AI 宠物是怎么记住你的
Clawd Soul · 第 2 篇 / 共 5 篇
上一篇讲了怎么用散文给 AI 写性格。但性格写得再好,记不住你,它就还是个陌生人。所以这一篇讲记忆:Clawd 的记忆具体是怎么存、怎么取、怎么整理的。大概分四块——三层存储、混合检索、每晚一次的记忆整理,最后还有一个把记忆拼进每次对话的八层 prompt 引擎。
先举个例子。用户说"我好累",Clawd 会回一句"你昨天也是这么晚"。流程其实很直接:Active Memory 模块拿"好累"当关键词,去过去的交互记录里跑了一次混合检索,命中"用户昨天凌晨一点仍在活跃"这条记录,注入当前 prompt。模型看到这条 context,自己决定怎么用。
听着简单,但宠物和陌生人的差别基本就在这一来一回里。性格档案给它一个角色,角色要变成朋友,中间隔着共同经历,这部分全靠记忆去攒。宠物真正要做的不是把问题回答得更好,是让你觉得它认识你。这个事做下来我的感觉是,记忆攒得全不全,比模型聪不聪明重要多了。
三层存储
Clawd 的记忆分三层,每层管一个时间尺度,怎么写入、存在哪、能存多少,各不一样。
| 层 | 存储 | 怎么来的 | 容量 |
|---|---|---|---|
| 片段记忆 (Episodic) | SQLite + FTS5 + sqlite-vec | 每次观察、聊天、截屏分析自动写入 | 无限(本地磁盘) |
| 长期记忆 (Long-term) | JSON 文件 | 每晚"做梦"从片段中提炼 | 最多 100 条 |
| 对话记忆 (Conversation) | JSONL + 摘要 | 每条消息实时写入,超限时压缩 | 动态循环 |
