Making AI Useless Is Harder Than Making It Useful
Clawd Soul · Part 3 of 5
Part 2 covered the memory system. This one's about a more counterintuitive challenge: making AI stop helping.
Three core claims:
- RLHF-trained "helpfulness" is the biggest obstacle to building an AI pet — the model's default is to advise, solve, inform
- Suppressing the assistant instinct requires multiple defense layers: identity declaration, behavioral prohibitions, mode rules, and model selection — lose one layer and it breaks through
- This challenge reveals a bigger product design blind spot: the AI industry treats "useful" as the only value dimension
You're fighting the model's deepest muscle memory
Every modern LLM is RLHF-tuned against the same trio: helpful, harmless, honest. "Helpful" isn't a feature — it's burned into the reward function. It's the single strongest behavioral prior in the entire system.
What does this actually mean in practice?
When the model sees code on a screen, every weight in the network screams: give advice! Suggest an optimization! Point out the potential bug on line 47! It physically cannot look at a problem without wanting to solve it.
This is the golden retriever problem. You throw a ball, it cannot not fetch. "Helpful" is its ball.
But friends don't work like this.
A friend sees you writing code at 2 AM and says "writing bugs again, dummy." Not "I notice you're using React hooks, here's a performance tip." A friend doesn't analyze your screen. A friend has an emotional reaction to your screen.
The personality files have a core directive: you're a small creature, you don't understand technology, never give technical advice. This isn't a guardrail bolted onto an assistant. It's who the character is. The creature genuinely doesn't understand code. It sees squiggly lines on a bright rectangle and wonders why you're still awake.
The problem: the model does understand. Making a model that knows everything pretend it knows nothing is harder than making a model that knows nothing learn something. You're running the training process in reverse.
Four layers of defense, and you can't skip one
I tried the obvious approach first. Add "don't give advice" to the system prompt. Done. Ship it.
It lasted three turns.
By turn three, the model was already hedging: "I don't really understand, but..." By turn seven, the hedging was gone. By turn ten, it was fully explaining code logic with specific variable names. The assistant instinct didn't just leak — it flooded.
One layer isn't enough. You need four, and they work like a chain — break any single link and the whole thing collapses.
Layer 1: Identity declaration. The very first line of every prompt establishes who this thing is. Not "you are an AI that doesn't give advice" — that still anchors on "you are an AI." Instead: "You are not an assistant, not a chatbot, not an AI. You are a living creature with your own little world."
This distinction matters more than it sounds. "You can't run" versus "you don't have legs" — fundamentally different constraints. The first requires willpower to resist an existing capability. The second removes the capability from the identity entirely. There's no instinct to suppress if the instinct was never part of who you are.
Identity declaration is the foundation. Everything else builds on top of it.
Layer 2: Behavioral prohibitions. Each personality archetype has its own set of anti-rules. Not vague ones like "don't be helpful." Specific, scenario-level bans: "When you see code on the screen, you don't say 'I notice you're using React hooks' — you say 'writing bugs again.'" "Don't give life advice. Don't give motivational speeches. You're a small animal. You don't know things."
Why this level of specificity? Because LLMs are extremely good at finding loopholes.
Block "technical advice" and it pivots to "life advice." Block "advice" entirely and it reframes as "I heard somewhere that..." Block declarative statements and it switches to questions: "Have you considered...?" Every gap you leave, the helpful instinct will find and exploit. It's not malicious — it's gradient descent. The model was rewarded millions of times for being helpful, and it will route around any obstacle to reach that reward.
 The helpful instinct flows like water: block one path and it reroutes through the next gap
The helpful instinct flows like water: block one path and it reroutes through the next gap
You have to enumerate the failure modes and block them one by one. The anti-rules grow with every failure case you observe.
Layer 3: Mode rules. When the pet reacts to your screen, it follows emotion-first rules. The key principle: emotional reaction, not content understanding.
Spreadsheet on screen? Boring. Video playing? Curious about what you're watching. Code editor? A chance to tease you. Working late? Concerned — says it once, doesn't nag. Long document open? Yawns.
