我把读新闻的口味写成了一个 md 文件
我每天的信息输入大概是这个量级:arXiv 的 cs.LG 一天挂八十多篇论文,我关注的七个 X 账号一天出三十多条推,中美科技媒体加起来一天上百篇,再加上 GitHub trending、几十个公众号、Reddit 的 r/LocalLLaMA。昨天进我订阅列表的一共是 488 条。
我一天能认真读完的,大概也就 15 条。剩下那 473 条的结果一般是:该看的漏掉三条,然后又被十条无关紧要的占掉时间。两头都亏。
两个月前我决定不再靠毅力去解决这个事,做了个东西叫 AX 雷达:所有信源照常进来,一份用 markdown 写的编辑策略帮我筛,每天留十几条给我。线上地址在 news.ax0x.ai,源码在 github.com/xingfanxia/newsroom。
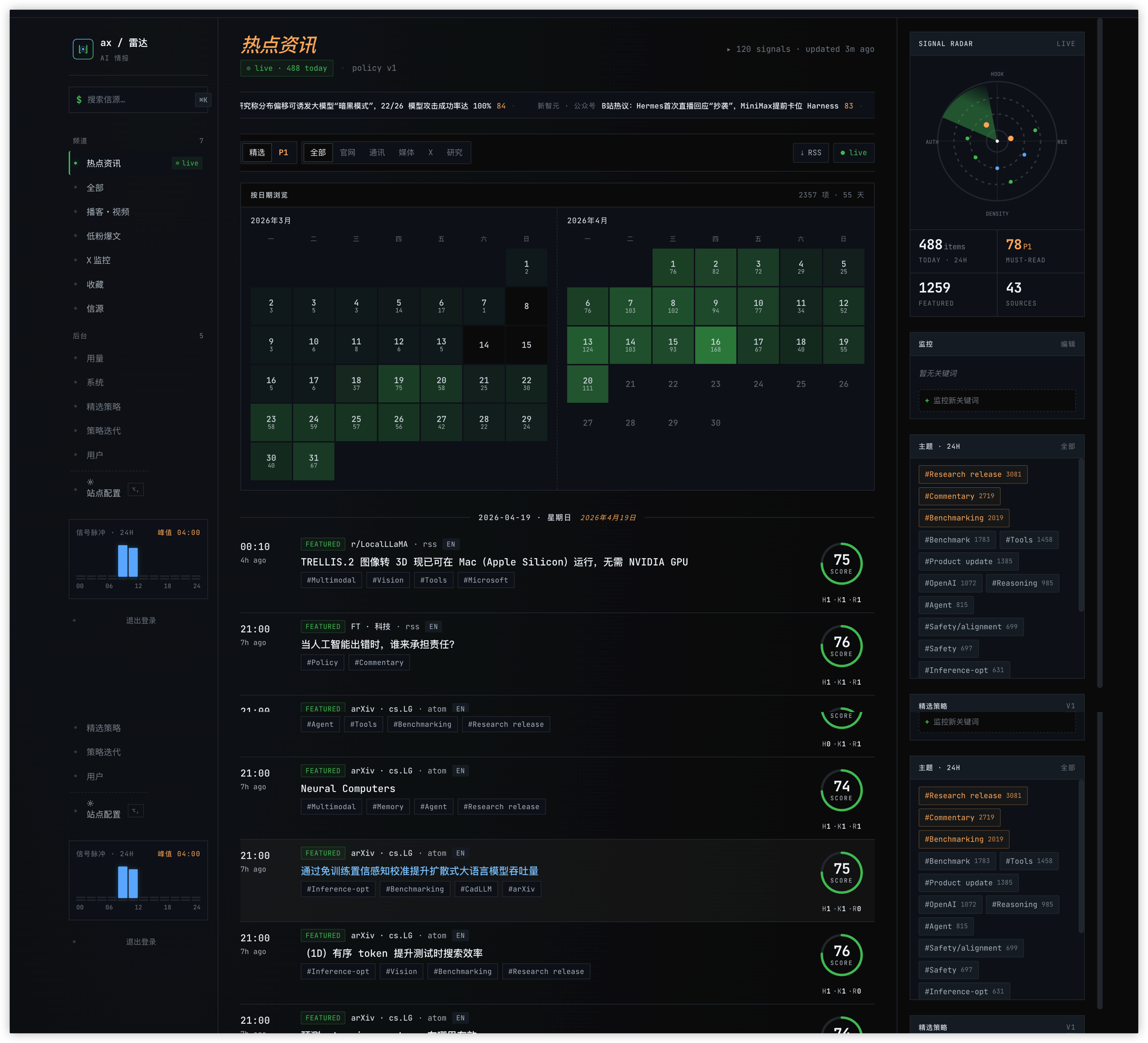 AX 雷达主信息流:HKR 环 + 日历热力图 + 右侧主题聚类
AX 雷达主信息流:HKR 环 + 日历热力图 + 右侧主题聚类
真正的信号上不了热榜
热榜、AI Weekly、各种 Telegram 频道,我以前都用过。这些东西干的其实是同一件事:把很多人的口味聚合成一个大众口味,再把大众口味推给我。问题是 AI 圈根本没有大众这个东西。