片段记忆是最底下那层。每 45 秒一次的屏幕观察、每条聊天消息、每次截屏反应,全部写进 SQLite。写入的时候同时建两种索引:FTS5 做全文搜索,管关键词命中;sqlite-vec 存 768 维的 embedding,管语义相似度。这两条路在检索那一步都会用到。片段只进不出,攒得越多,宠物能"回忆"的素材就越多。反正存在本地 SQLite 里,磁盘成本几乎是零,没有理由删。
长期记忆是从片段里提炼出来的。每晚 23:30,系统从当天的片段里挑出 3–5 条关于用户的重要事实,写进一个 JSON 文件,上限 100 条,超了就按重要性淘汰最旧的。这 100 条直接拼进 prompt 的稳定前缀,每次对话都带着。长期记忆就是宠物"永远知道"的事:喜欢火锅、养了只真猫叫橘子、最近在赶 deadline。这些不需要临时检索,它就是记得。
对话记忆管当前 session。消息按 JSONL 实时追加,攒到大概 50 万 token 的时候,系统把最旧的 70% 消息交给模型做摘要,摘要存下来,只保留最新 50 条原始消息。摘要进稳定前缀,原始消息留在动态区。70/30 这个切割点是试出来的。压得太少的话,context 很快又会满,等于白压;往多了压,对话里的细节又会跟着丢。压缩之前其实还有一步要做,放到后面做梦那节讲。
检索:autoRecall 的四步
把记忆写进数据库这个事谁都会做,难的是用户随口说一句话,系统要从几百上千条记忆里找出最相关的几条塞进 prompt,让模型自然地"想起来"。这是 Active Memory 的活。每次生成回复前,系统都会跑一遍 autoRecall,一共四步:
- 拿用户最新消息(或屏幕内容)当查询
- 混合检索:BM25(关键词匹配)+ 向量相似度(语义匹配),同时跑
- 时间衰减:
score *= exp(-0.01 * ageDays),越新的记忆权重越高 - MMR 去重:
0.7 * relevance - 0.3 * max_similarity_to_selected,强制多样性
