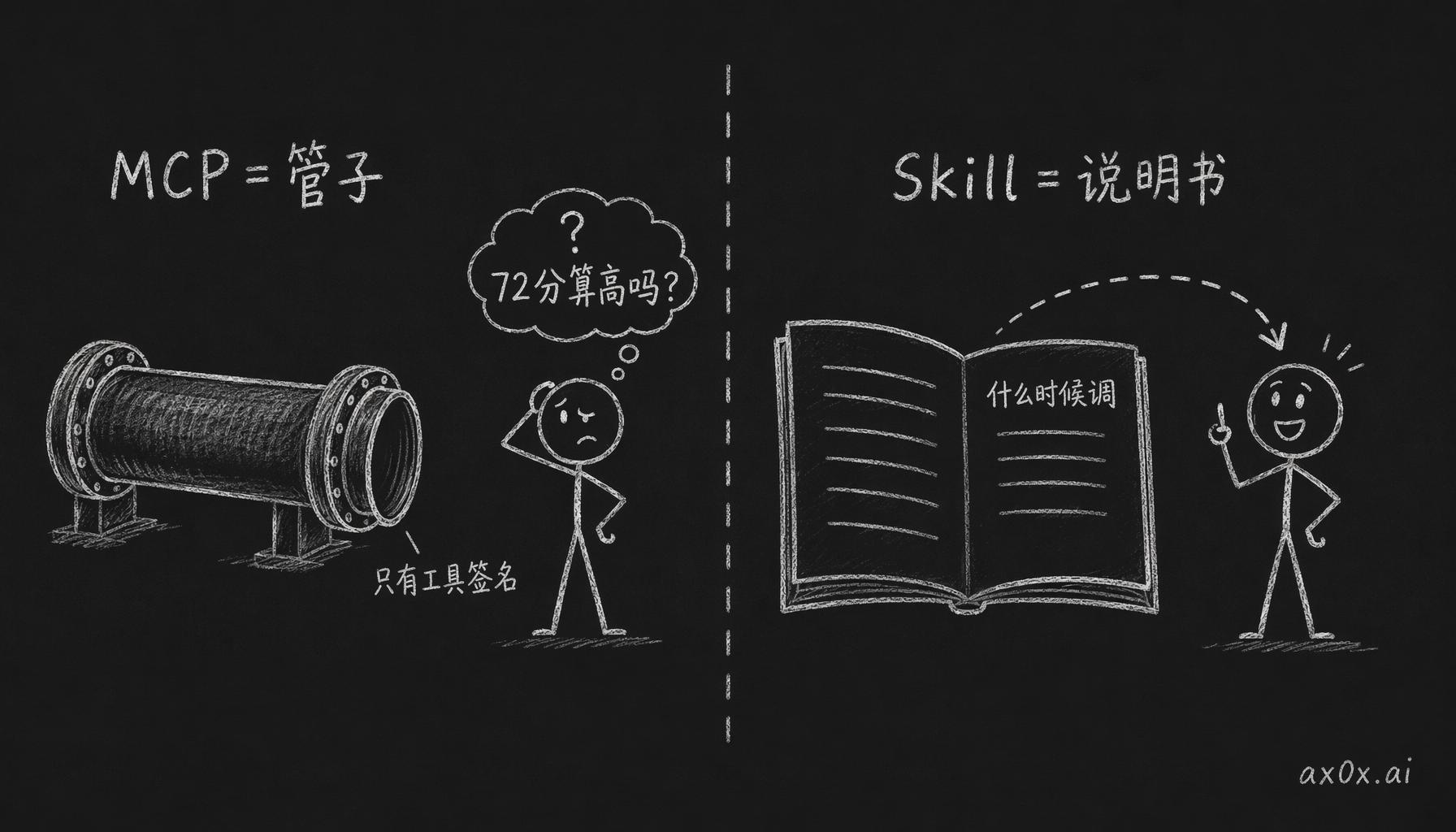 MCP 只导出工具签名(管子),Skill 才装 domain 知识告诉 agent 何时用、结果怎么解读(说明书)
MCP 只导出工具签名(管子),Skill 才装 domain 知识告诉 agent 何时用、结果怎么解读(说明书)
「brief 我一下这周的雷达」实际走的路
用户侧就打了这一句话。系统侧大概是这么走的:
- claude code 的 skill loader 扫所有 skill 的 description,发现 ax-radar 这个 skill 的描述里有「brief me on the radar」,把它加载进 context。
- skill 内容告诉 claude:这类「这周概览」的问题用
ax_radar_feed工具;简报优先走 markdown resourceax-radar://today,别去啃 raw JSON;按信源分组;突出has_commentary: true的条目。 - claude 发
tools/call ax_radar_feed {tier: "featured", limit: 30}给 MCP server。 - MCP server 验 Bearer token(sha256 查表,大概 5 毫秒),跑
getFeaturedStories查询,返回 30 条 JSON。 - claude 再发一个
resources/read ax-radar://today,拿到预格式化的 markdown 简报。 - claude 拿 markdown 当骨架,引用
item_id和editor_analysis字段,把总结写出来。
整个过程几秒钟就完了。这条路径一周前还不存在,现在我打一句话就能走通。
还没做的几块
webhook push 还没做。现在 agent 是 pull 模式,我问它才去查;新的 P1 文章进来主动推通知,这个放 v2。
多用户 scoping 也没做。当前一个 Bearer token 对应一个雷达实例,所有人看到的是同一份精选策略。以后要给团队用,得加 org_id 列,再上行级策略。
agent-to-agent 也还没有。理论上可以有一条链:一个 agent 从 X 和 arXiv 抓信号,写进雷达;另一个 agent 消费雷达,给我写早报。现在这条链后半段有了,前半段还没动。
最后
这次 ship 其实没造什么新东西。API 是包在已有 SQL 上的薄壳,MCP 是包在 API 上的薄壳,skill 是给 MCP 配的说明。单看每一层都很薄,但加在一起,同一个后端就多了好几个入口,人能用,agent 也能用。
做完我就在想,以后来查雷达的估计不会只有我一个人。claude 已经在查了,别的服务、合作方的 pipeline,说不定哪天也会来接。它们不看网页,要的是一个稳定的契约,HTTP、MCP、gRPC、webhook 这类,这次等于先给出去了两个。剩下的,webhook 反正排在 v2,到时候再说。