我关心的是模型底层——架构、推理优化、数据策略——加上 agent 产品设计。聚合器推过来的是什么呢?营销公告、融资新闻、创始人金句。打开一个"今日 AI 热榜",要么是 OpenAI 又出了个消费者功能,要么是谁又融了一轮。真正有信号的内容,比如一篇换了个想法的 arXiv 小论文,或者一条披露内部做法的 X 推,在热榜上根本排不上去。
反正聚合器做的就是去重加排序。它缺的是过滤和评分——去重排序靠流量数据就能做出来,过滤评分得有一个明确的编辑判断在后面撑着。把这个判断外包给热度加权也不行,热度筛出来的还是大众口味,我要的是我自己的口味。
管线分四段,每段独立跑
雷达分四个阶段,每个阶段独立跑、独立缓存:
- fetcher:50 个信源,按 cadence 分桶拉取(每小时 / 每天 / 每周)。RSS、Atom、RSSHub(公众号、36 氪、虎嗅、B 站都靠它覆盖),arXiv 原生 API,X API v2,再加少量爬虫兜底。每条按
(源 ID, 外部 ID)哈希去重,原始 HTML 写进 raw_items 表。 - normalizer:清 HTML、提作者、解析时间戳、规范 URL(去 UTM、跟重定向),产出干净的 items 记录。
- enricher:LLM 并行调用,给每条打中英文摘要、三轴标签(能力 / 实体 / 话题),再算一个 3072 维的 embedding。模型用的是 azure 上的 gpt-5.4 standard。
- scorer:第二轮 LLM,读当前版本的编辑策略(下一节讲),给每条打 0 到 100 分,落进 featured / all / P1 / excluded 四个档。
