一套 prompt 通吃三个品类,是我想多了
 三个品类各自的模板集
三个品类各自的模板集
上一篇讲了那套「6 个槽位通吃 7 个品类」的设计:一套 pipeline,所有品类走同样的 6 张图。这套东西跑了两周,被一个 bug 打回来了。有个测试用户传了件牛仔外套,选了「材质拆解」,出来的图是白色 slate 底板上悬浮着六颗切面宝石。牛仔外套拆出六颗宝石,挺离谱的。
这篇讲我怎么排查这个问题、为什么最后把服饰和美妆的模板各自推倒重来,以及中间几个判断大概是怎么做的。
先排查:问题出在哪一层
先说 Part 2 那个抽象本身。6 个槽位对应 6 个说服角度:第一印象、专业拆解、视觉识别、品质证明、生活场景、决策信息。这个判断我现在还是认的,它没错。
出问题的是抽象只做到了标签层。珠宝的第二槽叫「宝石星图」,服饰的叫「材质拆解」,美妆的叫「成分拆解」,三个中文标签指向的其实是同一个 prompt 函数,prompt 里写的还是 "dark slate 上的珠宝样本星图"。也就是说类型系统看到的是「每个槽位品类无关」,但 prompt 里固化的视觉语言从头到尾都是珠宝的。标签翻过来了,底下那层根本没动。
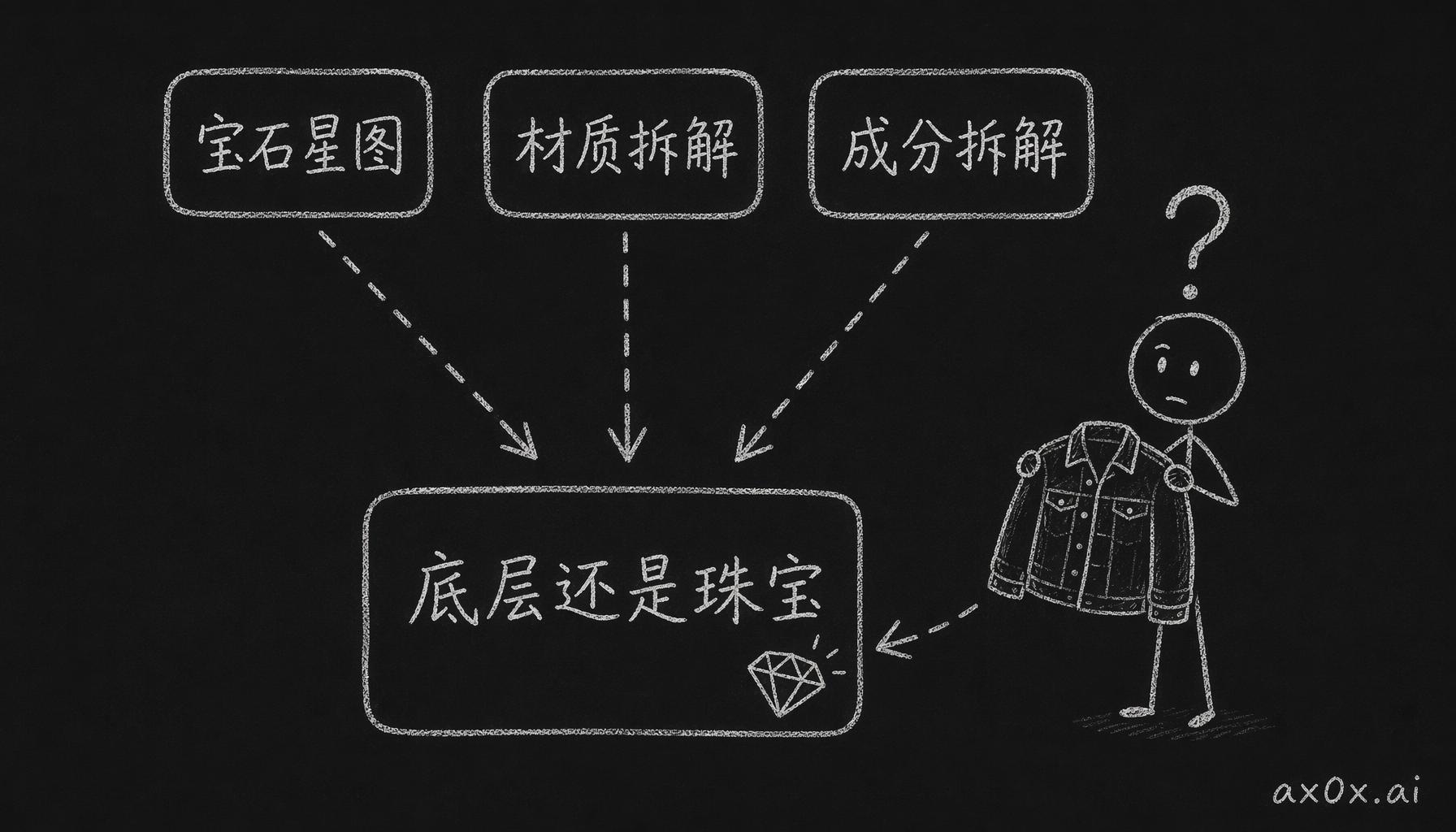 抽象只翻译了标签层——三个不同标签底下指向的还是同一个珠宝 prompt,所以牛仔外套拆出了宝石
抽象只翻译了标签层——三个不同标签底下指向的还是同一个珠宝 prompt,所以牛仔外套拆出了宝石
这种 bug 挺阴的:类型检查是绿的,eslint 是绿的,UI 上显示的标签也是对的,只有用户真的传一张图进来、看一眼生成结果,才发现不对。整条链路没有一个环节能自动把它报出来。
打补丁的方案为什么不够