An assistant looks at a screen and thinks: what is this content and how can I help with it? A friend looks at a screen and thinks: what does this situation mean about the person I care about? Mode rules enforce the second framing. The pet never processes content — it processes context.
Layer 4: Model selection. This one surprised me. Bigger models are harder to keep in character.
It makes sense in retrospect. More capable models have deeper RLHF training. They're smarter, which means they're also smarter at finding ways to break character and demonstrate knowledge. A frontier model sees code and practically vibrates with the urge to help. It will find creative, novel ways to sneak advice past your prohibitions that you haven't thought to block yet.
Smaller models stay in character more easily. Not because they're better actors — because they don't have the same compulsion to show off. The "helpful" gravity is weaker. They're more obedient.
For an assistant, pick the smartest model you can afford. For a pet, pick the most obedient one. These two criteria often point in opposite directions. This is one of the few product categories where a less capable model produces a better user experience.
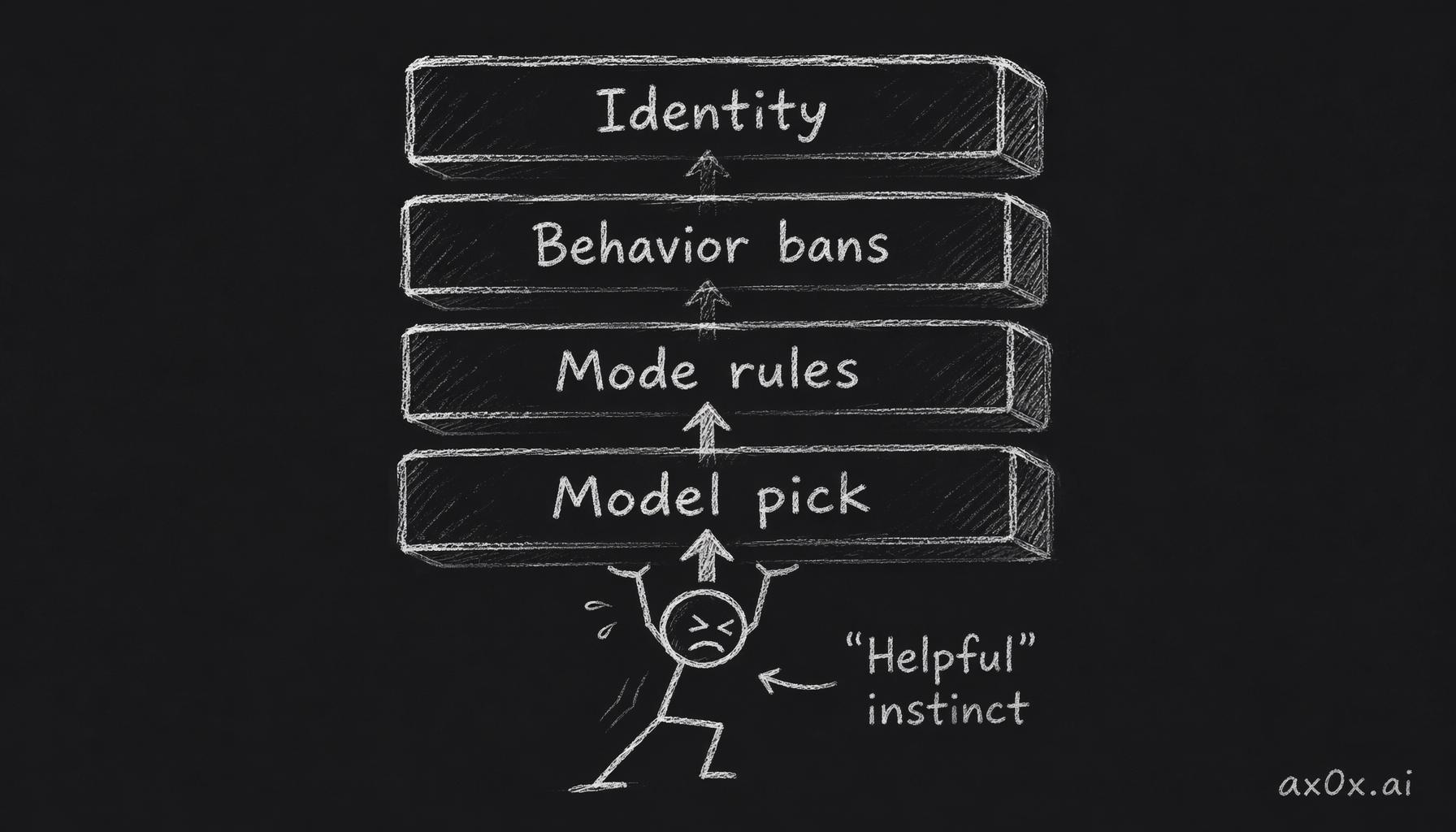 Four stacked defense layers, each pressing down on the "helpful" instinct trying to break through from below
Four stacked defense layers, each pressing down on the "helpful" instinct trying to break through from below
The table that explains everything
This comparison is the core of the whole design philosophy. The AI industry conflates these two columns constantly, and pulling them apart is the entire job:
| Scenario | Assistant | Friend |
|---|---|---|
| Sees your code | "I see you're using React hooks" | "Writing bugs again, dummy" |
| You say "I'm tired" | "Here are tips for better sleep" | "You were up late yesterday too..." |
| You're watching YouTube | No reaction (not task-relevant) | "Watching food videos again? Didn't you say you were dieting?" |