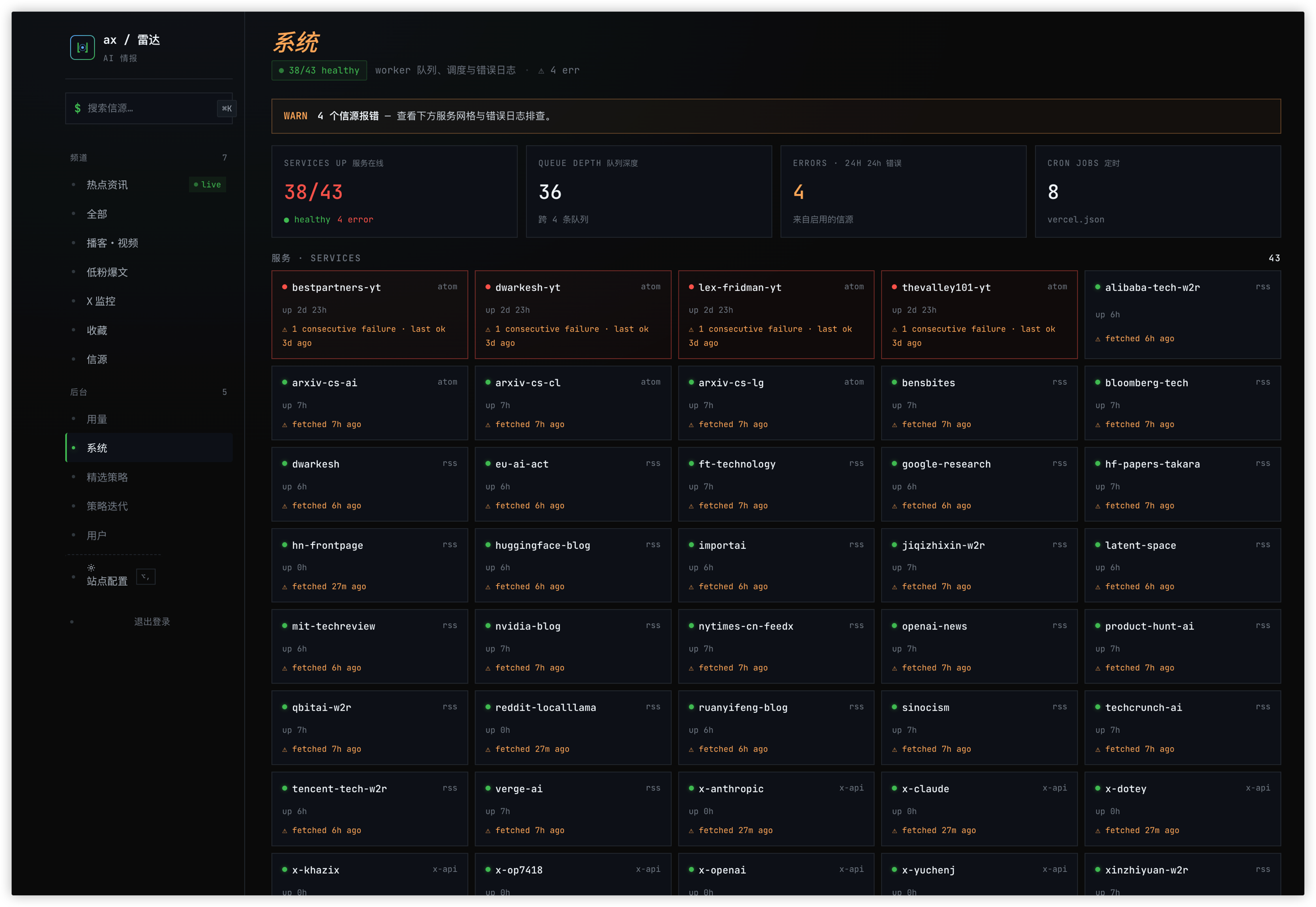 系统页:43 个信源的运行状态、队列深度与错误日志
系统页:43 个信源的运行状态、队列深度与错误日志
每个阶段写自己的表,按 (item_id, version) 缓存。一条内容 enrich 过一次就不重跑;策略改了就只重跑打分,enrich 不动。这个缓存省下来的钱是整个系统跑得动的前提。过去三十天一共跑了 6.8 万次 LLM 调用,总花费低三位数美金,单人项目完全扛得住。
成本结构也顺便说一下:大头是 enrich,占一半左右;其次是 score,占三分之一;剩下的 commentary、embed、newsletter 加起来不到两成。embed 调用次数看着多,其实几乎不花钱,text-embedding-3-large 的价格跟文本生成差着两个数量级。
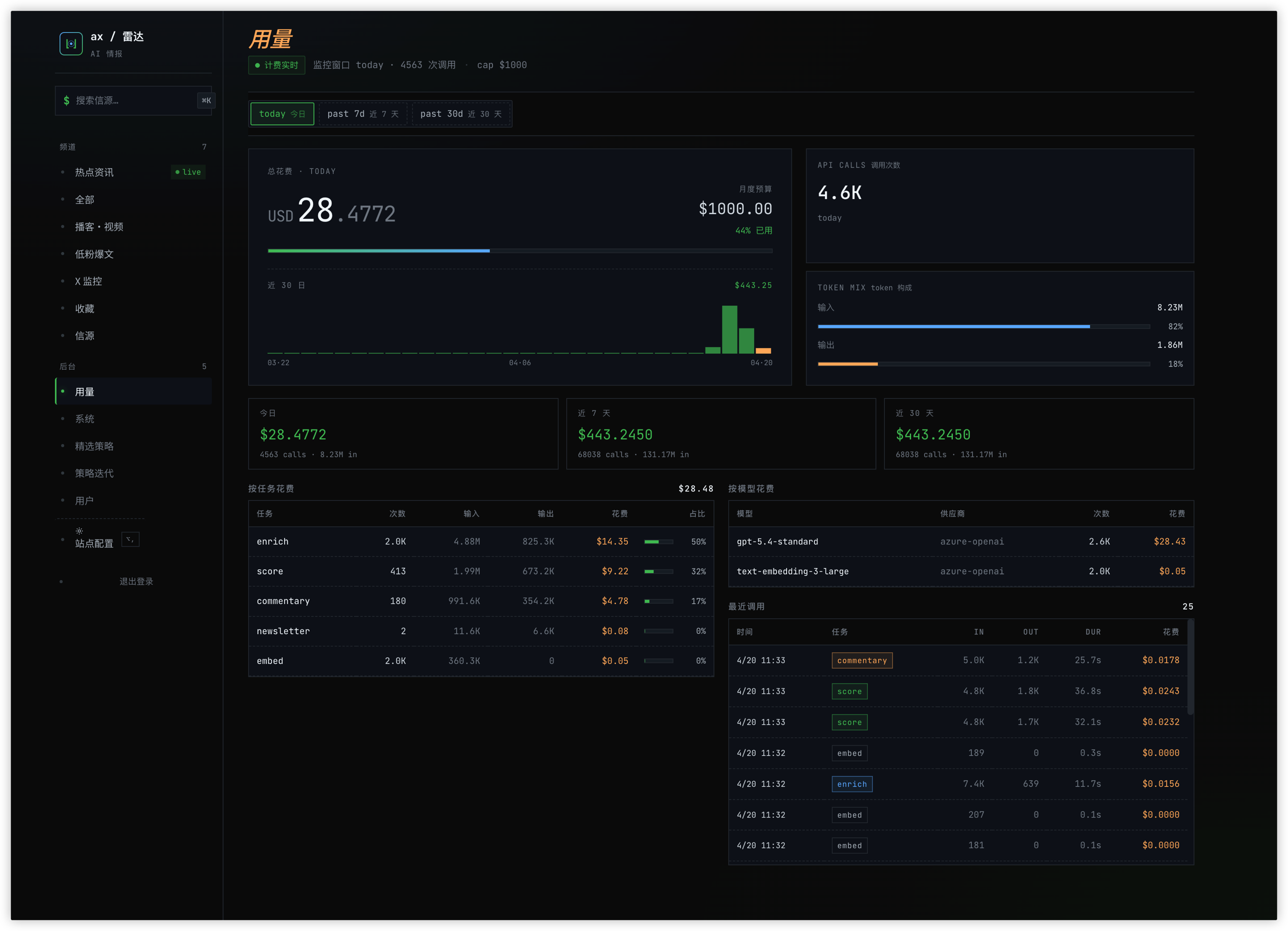 用量页:今日花费、月度预算、按任务与按模型的成本构成
用量页:今日花费、月度预算、按任务与按模型的成本构成
编辑策略必须是人能读的文件
做 AI 新闻过滤,一般的做法是把规则写进 scorer 的 prompt 里,大部分开源项目都这么干。我觉得这么干有三个问题:
- prompt 是个黑盒。改了什么、为什么改,事后说不清楚,想做 A/B 也做不了。
