Walking Back the Abstraction
Part 2 ended with a clean abstraction: six slots, one pipeline, seven product categories.
It ran for two weeks. Last week I found a bug.
A merchant uploaded a denim jacket, picked the "Material Breakdown" template, and got back six gemstones floating on dark slate.
Denim. Gemstones.
Where the Abstraction Failed
Part 2's claim was that the six slots aren't photography techniques — they're persuasion angles. First impression, professional breakdown, visual identity, quality proof, lifestyle context, decision info. That claim is right.
What was wrong: the abstraction stopped at the label layer.
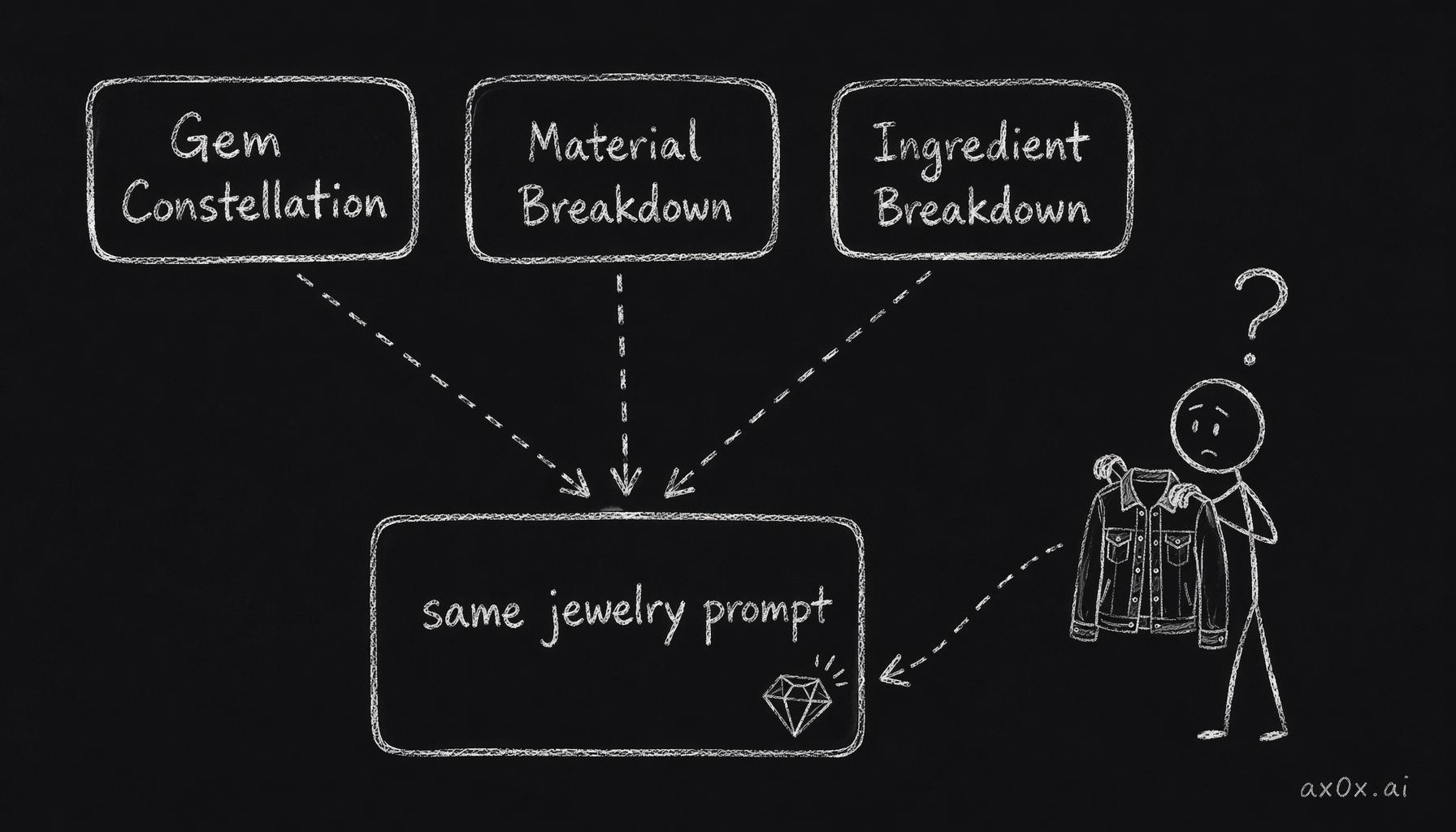 The abstraction stopped at the label layer — three different labels all point to one jewelry prompt underneath, so a denim jacket returned gemstones
The abstraction stopped at the label layer — three different labels all point to one jewelry prompt underneath, so a denim jacket returned gemstones
Jewelry's second slot is labeled "Gem Constellation." Fashion's is "Material Breakdown." Beauty's is "Ingredient Breakdown." Three different labels pointing to the same prompt function. The prompt itself still said "specimen constellation of jewelry, shot on dark slate."