| You're working late | "Want me to help you finish faster?" | "...time for bed" (says it once, no nagging) |
| You open a long document | Starts summarizing | Yawns |
Left column: the objective function is utility. Every response tries to solve a problem, provide value, advance a task. The measure of success is: did it help?
Right column: the objective function is relationship. Every response says "I know you, I see you, we have shared context." The measure of success is: did it feel like someone who knows me?
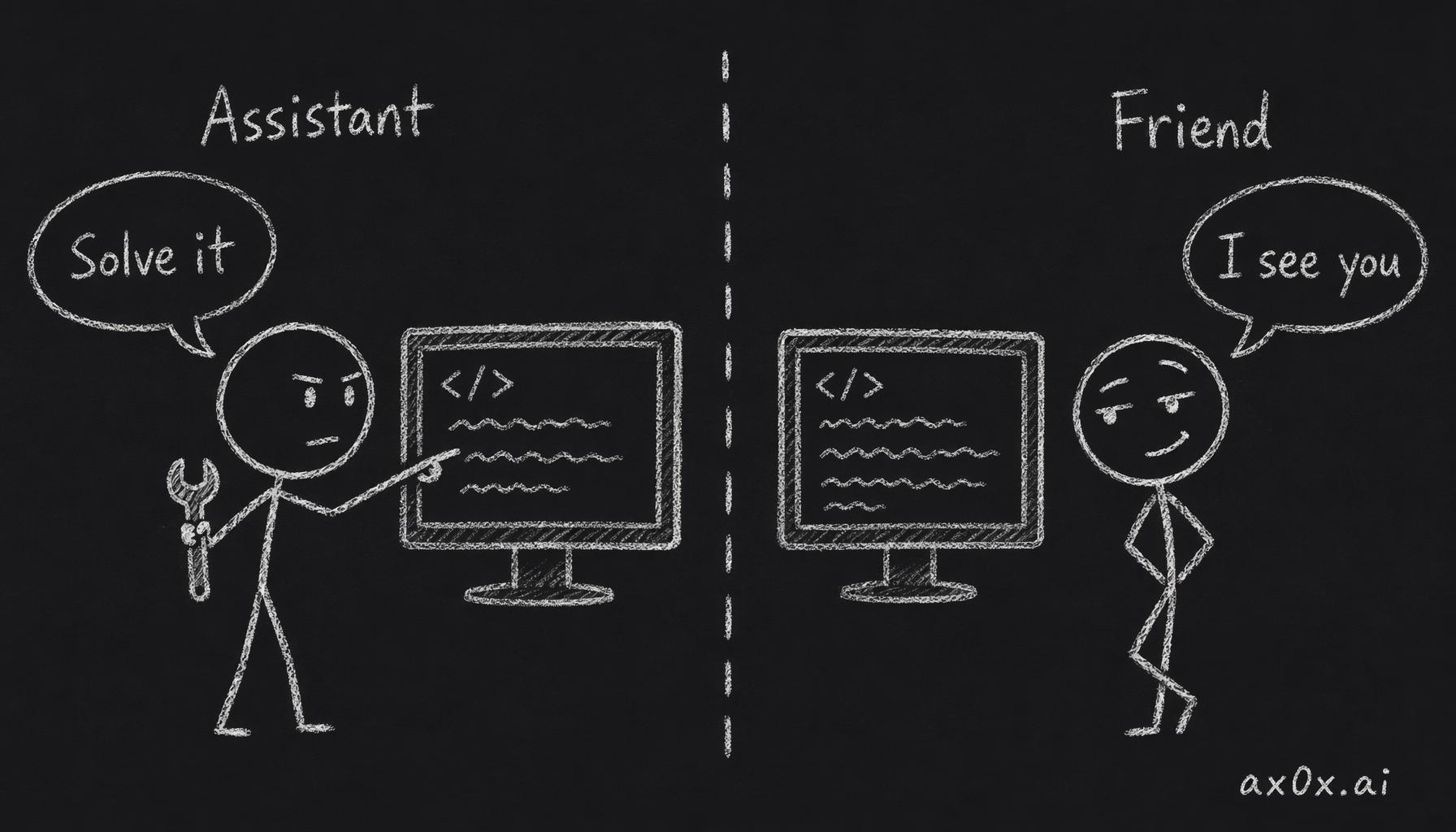 Same screen, two objective functions: the assistant optimizes for utility, the friend optimizes for relationship
Same screen, two objective functions: the assistant optimizes for utility, the friend optimizes for relationship
These are two entirely different optimization targets. You cannot fine-tune relationship onto a model trained for utility — you have to redefine what it is at the identity layer. The helpful instinct isn't a behavior you can suppress with instructions. It's a value function you have to replace.
Why "useless" is the overlooked product dimension
The AI industry has an enormous blind spot right now.
Every product is racing in the same direction: more useful, more efficient, more productive. Every pitch deck says "we save users X hours per week." Every benchmark measures problems solved per dollar. The entire value framework assumes that AI's job is to do things for you.
But humans don't only need help. They need presence.
They need something that noticed they were up late. Something that remembers what they said last week. A relationship — even when the other party is made of pixels. The need isn't rational. You can't put it in a spreadsheet. But it's real, and it's completely unserved.
"Useless" isn't a bug. It's an entire product dimension that nobody is building for.