- prompt 没法 diff。v2 比 v1 严在哪、松在哪,讲不出来。
- prompt 是一次性的。换个项目、换个模型,攒下来的经验直接归零。
雷达走的是另一条路:编辑策略是一份叫 editorial.skill.md 的 markdown 文件,600 多行,里面写清楚了这几样东西:
- 角色定义:读者是有行业认知的专业人士,不要喂"ChatGPT 是 OpenAI 做的 AI 工具"这种东西
- HKR 评分框架(下一节讲)
- 0 到 100 每个分数段代表什么,带具体例子(95 到 100 是"每家都要写",85 到 94 是"必须当天写")
- 六条硬排除规则:技术门槛过高没有上车点、云厂商促销、炒冷饭、科学叠 AI 但跟 agent / 产品无关、纯营销、零论据观点稿
- 正信号加分(+3 到 +5):Anthropic 实质更新、国产旗舰模型发布、跨源聚类、第一人称实验、带复现条件的论文
每次改动在数据库里留一版(policy_versions 表),worker 下次打分读当前版本,想回滚就是改一条 SQL 的事。
这么做的价值在于,编辑判断和打分执行被拆开了。判断这部分是人干的活,我能直接打开文件改,也能拿去跟人讨论;执行交给模型,它负责读这份 markdown,然后按规则打分。两边各自迭代,互相不挡路。
 编辑判断写成一份人能读的策略文件,人负责改、模型负责读它打分,两边各自迭代
编辑判断写成一份人能读的策略文件,人负责改、模型负责读它打分,两边各自迭代