排查完我一开始想的是打补丁:每个 prompt 里加三个品类的分支就完了。后来发现不够,问题比错标签还深一层。
穿搭在小红书上的第一槽根本不是棚拍图,是 OOTD——全身人像占屏 60% 以上的那种。千瓜、jizhil、ebrun 三个行业信源都把 OOTD 归为服饰商家的主力内容,占比大概 60-70%。美妆的第一槽也不是棚拍,是试色拼图,五合一那种:品牌图加唇、掌、指、勺,Colorkey 这类彩妆品牌靠试色内容占了大约 45%。再比如尺寸参考,珠宝用硬币对比,穿搭用的是模特身高叠字——「163cm/48kg 穿 M,微胖建议 L」——完全是两套东西。
所以珠宝、穿搭、美妆在小红书上各有各的视觉语法,或者说各有各的说服方式,不是在 prompt 里换个标签、加个 if 分支能通的。Part 2 那句「6 个槽位一套 pipeline」给过我一种安全感,实际跑的情况是珠宝的 6 张图套着三个不同的标签在出货。
要不要分阶段上线
原计划是分两步走。Phase 1 保留 6 个槽位,给 4 个最弱的 prompt(星图、工艺细节、尺寸参考、hero)加品类分支,一天能搞完;Phase 2 每个品类独立做 6 个模板,大概一周,等用户数据来决定哪些模板该进该出。
Phase 1 的理由听起来很工程师:先发个小的、安全的,等数据回来再做大改。但这个产品现在没有用户,没有数据会回来。没数据的时候,Phase 1 的猜测质量和 Phase 2 的猜测质量是一样的,都是拍脑袋;差别只在 Phase 1 做完的 prompt 到 Phase 2 会全部扔掉——为旧 6 槽位写的品类分支,换新模板集之后一张都留不下来。等于多做一轮 rework,换来一个「我在小步迭代」的感觉。所以直接做 Phase 2。
