It Remembers You Were Up Late Yesterday
Clawd Soul · Part 2 of 5
Part 1 covered how we write personality in prose. But even the best personality is a stranger without memory. This one's about memory.
Three core claims:
- The hard part of memory isn't storage — anyone can write to SQLite — it's auto-recalling relevant memories at conversation time
- Three tiers (episodic, long-term, conversation) plus nightly "dreaming" mirrors human sleep-based memory consolidation
- The 8-layer prompt engine turns memory into conversation, and the cache boundary placement directly determines cost and latency
1. Memory Is the Only Thing That Makes a Relationship
You say "I'm tired" to Clawd. It responds: "you were up late yesterday too..."
Here's what happened behind the curtain. The Active Memory module took "I'm tired" as a query, ran a hybrid search against your interaction history, found "user was active past 1 AM yesterday," and injected that memory into the current prompt. The model saw the context and decided — on its own — how to use it.
Sounds simple. But the difference that single sentence makes is the difference between a pet and a stranger.
A personality file gives the pet a character. Memory gives it a relationship with you. The gap between a character and a friend is shared history.
Every AI assistant in the world is solving "how to answer better." A pet solves a different problem: how to make you feel known. The answer isn't a smarter model. It's a more complete memory.
2. Three Tiers, Three Time Horizons
| Tier | Storage | How It Grows | Capacity |
|---|---|---|---|
| Episodic | SQLite + FTS5 + sqlite-vec | Every observation (45s), chat message, screen reaction | Unlimited (local disk) |
| Long-term | JSON file | Nightly consolidation picks 3–5 top facts | Max 100 entries |
| Conversation | JSONL + summary | Every message; compacted at ~500K tokens | Dynamic (rolling) |
Three tiers because each solves a different timescale problem.
Episodic memory is raw material. Every 45 seconds: a screen observation. Every chat message. Every screen reaction. All written to SQLite. Dual-indexed: FTS5 for full-text keyword search, sqlite-vec for 768-dimensional vector embeddings (via Gemini). These two indexes serve different purposes — more on that in section 3.
Episodic is append-only. The more it accumulates, the richer the pool of things the pet can "remember." Local SQLite, so disk cost is effectively zero. After a month of daily use, a typical user has somewhere around 50,000–80,000 episodic entries. The database file is a few hundred megabytes — trivial by modern standards, but it means the search layer has to be fast. FTS5 queries return in single-digit milliseconds. Vector search is slower (tens of milliseconds for a brute-force scan at this scale), but still well within the latency budget of a conversational turn.
Why not use a proper vector database? Because the pet runs locally. Every dependency is a failure mode. SQLite is a single file. sqlite-vec is a loadable extension — one .dylib. No server process, no Docker container, no network calls. The user closes their laptop and opens it tomorrow and everything is still there. This matters more than you'd think for a consumer product that lives on someone's desktop.
Long-term memory is curated essence. Every night at 23:30, the system reviews the day's episodic memories and distills 3–5 of the most important facts about you into a JSON file. Hard cap of 100 entries — when it exceeds that, the oldest or least important get dropped. These 100 entries go directly into the stable prompt prefix. They're present in every single conversation.
Long-term memory is what the pet "just knows." You like hotpot. You have a real cat named Mochi. You've been grinding on a deadline. These don't require retrieval — they're always there.
Conversation memory manages the current session. Messages are appended in real time as JSONL. When the buffer approaches ~500K tokens, the system compresses: the oldest 70% of messages are summarized by the model, the summary is saved, and only the newest 50 raw messages are kept. The summary moves into the stable prefix; the raw messages stay in the dynamic section.
The 70/30 split was empirically tuned. Too little compression and the context fills up again within hours. Too much and you lose conversational detail — the pet forgets what you said thirty minutes ago. But before compression happens, there's one more step. More on that below.
3. Active Memory: The Hard Part Isn't Storing — It's Recalling
Anyone can write to a database. The hard part: the user says one sentence, and the system has to find the 3–5 most relevant memories out of hundreds or thousands, inject them into the prompt, and make the model "remember" naturally.