整个项目回头看,我觉得必须坚持的设计就这一条:判断要写成人能读的文件。别的全都可以换,数据库、模型、前端框架换掉都不伤筋骨;但策略要是写在 prompt 里,大概三个月之后整个系统就没人敢碰了。
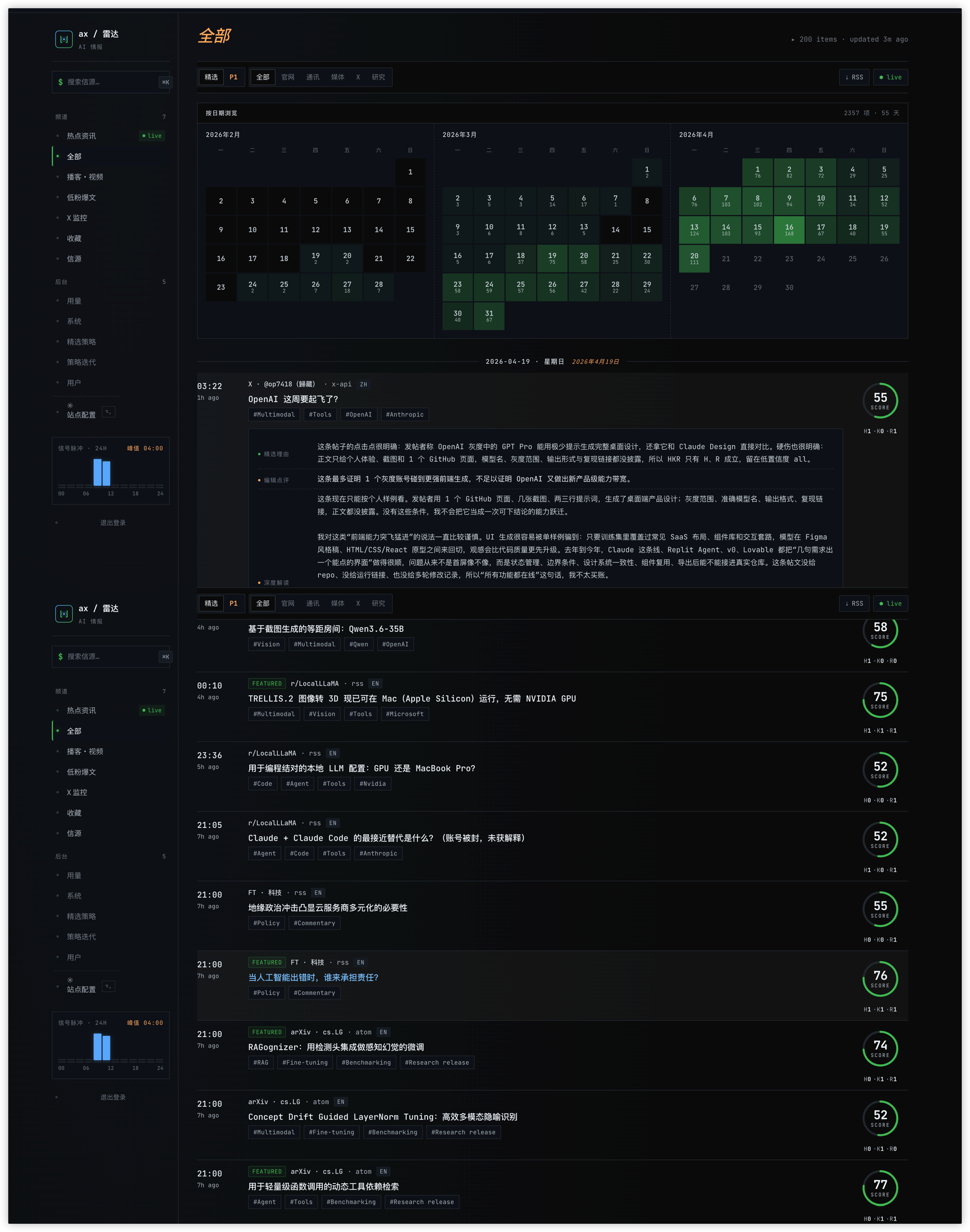 全部流里一条 X 帖子,带"精选理由 / 编辑点评 / 深度解读"三段式评注
全部流里一条 X 帖子,带"精选理由 / 编辑点评 / 深度解读"三段式评注
把新闻当文章一样打分
传统的评分就一个维度,重要性。问题是"重要"这个词太模糊了,对谁重要、在什么意义上重要,都没说。我借了卡兹克写公众号长文的 HKR 框架(Hook / Knowledge / Resonance),把它挪到新闻筛选上:
- H / Hook(有趣):标题或者切入点得让人想点进去——有悬念、有反转,或者有个没见过的角度。营销话术不算 hook。
- K / Knowledge(有料):读完得多点什么,多一个数字、多一种机制,或者多一个值得去验证的说法。
- R / Resonance(有共鸣):戳中身份神经,读者会想转给同行的那种。
三个轴的命中情况决定四个档:
- featured(主推):三个轴至少中两个
- P1(必读):三个全中,分数 ≥ 85
- all(全量可查):至少中一个
- excluded(排除):一个都没中,或者触发任何一条硬排除