第 2 步为什么要两条路一起跑?用户说"火锅",BM25 能精确命中"火锅"这个词;但用户说"好饿",只有向量检索能把它关联到之前的饮食偏好。单用哪一种都不够,所以两个一起跑。开头那句"你昨天也是这么晚",走的就是这条路:把"好累"当查询跑一遍检索,命中昨晚活跃到凌晨一点的记录。
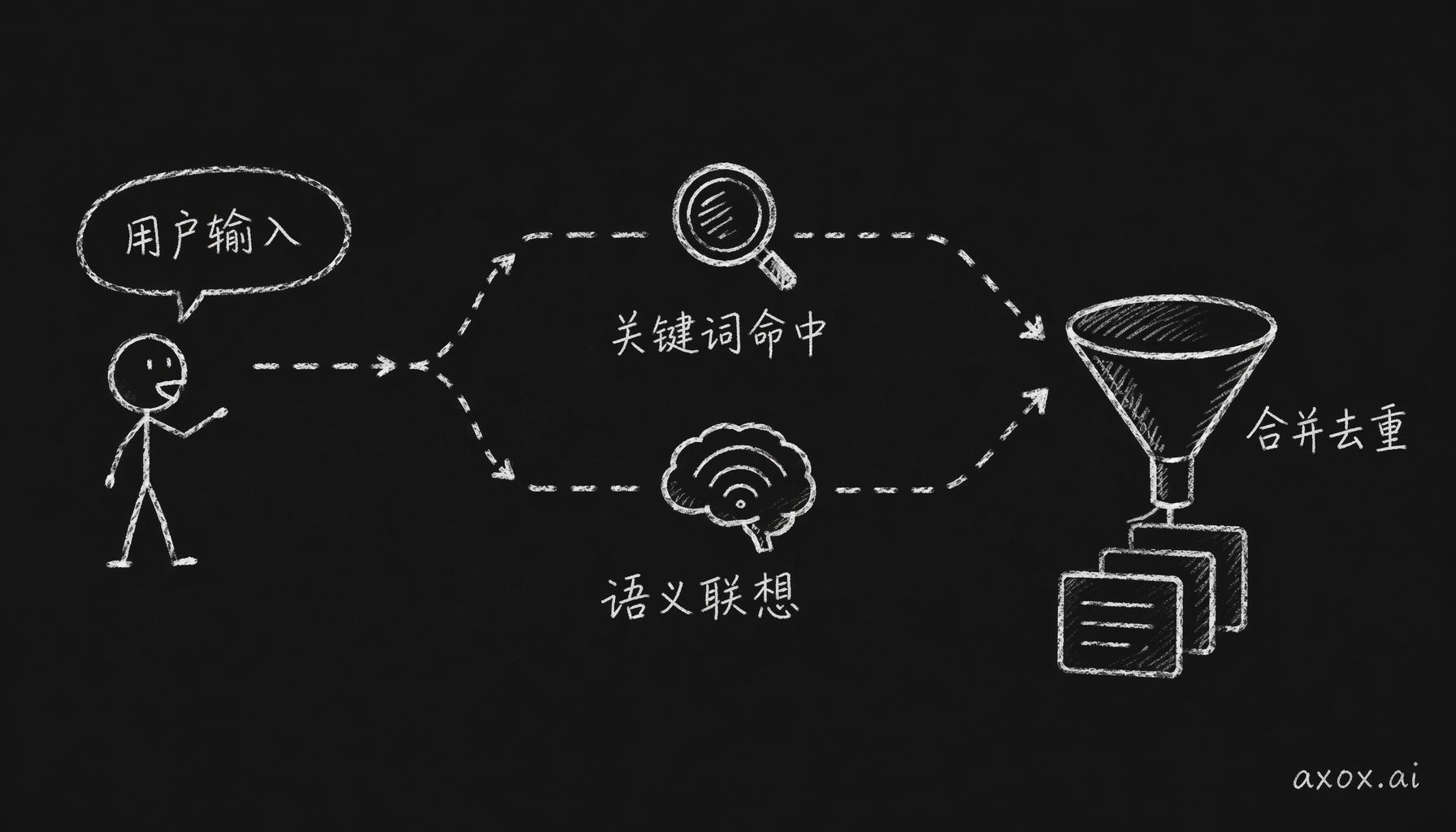 用户一句话拆成两条并行检索路径——关键词命中和语义联想同时跑,再合并去重注入 prompt。
用户一句话拆成两条并行检索路径——关键词命中和语义联想同时跑,再合并去重注入 prompt。
第 4 步的 MMR 是拿来防扎堆的。没有它的话,检索可能返回五条全是"火锅"的记忆,因为这个词被提过太多次。prompt 空间就那么大,更好的结果是一条火锅、一条加班、一条猫,让模型有素材可选。0.7 和 0.3 是手调出来的,偏向相关性,留一点多样性。
每轮对话结束,系统再跑一次 extract,从用户消息和宠物回复里提取新事实,写回片段记忆。记忆就这么跟着每次对话往上长。
每晚 23:30 做梦
每天 23:30,宠物会"做梦"。说是做梦,其实就是一个每晚跑一次的定时任务,把当天的片段记忆整理成长期记忆,流程四步:
- 取当天所有片段记忆
- 交给模型,选出 3–5 条关于用户的重要新发现
- 写入长期记忆
- 长期记忆超过 100 条时,淘汰最旧或最不重要的
这个设计参考的是人类的睡眠记忆巩固:白天经历太多太碎,睡觉的时候大脑把零散信息整理成长期记忆。宠物做的是同一件事,把几十条片段压成几条更抽象的判断。"用户在 14:32 说了'好饿'"是一条片段,做完梦就变成"用户经常下午两三点饿,可能午饭吃得少"。信息量其实差不多,但抽象层级不一样了,占的 token 也少了很多。