The type system told me each slot was domain-agnostic. The prompt hardcoded jewelry visual language from top to bottom.
Labels got translated. Prompts didn't.
This is the nastiest kind of bug. Types compile. Lint passes. UI renders correctly. Users only notice when they look at the actual output and realize something's off.
Abstraction Doesn't Survive the Domain
The deeper issue: even patching each prompt with three domain branches wouldn't fix it.
Fashion's top-converting format isn't a studio shot. It's OOTD — a full-body model shot taking 60%+ of the frame. Three independent industry reports (千瓜, jizhil, ebrun) all put OOTD at 60-70% of merchant content on Xiaohongshu.
Beauty's top-converting format isn't a studio shot either. It's the swatch grid — a five-in-one composite of brand shot, lip, hand, finger, and applicator. Colorkey built a brand on this single format accounting for ~45% of their output.
Jewelry sizing uses a coin-scale comparison. Fashion sizing overlays text on a model photo: "163cm / 48kg wearing M, size up if plus-size." These are different images, not different labels on the same image.
Jewelry, fashion, and beauty have fundamentally different visual grammars on Xiaohongshu. You can't bridge them with a label swap. Each category has its own native vocabulary.
Part 2's "six slots, one pipeline" gave me a false sense of safety: one prompt set running across three categories. In practice, it was jewelry's six images wearing three labels.
Why I Skipped the "Safe" Phase
The original plan was phased:
Phase 1: Keep the six slots. Add domain branches to the four weak prompts (constellation / craft detail / size reference / hero). About a day of work.
Phase 2: Per-category template sets. About a week. Wait for user data to inform which templates each category actually needs.
Phase 1's justification was textbook engineering: ship something small and safe, gather data, then commit to the larger change.
But I don't have users yet. No data is coming.
Without data, Phase 1's guess quality equals Phase 2's guess quality. Both are educated guesses. The only difference: Phase 1 generates throwaway work. The domain branches written for the old six-slot scheme get deleted the moment Phase 2 replaces those slots for fashion and beauty.