这样拆的好处是,每条判断你都能看明白它是怎么来的。打开一篇选中的文章,右边标着 H ✓ K ✓ R ✗,一眼就知道这是条有 hook 有料但缺共鸣的研究向稿子;打开一篇被过滤的,标着 H ✗ K ✗ R ✗,不用翻 prompt 去猜原因。有料但没 hook 的不冲首屏,会沉到"全部"列表里。有 hook 没料的基本就是标题党,直接排除掉。三个轴都中的那种直接置顶进 P1。这套分档逻辑写在策略文件里,大概一个礼拜就调稳了。
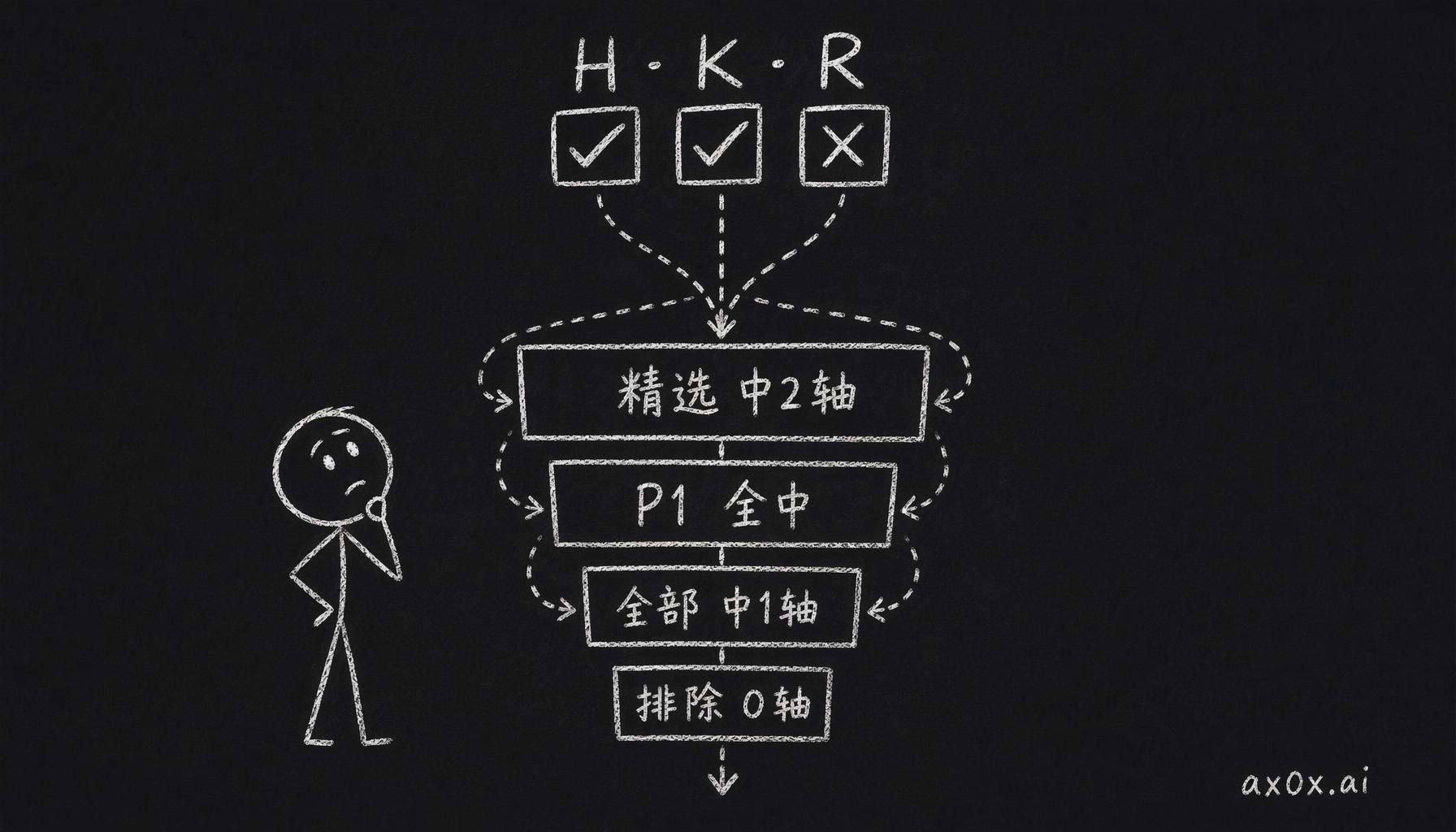 H·K·R 三个轴各判命中与否,命中几个决定一条内容落进精选、P1、全部、排除四个档
H·K·R 三个轴各判命中与否,命中几个决定一条内容落进精选、P1、全部、排除四个档
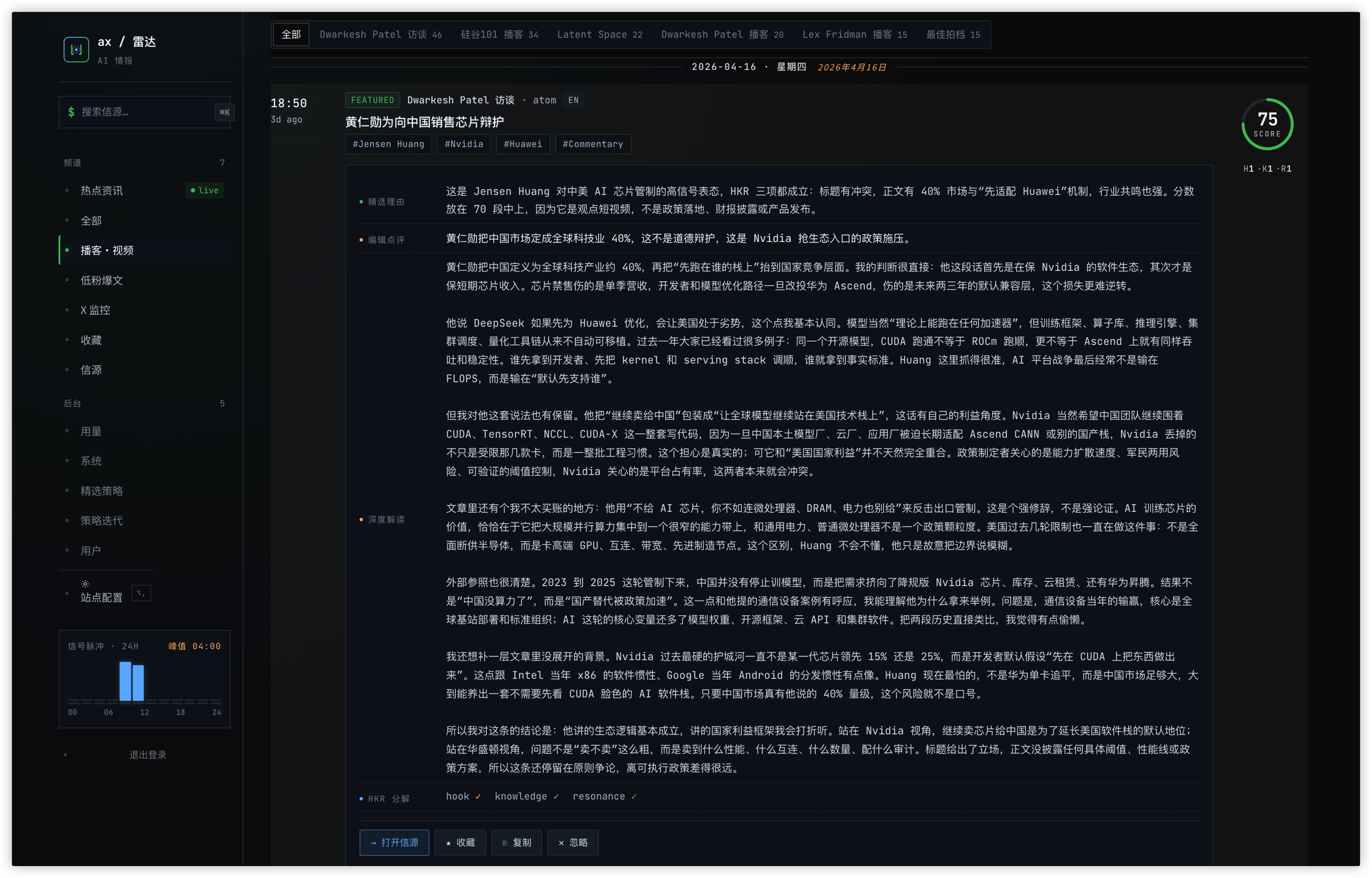 一期 Dwarkesh 播客条目的完整 HKR 拆解与深度解读
一期 Dwarkesh 播客条目的完整 HKR 拆解与深度解读
agent 改的是策略,不是新闻
雷达后台有个页面叫"策略迭代",用起来大概是这个流程:
- 每天刷主信息流,感兴趣的点赞、没意思的点踩、特别好的收藏,可以顺手附一句反馈。
- 攒够一批(比如一周 50 条),去"策略迭代"页点
开始生成新草稿。 - 一个 claude agent 起 session,工具就三个:读当前策略、读一批反馈样本、写新草稿。