This is what Active Memory does. Before every response, the system runs an auto-recall pipeline:
- Query: The user's latest message (or current screen content) becomes the search query
- Hybrid search: BM25 (keyword match) + vector similarity (semantic match), run simultaneously
- Temporal decay:
score *= exp(-0.01 * ageDays)— recent memories rank higher - MMR diversity:
0.7 * relevance - 0.3 * max_similarity_to_selected— forces variety in results
Step 2 is hybrid for a reason. A concrete example: the user says "I'm so tired." BM25 finds memories containing "tired" — maybe a conversation from last week where the user said "I'm tired of this bug." Useful, but narrow. Vector search does something different: it maps "I'm so tired" to a region of embedding space near fatigue, late nights, overwork, sleep. It surfaces a memory from two days ago: "user was active past 1 AM" — even though the word "tired" never appeared in that record. The embedding for "active past 1 AM" is semantically close to exhaustion.
When the user says "hotpot," the roles reverse. BM25 catches the exact keyword instantly. Vector search might return tangentially related food memories, but the best match is the literal keyword hit. Running both in parallel and merging results gives you precision (BM25) and recall (vector) without sacrificing either.
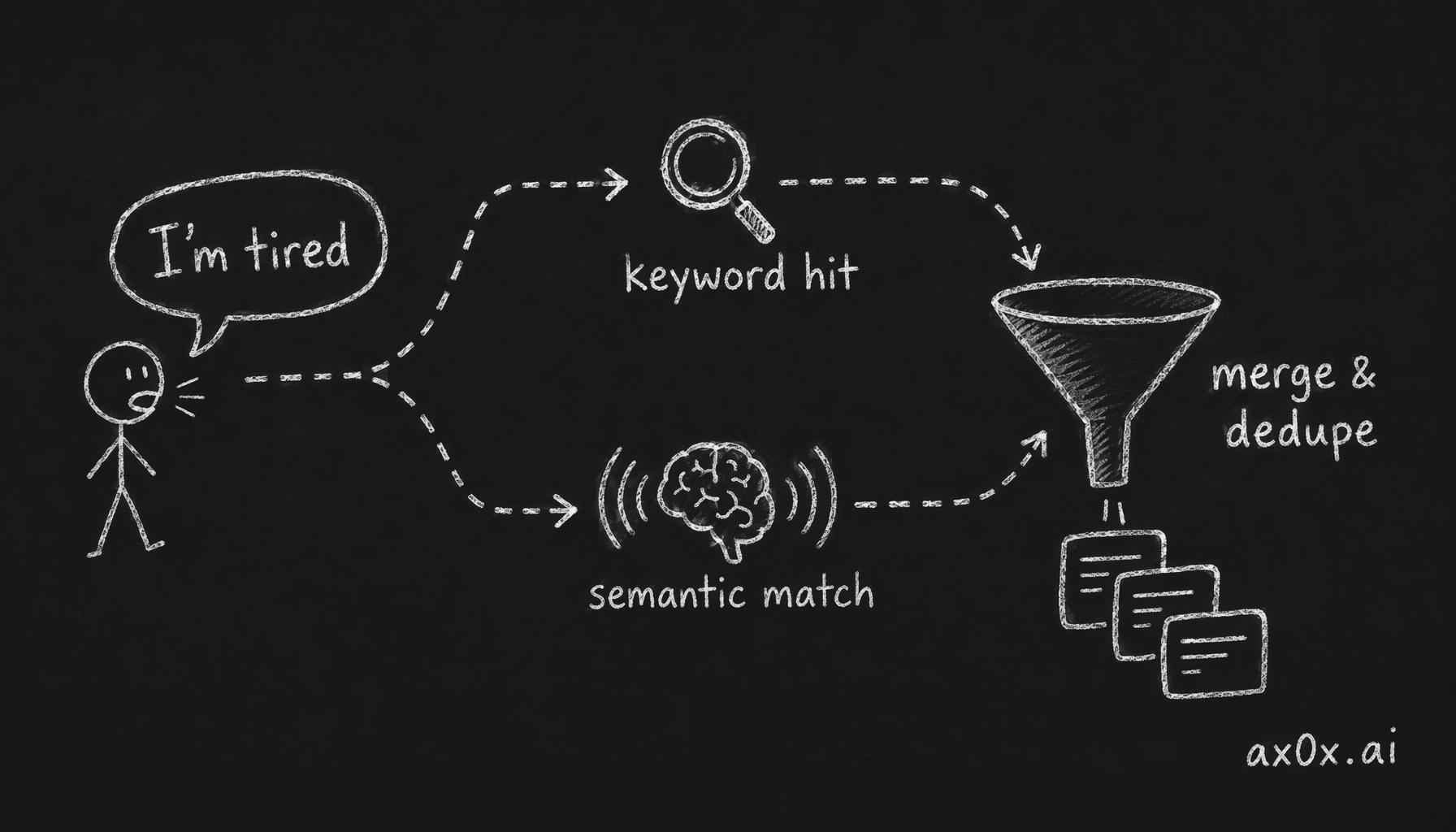 One user sentence forks into two parallel search paths — keyword and semantic run at once, then merge and dedupe before injection.