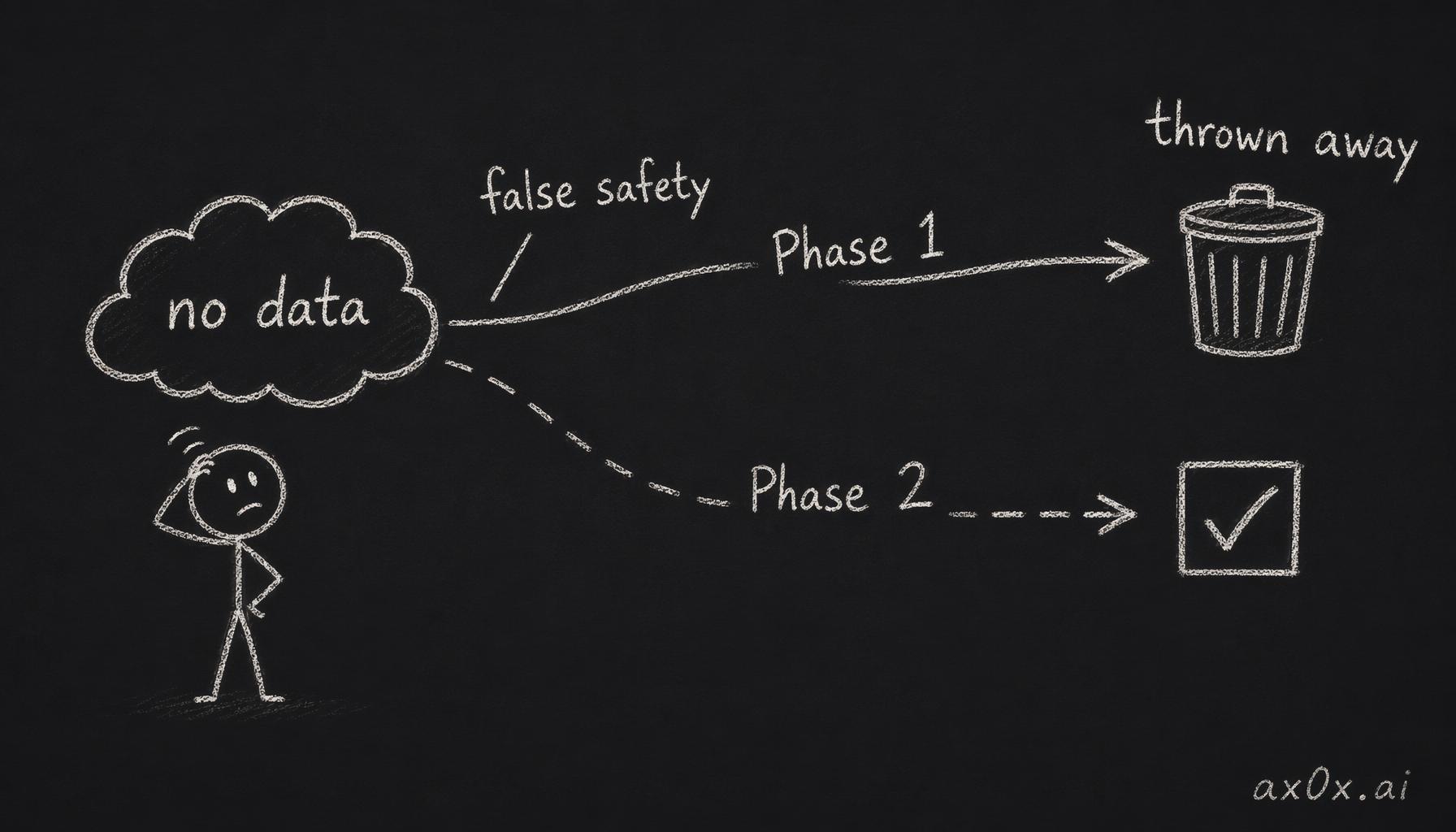 A phased rollout with no users is a feeling of safety — Phase 1 and Phase 2 guess quality is equal, and Phase 1's work gets thrown away
A phased rollout with no users is a feeling of safety — Phase 1 and Phase 2 guess quality is equal, and Phase 1's work gets thrown away
Phased rollout without data isn't risk management. It's a feeling of risk management.
Straight to Phase 2.
Qualitative Research via Parallel Agents
No users meant the only source of signal was public material. I ran three research agents in parallel, each with independent search scope:
- Fashion agent: industry reports from 千瓜, jizhil, ebrun, niaogebiji
- Beauty agent: breakdowns from 数英, SocialBeta, 品牌星球
- Case study agent: post-mortems on 10 top brands' Xiaohongshu accounts (Li-Ning, 花西子, HFP, Colorkey, 薇诺娜, etc.)
Hard constraint: at least 50% topic overlap between agents. A number claimed by one agent alone doesn't count. Two agents independently landing on the same figure does.