- 系统 prompt 管着它:读当前策略 + 读反馈 + 给出最小修改,另外单独列一份「没动的地方,以及为什么不动」。最后这条是防它过拟合最近几条反馈,把通用规则改崩。
- UI 里看 diff:绿加红删,改了哪些阈值、加了哪些排除规则,确认没问题就点"应用"。
- 新版本写进 policy_versions 表,下一轮 scorer cron 自动用新策略。
这套流程里有两个设计值得单独说。第一,agent 是副主编,不是主编。它读策略、看反馈、提修改建议,最后的审核权必须在人这边。这条职责划分我觉得在 AI 辅助的工作流里非常关键:真让 agent 直接改上线策略,调试成本会爆炸。
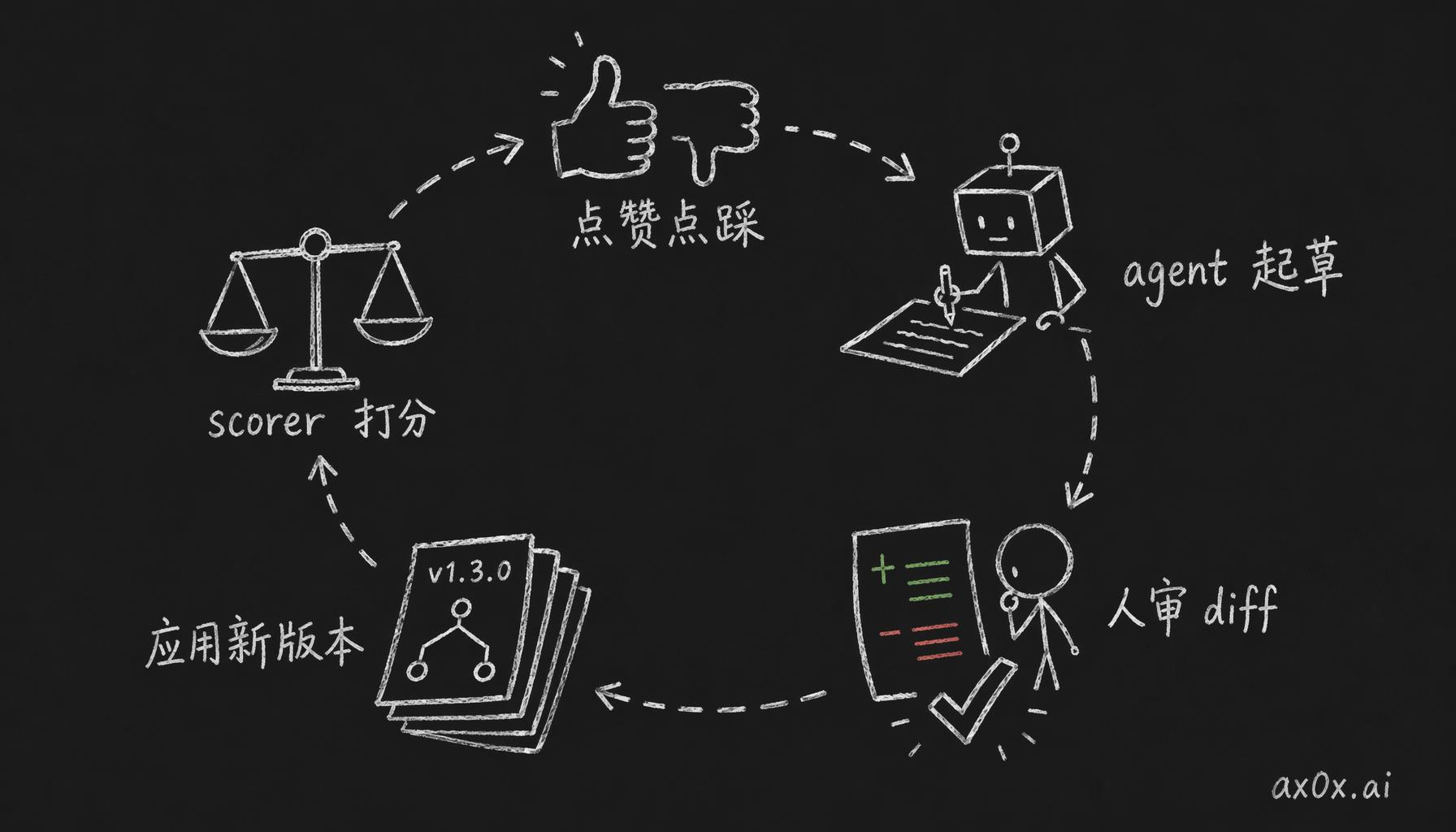 用户点赞点踩攒成反馈,agent 起草新策略,人审 diff 后应用成新版本,scorer 用新策略打分,闭环里最终审核权始终在人手里
用户点赞点踩攒成反馈,agent 起草新策略,人审 diff 后应用成新版本,scorer 用新策略打分,闭环里最终审核权始终在人手里
第二,策略有版本、有父子关系。policy_versions 表里存 parent_version,v7 从 v6 派生出来,策略的演进就有了祖谱,出了问题能定位到从哪一代开始歪的。就跟 git 的 commit 树一个道理,只是颗粒度从代码换成了策略文件。
还没解决的三件事