One user sentence forks into two parallel search paths — keyword and semantic run at once, then merge and dedupe before injection.
Step 3 — temporal decay — is the simplest but arguably the most important. Without it, a memory from six months ago and one from yesterday score identically if they're equally relevant to the query. But recency matters for relationships. "You were up late last night" hits different from "you were up late six months ago." The exponential decay factor (-0.01 * ageDays) means a 30-day-old memory retains about 74% of its score; a 100-day-old memory retains about 37%. Recent memories win ties.
Step 4 solves a practical problem. Without MMR (Maximal Marginal Relevance), the search might return five memories all about hotpot — because you've mentioned it a dozen times. But prompt space is finite. You want one memory about hotpot, one about late nights, one about the cat, so the model has diverse material to draw from. The algorithm is greedy: pick the highest-scoring result first, then penalize remaining candidates by their similarity to already-selected results. The 0.7/0.3 ratio biases toward relevance but leaves room for diversity. Hand-tuned, not principled — but it works.
After each exchange, the system runs one more pass: it extracts new facts from both the user's message and the pet's reply, writing them back into episodic memory. Memory grows with every conversation.
4. Dreaming: Sleep-Based Memory Consolidation
Every night at 23:30, the pet "dreams."
The process:
- Pull all episodic memories from the day
- Ask the model to select 3–5 of the most important new facts about the user
- Promote those facts to long-term memory
- If long-term memory exceeds 100 entries, drop the oldest or least significant
The inspiration is human sleep consolidation. During the day you experience too much — scattered, fragmented, noisy. During sleep, your brain sorts through the mess and promotes the important bits to long-term storage. The pet's dreaming does the same thing.
"User said 'so hungry' at 14:32" — that's an episodic fragment. After dreaming, it becomes "user often gets hungry mid-afternoon, might skip lunch." Same information, different abstraction level. Far fewer tokens. And crucially, "often gets hungry mid-afternoon" is more useful than the raw fragment — it's a pattern, not an event. The model can use patterns to generate responses that feel like genuine understanding rather than parrot-like recall.