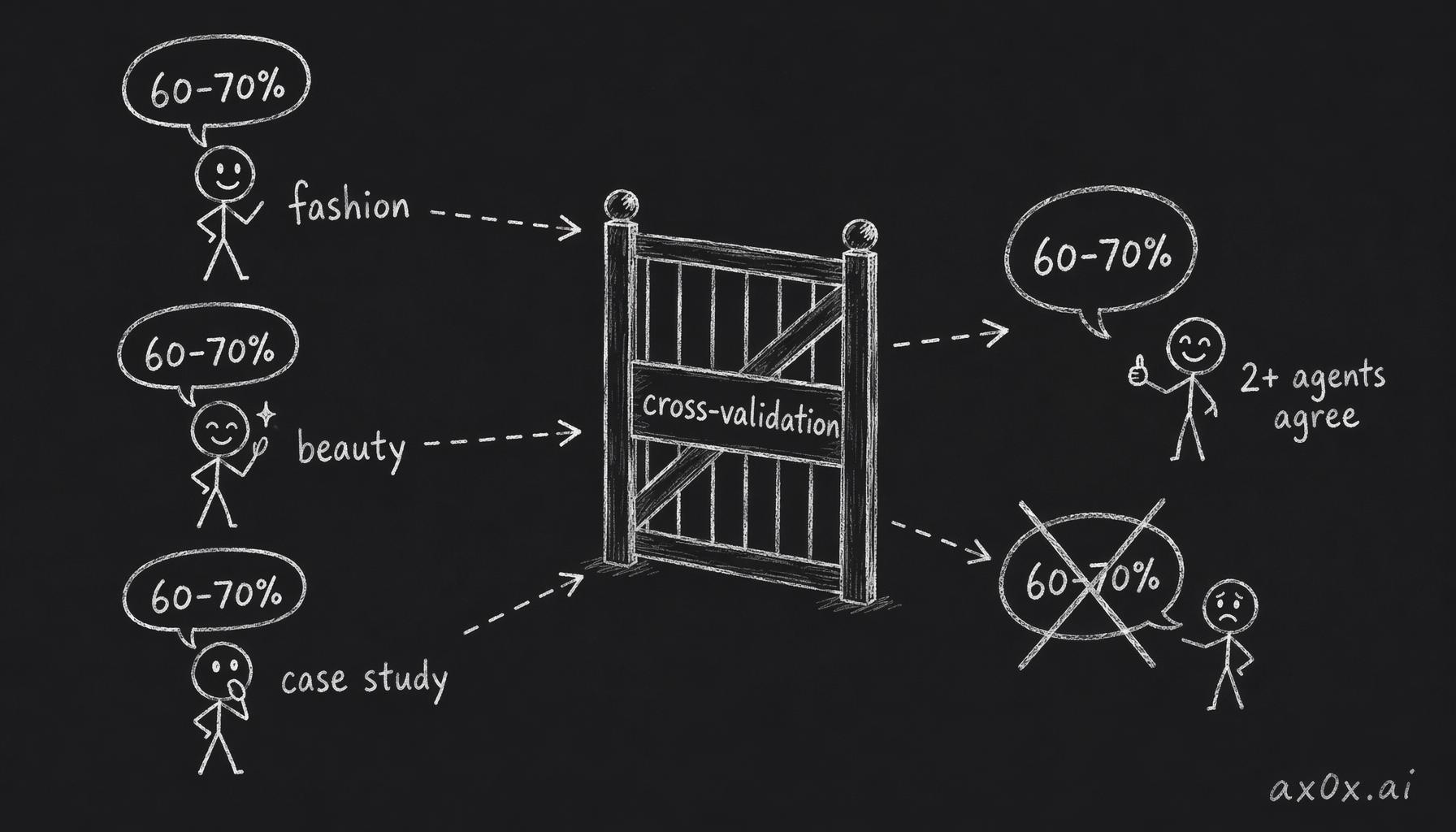 Agents fabricate numbers — a figure claimed by one agent alone doesn't count; only a number two-plus agents independently land on passes cross-validation
Agents fabricate numbers — a figure claimed by one agent alone doesn't count; only a number two-plus agents independently land on passes cross-validation
Data points that survived cross-validation:
- OOTD accounts for 60-70% of fashion merchant content on Xiaohongshu — confirmed independently by 千瓜, jizhil, and ebrun
- Outfit grids drive +50% repost rates — case study: 刘小被儿 built a 2.2M follower account on "10 outfits × 1 denim jacket"
- Li-Ning's hot pot puffer jacket moved 300K units and ¥100M GMV during Double 11 using "scene + product + model" composition
- Skincare routine videos capture 51.32% of beauty category engagement (千瓜 2025 annual report)
- Swatch grids are the dominant format in color cosmetics on Xiaohongshu — Colorkey's entire brand runs on this single template
The ten-brand case study also killed a default assumption: top-tier merchants rarely post standalone hero studio shots. Their viral content is almost always "product + human + scene" composition. That dropped fashion's standalone hero slot entirely.