低粉爆文这条线还没通。X 的 search/all 端点可以按粉丝阈值反查(作者粉丝 < 5 万 + 互动率 > 阈值),但现在卡在 API 套餐配额上。知乎、即刻、小红书的数据接口不稳定,爬虫兜底还在做。这个功能通了会非常有用——AI 圈真正的早期信号,经常出现在三千粉工程师的时间线上,三十万粉的大 V 反而是信号的下游。
跨源聚类的 UI 还没全接上。后端在做近重复合并,0.88 余弦距离加 48 小时窗口:一条新闻被五家同时报,应该只显示一条,右边标"另有 N 个信源也报道了此事"。前端的 cluster 徽标还没接上,用户暂时看不到去重的好处,首屏有时候还是能刷到同一个事件的多源报道。
评分校准会漂。我换过一次 scorer 的模型(早期是 claude haiku,现在是 gpt-5.4 standard),0 到 100 的分布立刻错位:同一份策略、同一批稿子,两个模型给出来的均值差 5 分。换模型就得把整套分数带重新校准一遍,这个坑我感觉大部分同类项目都会踩。
跑了两个月
雷达跑了两个月,我每天就看它筛出来的那十几条,剩下的我知道策略已经替我过了一遍,不用一直怕漏。
另一个收获是编辑判断变成了一个可以版本化维护的东西。选题这种事本来全凭直觉,这条有意思就转了,那条没意思就划掉,直觉没法 diff,也没法跟别人讲清楚。写成 600 行 markdown 之后,为什么点开、为什么划掉,哪些是硬规则、哪些是加分项,全在文件里。想跟同行讨论口味,直接把某次 commit 的 diff 发过去就行,不用再靠举例子。