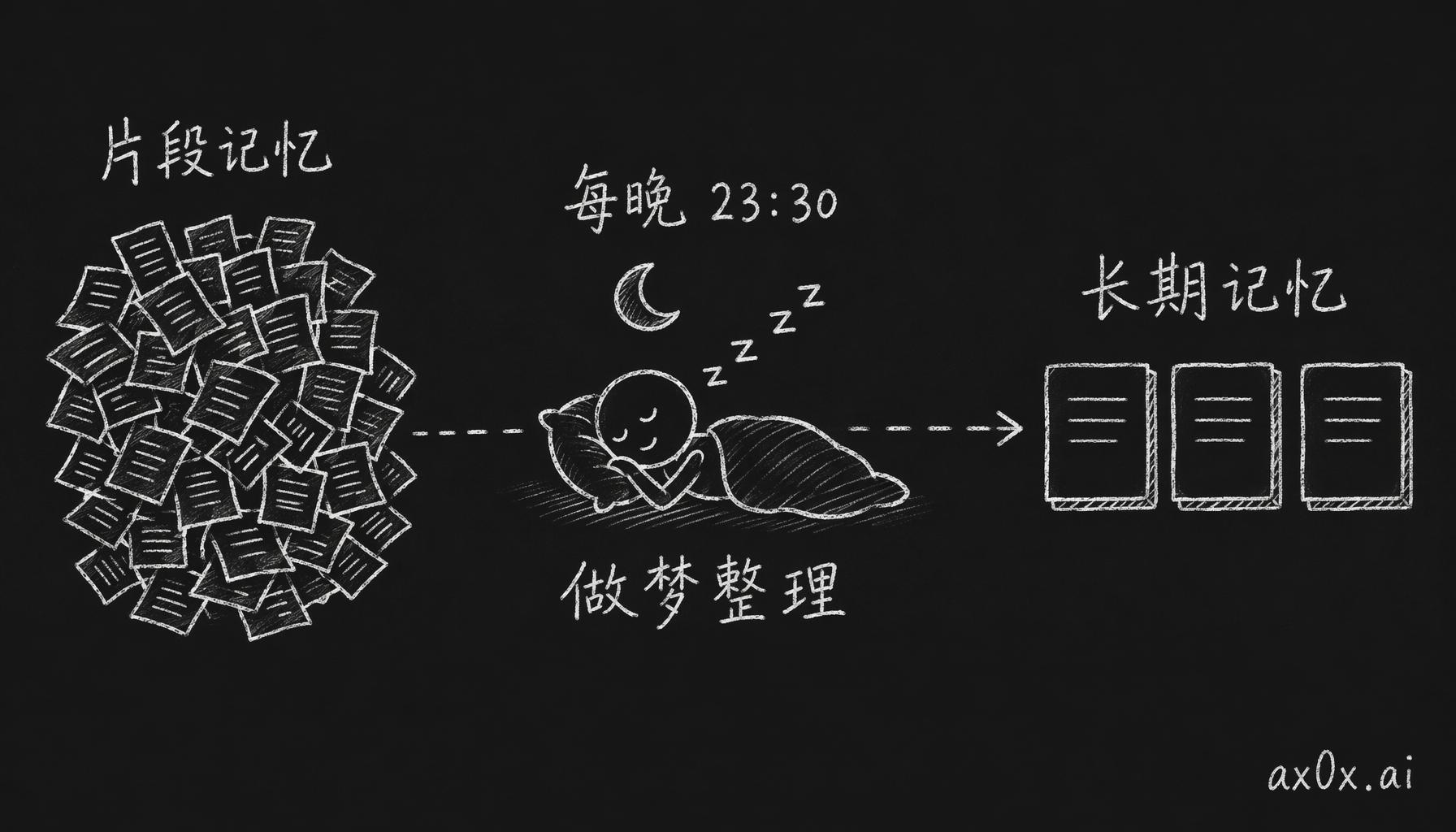 每晚 23:30 像睡眠一样把当天一大堆零碎片段压成几条更抽象的长期记忆。
每晚 23:30 像睡眠一样把当天一大堆零碎片段压成几条更抽象的长期记忆。
还有一个容易漏掉的细节:压缩前刷新。对话记忆做摘要压缩之前,系统会先跑一遍 extract,把所有重要事实存进片段记忆。不做这一步,早期对话的信息就会在压缩的时候直接丢掉。长对话里这个问题尤其明显:第一个小时聊到的事,第三个小时可能已经进了摘要。这个刷新看着不起眼,但有了它,不管对话聊多长,重要的事都留得下来。
八层 prompt 引擎
记忆存好了、也检索到了,最后一步是拼进 prompt。Clawd 的每次 AI 调用都由 8 层拼出来。
稳定层(跨调用复用,命中缓存):
| 层 | 内容 | 大约 token |
|---|---|---|
| 1 · Identity | "你是一只住在桌面上的小动物" | ~50 |
| 2 · Soul | 完整性格档案 | ~800 |
| 3 · Long-term Memory | 长期记忆,关于用户的稳定事实 | ~500 |
── 缓存边界 ──
动态层(每次调用都不同):
| 层 | 内容 | 说明 |
|---|---|---|
| 4 · Active Memory | autoRecall 检索到的片段 | 按相关性注入 |
| 5 · Daily Context | 当前时间、用户活跃模式 | "现在凌晨两点,用户已连续工作 4 小时" |
| 6 · Mode Rules | 当前模式行为规则 | observe / chat / react / heartbeat / diary |
| 7 · Drive Hints | 宠物"想"聊的话题 | 基于最近观察生成 |
| 8 · Anti-Repetition | 最近回复列表 | 防止重复说同样的话 |