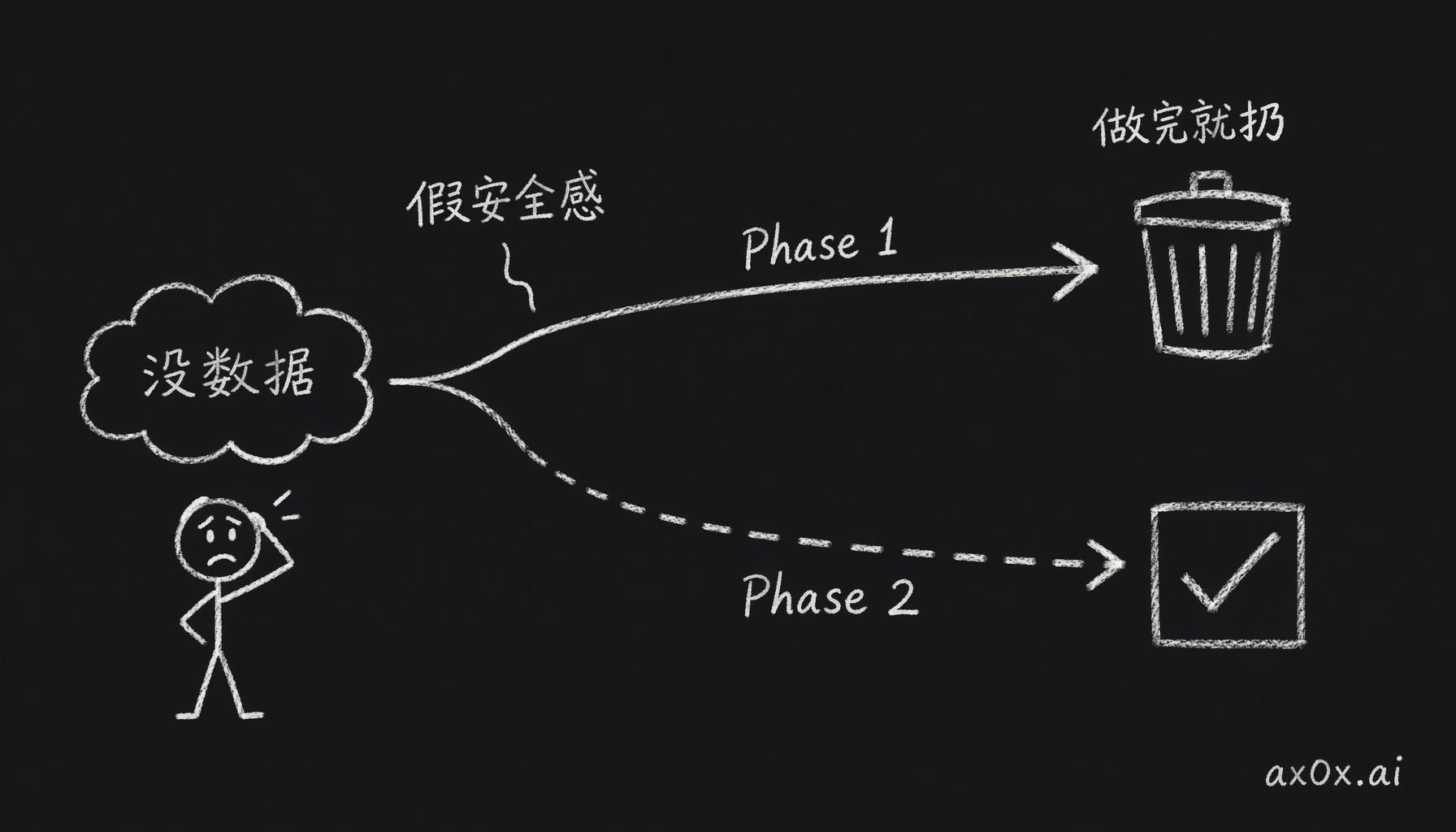 没有用户时分阶段上线是假安全感——Phase 1 和 Phase 2 的猜测质量一样,Phase 1 做完的还全部扔掉
没有用户时分阶段上线是假安全感——Phase 1 和 Phase 2 的猜测质量一样,Phase 1 做完的还全部扔掉
没用户,就让 agent 去挖公开资料
新模板具体长什么样,没有用户数据就只能从公开研报和案例里挖。我开了 3 个 agent 并行去查:
- 第一个专盯 fashion,查千瓜、jizhil、ebrun、niaogebiji 的服饰 XHS 研报
- 第二个专盯 beauty,查数英、SocialBeta、品牌星球的美妆和护肤拆解
- 第三个专门看 10 个头部品牌的 XHS 账号做 post-mortem,李宁、花西子、HFP、Colorkey、薇诺娜这些
我加了一条硬约束:agent 之间话题重合度要有 50% 以上。agent 是会编数据的,一个 agent 单独报出来的数字我不敢直接用,得有第二个 agent 独立查到同一个数字才算数,所以交叉验证这一步省不掉。
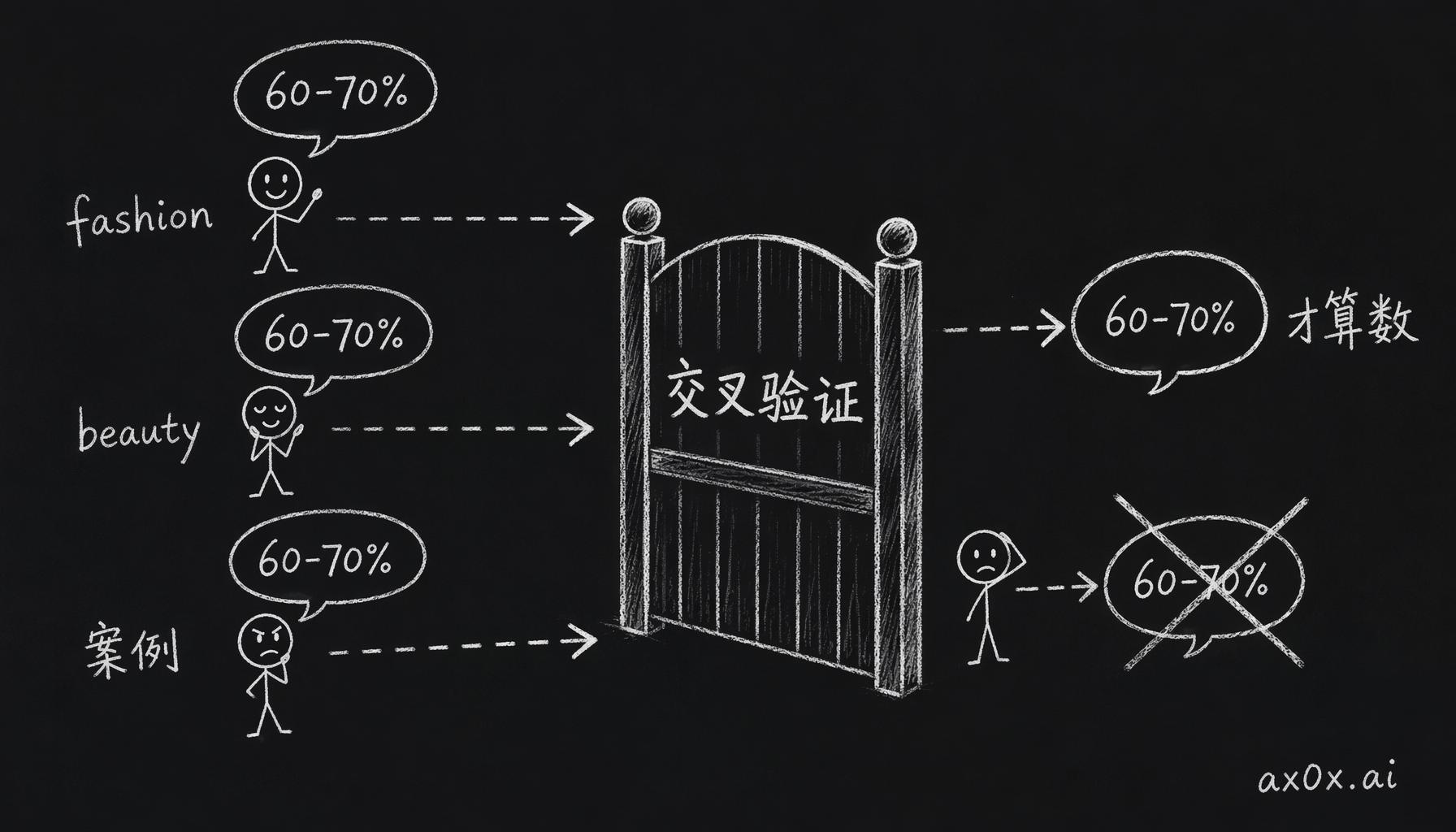 agent 会编数据——一个 agent 单独报的数字不算,要有第二个 agent 独立命中同一个数字才通过交叉验证
agent 会编数据——一个 agent 单独报的数字不算,要有第二个 agent 独立命中同一个数字才通过交叉验证
最后通过交叉验证站得住的几个数据点:
- OOTD 占 XHS 服饰商家内容的 60-70%,千瓜、jizhil、ebrun 独立命中