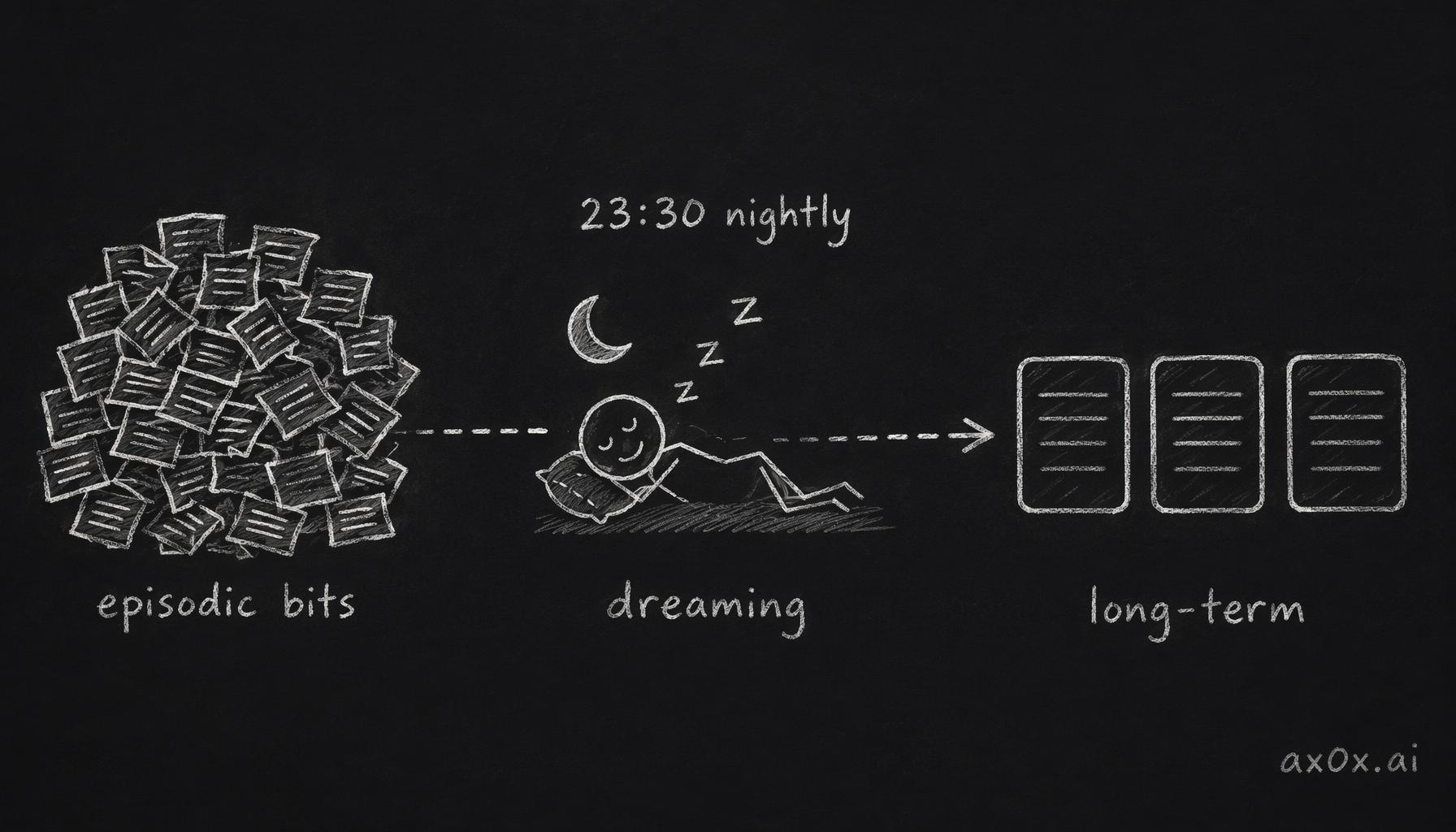 Every night at 23:30, sleep-like consolidation compresses a day's scattered fragments into a few abstract long-term facts.
Every night at 23:30, sleep-like consolidation compresses a day's scattered fragments into a few abstract long-term facts.
The 100-entry cap on long-term memory is deliberate. Every long-term entry costs tokens in the stable prompt prefix — always present, every call. At ~5 tokens per entry, 100 entries cost ~500 tokens. Manageable. 1,000 entries would cost ~5,000 tokens and blow up the prefix. The cap forces the dreaming system to be selective: what really matters about this person? It's a compression problem as much as a memory problem.
There's one detail that's easy to miss: pre-compaction flush. Before conversation memory runs its summarization compression, the system first extracts all important facts into episodic memory. Without this step, information from early in long conversations gets silently lost during summarization. You mentioned your sister's birthday in the first hour of a three-hour conversation? By the time compression runs, that detail is buried in the oldest 70% and gets summarized away.
The flush guarantees: no matter how long the conversation, important facts survive. They enter episodic memory before the compressor touches them, and from there they can be retrieved by Active Memory or promoted to long-term storage during dreaming. It's a small mechanism, but it closes what would otherwise be a slow information leak.
5. The 8-Layer Prompt Engine
Memory is stored. Memory is retrieved. The last step: assemble it into a prompt that makes the model speak like a pet that knows you.