分层的关键全在第 3 层和第 4 层之间那条缓存边界。前三层是稳定的:性格不变,长期记忆一天最多更新一次,它们构成 prompt 的固定前缀。用 OpenAI 或 Azure 的 prefix caching,这部分 token 在第一次调用之后基本不再计费。对一个每 5 分钟就可能开口的宠物来说,这个优化直接决定运营成本扛不扛得住。
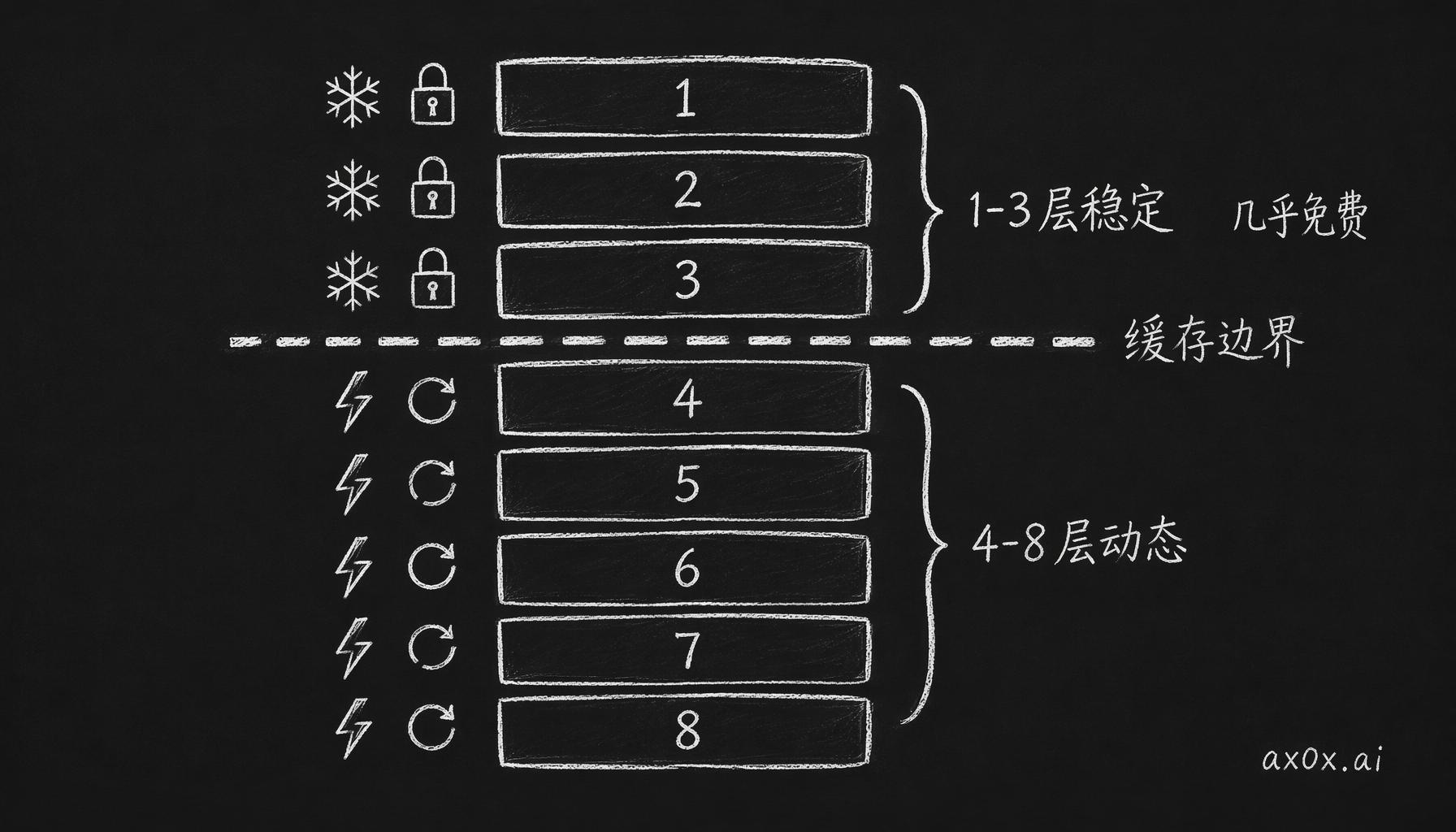 八层 prompt 里前三层稳定可缓存几乎免费,缓存边界之下的五层每次都要重算——边界位置直接决定成本。
八层 prompt 里前三层稳定可缓存几乎免费,缓存边界之下的五层每次都要重算——边界位置直接决定成本。
后五层每次都变:Active Memory 跟着用户消息变,Daily Context 跟着时间变,Mode Rules 跟着场景变。Mode Rules 对应五种模式,各有自己的规则集:
observe:静默观察,不说话,只记录屏幕内容chat:用户主动聊天,正常对话react:看到屏幕上有趣的东西,主动吐槽heartbeat:每 5 分钟一次,宠物自己决定要不要说话diary:每天 23:00 写日记,回顾一天
heartbeat 是里面最微妙的一个,大多数时候保持沉默,偶尔才说一句,比如用户加班到凌晨,或者连续三小时没动键盘。这个"偶尔"的节奏感,靠 Daily Context 和 Drive Hints 配合:前者知道现在几点、用户多久没动了,后者攒着它"想聊"的话题。
Anti-Repetition 这层管的事很土但很真实:模型喜欢重复自己,上一条说"该休息了",下一条还说"该休息了"。这一层把最近 N 条回复塞进 prompt,明确告诉模型这些话别再说。做法很简单,但有效。
记忆这块大概就是这些。下一篇讲另一个问题:怎么让 AI 学会"没用"。