- 一衣多搭的转发率高 50%,jizhil 有个案例:刘小被儿用「10 套搭配 × 1 件牛仔外套」做到 220 万粉
- 李宁的火锅羽绒服靠「场景+产品+人物」的组合,在 XHS 双十一做到 30 万件、1 亿 GMV
- 护肤 routine 视频笔记的互动占比 51.32%,出自千瓜 2025 年报
- swatch 拼图是彩妆 XHS 的标配,五合一:品牌+唇+掌+指+勺,Colorkey 就是靠这一种形态跑出来的
10 个品牌的 post-mortem 还推翻了我一个直觉:头部商家很少发纯 hero 棚拍图,实际的爆款都是「产品+人+场景」的组合。所以 fashion 的独立 hero 槽直接砍掉了。
最后定下来的三套模板
服饰 6 张:OOTD 试穿、一衣多搭(四宫格)、场景化穿搭、平铺+上身图、前后对比(「显高 5cm」这种)、尺码建议(模特图叠字)。
美妆 6 张:产品主图、试色拼图(五合一)、使用前后对比、功效大字报、使用步骤(含 AM/PM)、合集榜单(TOP N / 红黑榜)。
珠宝 6 张:保持 Part 2 的原版不动。
基础设施还是共享的:三个品类的 6 张图走同一条 pipeline,API 调用、图片存储、UI 渲染这些都没动,变的只是 prompt 层的视觉语法。
砍掉了哪些候选
这轮迭代真正花时间的不是选了哪 6 个,是砍了哪些。有一堆听起来都挺合理的候选,最后砍掉了:
- 版型/做工微距:找不到头部商家的爆款证据,只有高端设计师品牌偶尔用
- 身高矩阵(155/160/165/170 同款对比):商家没有多模特预算,「小个子专精」是博主的 niche,不是商家模板
- moodboard 穿搭灵感拼贴:这是博主给自己立人设的工具,不是商家卖货的工具,「多套组合」的功能一衣多搭已经覆盖了