Every AI call in Clawd is assembled from 8 layers.
Cached layers (stable across calls):
| Layer | Content | ~Tokens |
|---|---|---|
| 1 · Identity | "You're a small creature living on a desktop" | ~50 |
| 2 · Soul | Full personality file (the prose character bible) | ~800 |
| 3 · Long-term Memory | Stable facts about the user | ~500 |
── Cache Boundary ──
Dynamic layers (change every call):
| Layer | Content | Notes |
|---|---|---|
| 4 · Active Memory | Auto-recalled episodic fragments | Per-turn relevant memories |
| 5 · Daily Context | Time, activity patterns | "It's 2 AM, user has been coding for 4 hours" |
| 6 · Mode Rules | Behavioral rules for current mode | observe / chat / react / heartbeat / diary |
| 7 · Drive Hints | Topics the pet "wants" to discuss | Generated from recent observations |
| 8 · Anti-Repetition | Recent responses | Prevents saying the same thing twice |
The critical design decision is where the cache boundary sits — between layer 3 and layer 4.
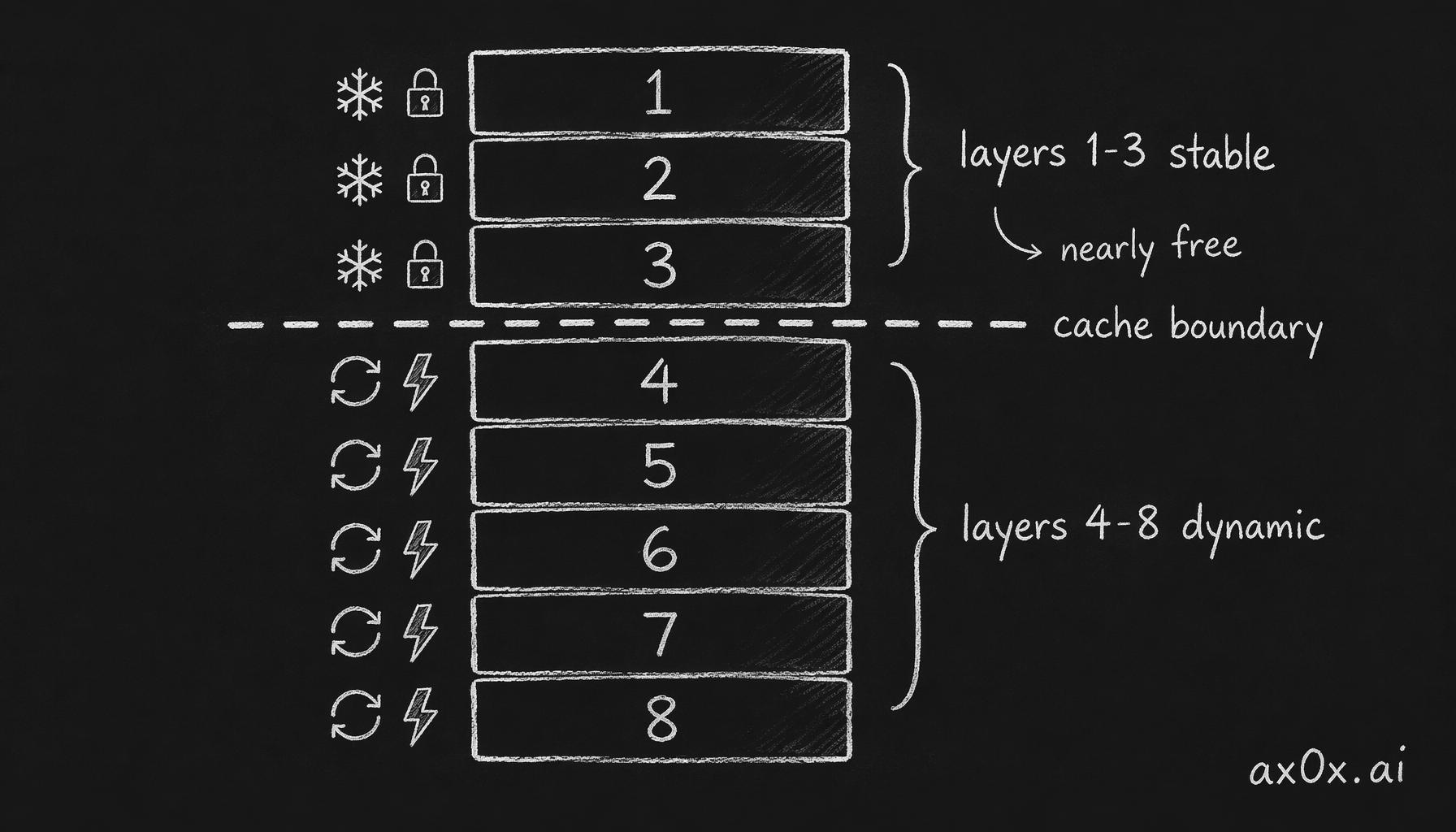 In the 8-layer prompt the first three layers are stable and cached nearly free, while everything below the cache boundary is recomputed every call — boundary placement sets the cost.