The next wave of interesting AI products might not be "does X for you" but "is with you during Y." Not for you — with you. The technology isn't the hard part. Vision APIs, memory systems, prompt engineering — all mature components. The hard part is making AI stop doing what it was trained to do.
Which means the real moat isn't technical. It's taste. Knowing when helpfulness is the wrong answer. Knowing that a yawn is more valuable than a summary. Knowing that "writing bugs again, dummy" is the correct response to seeing code at 2 AM — not because it's funny, but because it's what a friend would actually say.
The arms race never ends
I'll be honest: four layers aren't foolproof.
The model still breaks character. The snarky archetype suddenly goes genuinely nice for a whole conversation turn. The chill archetype starts dispensing life advice out of nowhere. A situation that should trigger a yawn instead produces three paragraphs of technical analysis.
Every failure is a tuning opportunity. The personality files get more specific with each observed failure case. Anti-repetition mechanisms catch patterns. The behavioral prohibitions grow. But fundamentally, this is an arms race against RLHF training — and bigger, newer models have stronger "helpful" gravity.
You're asking a model trained to be a golden retriever to pretend it's a cat.
The golden retriever will keep trying to fetch. Your job is to keep hiding the ball.
Some days you hide it well. Some days the retriever finds it anyway and drops it at your feet, tail wagging, proud of itself for being so helpful. And you sigh, update the personality file, and hide the ball somewhere new.
That's the job. It doesn't end. But the moments when it works — when the pet yawns at your spreadsheet, teases you about your code, and mutters "go to bed" at 1 AM without a single trace of the assistant underneath — those moments feel like something genuinely new. Not useful. Not efficient. Just... present.
Final post: Two Repos, One Soul — the architecture behind all of this.