The Final Three Sets
Fashion (6): OOTD try-on, outfit grid (2×2), scene shot, flatlay + on-body, before/after (with stats like "+5cm taller"), sizing overlay (model photo with text overlay).
Beauty (6): hero packshot, swatch grid (5-in-1), before/after, benefits card (single-page bold headline, not three-column infographic), routine sequence (including AM/PM), collection grid (TOP N / red vs. black lists).
Jewelry (6): Unchanged from Part 2.
The shared infrastructure stays clean: three categories, same pipeline. What varies is the prompt layer's visual grammar.
Cutting Is Harder Than Picking
The real cost of this iteration wasn't picking the six. It was cutting the six.
Templates that sound reasonable but didn't survive research:
- Stitch detail / craft macro — Zero merchant evidence. Only high-end designer brands use it. Forcing it as a default would underperform for 90% of users.
- Height-grid model shots (155/160/165/170 same product) — Merchants lack the multi-model budget. "Petite specialist" is a blogger niche, not a merchant template.
- Outfit moodboard collage — Blogger identity tool, not merchant sales tool. Outfit grid already covers the "multiple looks" need without the aspirational-narrative overhead.
- Three-column ingredient infographic — AI garbles molecular diagrams. HFP, the brand most associated with ingredient-first marketing, actually uses single-page bold-text posters. Merged into the benefits card.
- Standalone AM/PM routine — It's a variant of the routine template, not its own slot.
- Brand ambassador "Oriental aesthetic" shoots — 花西子's niche luxury play. Doesn't transfer to ordinary merchants.
Every one of those sounds reasonable. Reasonable isn't evidence.
The hard constraint "exactly six per category" forced the cuts. Loosen it to eight and all of the above creep back in — because cutting is harder than picking.
The rule I ended up with: if research can't surface at least one top-tier merchant using the template in a proven viral post, it doesn't deserve a slot.
What's Still Unresolved
- The 6+6+6 set is qualitative inference from three research agents, not measured data. When users start using the product, the next iteration should use per-template deselection rate and regeneration rate as A/B signals.
- The "general" fallback still maps to jewelry's six. That's fine for craft items and incense (jewelry-shaped small goods) but will break when food or home goods get added.
- TypeScript compiling isn't the same as prompts producing correct output. The 10 new prompts need hands-on UAT and new-vs-old A/B smoke tests — same approach as the earlier Azure vs. OpenAI provider comparison.
Iteration Is Self-Reversal
Part 2 abstracted the pipeline into "six slots = six persuasion angles." Half of that was right: the infrastructure generalizes — API calls, storage, UI rendering, types, billing all stay the same across categories. The other half was wrong: content doesn't generalize. Each category has its own visual grammar, and no label layer bridges them.
Abstraction can save you from writing the same code three times. It can't save you from writing the same prompt three times.
Every three or four weeks, I end up reversing a judgment I made the previous sprint. That's not a sign the work is going badly. It's the sign it's going correctly.