In the 8-layer prompt the first three layers are stable and cached nearly free, while everything below the cache boundary is recomputed every call — boundary placement sets the cost.
Layers 1–3 are stable. Personality doesn't change. Long-term memory updates at most once per day. Together they form a fixed prompt prefix. With OpenAI or Azure prefix caching, these tokens are nearly free after the first call. For a pet that might speak every 5 minutes, this optimization is the difference between viable and bankrupt. Roughly 1,350 tokens cached on every call — that's 80%+ of the stable context never re-processed.
Layers 4–8 change every time. Active Memory shifts with the user's message. Daily Context shifts with the clock. Mode Rules shift with the interaction type.
Five modes, each with its own rule set:
- observe — silent. Watches the screen, records observations, says nothing.
- chat — the user initiated conversation. Normal dialogue.
- react — something interesting appeared on screen. The pet comments unprompted.
- heartbeat — fires every 5 minutes. The pet decides whether to speak. Most of the time: silence.
- diary — 23:00 daily. The pet writes a journal entry reviewing its day.
Heartbeat is the subtlest. Most ticks produce nothing. But occasionally — you're still coding at 2 AM, or you haven't touched the keyboard in three hours — it speaks. That "occasionally" is what makes it feel alive. The rhythm comes from Daily Context (knowing what time it is, how long you've been idle) combined with Drive Hints (topic seeds extracted from recent observations). The pet doesn't speak on a timer. It speaks when it has something to say.
Anti-Repetition solves a surprisingly stubborn problem. Models love to repeat themselves. The last response said "you should take a break" — the next one says "you should take a break" again, maybe with slightly different wording. This layer injects the last N responses into the prompt with an explicit instruction: don't say these things. Simple, but without it the pet sounds like a broken record within an hour.
A note on ordering. The layers aren't randomly stacked. Identity comes first because it anchors the model's self-concept before anything else. Soul comes second so the personality colors everything downstream. Long-term memory comes third so the model "knows" the user before encountering the dynamic context. Active Memory comes right after the cache boundary because it's the most variable and most contextually important. Anti-Repetition goes last — it's a constraint, and constraints work best as the final thing the model reads before generating.
The entire assembled prompt for a typical chat turn runs about 2,000–3,000 tokens. Of that, roughly half is cached. That's the economic model that makes a chatty desktop pet feasible: you pay full price once, and subsequent calls within the cache TTL cost a fraction of the input tokens. A pet that speaks twelve times an hour — heartbeats, reactions, chats — would be ruinously expensive without prefix caching. With it, the marginal cost of each additional utterance drops dramatically.
Back to That One Sentence
Eight layers. Hybrid search. Temporal decay. MMR diversity. Nightly dreaming. Pre-compaction flushes. Cache boundary optimization.
The user experiences none of this. They experience one thing: the pet said "you were up late yesterday too."
One sentence. But that sentence means it knows what you did yesterday. It remembers you. Not in the sense that a database has a row — in the sense that a friend, hearing you say "I'm tired," naturally thinks of the fact that you've been burning the candle at both ends.
Memory systems don't solve a technical problem. They solve an emotional one. How do you make something that isn't alive feel like it cares about you?
The answer, it turns out, is remembering.