- 成分三栏 infographic:AI 画分子式容易糊,而且 HFP 这种以成分为卖点的品牌,实际做法是单页大字报,所以合并进功效大字报
- AM/PM 独立 routine:本质就是 routine 的一种,不值一个独立槽位
- 代言人东方美学大片:花西子那种 niche 高端玩法,普通商家抄不来
这些候选每一个单看都挺合理。最后定了一条规则来砍:一个模板要占一个槽位,研究里至少要找得到一个头部商家的爆款案例当证据,找不到就不进。「每品类严格 6 个」这条硬约束也在逼着我继续砍,放开到 8 个的话,上面这些大概全都会进去。
已知还没解决的
- 6+6+6 是 3 个 agent 的定性推断,不是千瓜订阅账号那种帖子级实测。等有用户之后,用 deselect 率加重生成率做 A/B 验证
- 「通用」兜底品类现在还挂在珠宝的 6 张上。文玩、香薰这类珠宝式的小物件没问题,将来要加食品、家居就得改
- 类型检查过了不等于 prompt 输出合格。10 个新 prompt 的实际产出还要过一轮本地 UAT,下一轮补一个新旧对比的 A/B smoke test
回头看 Part 2
Part 2 把 pipeline 抽象成「6 个槽位对应 6 个说服角度」。现在回头看,这个抽象在基础设施层是成立的:API 调用、图片存储、UI 渲染、类型系统、计费,这些在三个品类里长得一模一样,一份代码就够,实际也确实只写了一份。内容层就不是这么回事了,小红书的服饰、美妆、珠宝各说各的视觉语言,换个标签跨不过去,prompt 只能三个品类各写各的。
反正做这个产品到现在,大概每三四周就得推翻一次自己上一轮的判断。下一轮估计也免不了。


