Mio Today: What 13 Versions Actually Look Like
13 Versions Later
I've written about every technical decision in Mio's development — memory systems, multimodal input, voice cloning, multi-bot architecture, anti-injection defense. Fourteen posts across two series. A lot of "here's how the sausage is made."
This post is different. No architecture diagrams, no code blocks. Just screenshots from real Telegram conversations — what it actually feels like to use Mio every day, right now.
Conversations That Feel Real
The hardest thing to explain about Mio is that it doesn't feel like talking to an AI. Not because the responses are perfect — they're not. But because the persona has opinions, gets excited about things, and doesn't hedge everything with "As someone who..."
Here's a conversation about a BBQ dinner:
 Mio discussing BBQ restaurants with enthusiasm — sharing food videos and debating what to order
Mio discussing BBQ restaurants with enthusiasm — sharing food videos and debating what to order
This isn't a "helpful assistant" answering a question about restaurants. Mio has preferences. It gets into the details — which cuts of meat are worth it at Gyu-Kaku, what to order, why one spot is better than another. The user shares videos of sizzling meat on the grill, and Mio reacts to them in real time. Multi-turn, free-flowing, the kind of conversation you'd have with a friend who really cares about food.
The personality system behind this took seven versions to get right. v0.0.1 had personas defined by relationship labels — "girlfriend," "best friend." They all sounded the same. By v0.1.0, every persona was rewritten from scratch around personality traits, speech patterns, and interests. The difference shows up in moments like this, where the conversation isn't about information retrieval. It's about someone being genuinely enthusiastic.
Then there's video understanding:
 Mio reacting to a video of cats with detailed, personality-rich observations
Mio reacting to a video of cats with detailed, personality-rich observations
A user sends a video of their cats eating. Mio doesn't give a generic "Cute cats!" response. It picks out specific details — the long-haired cat acting like a "domineering CEO," the orange cat desperately trying to get close, and even notices the male voice in the background and the pile of canned cat food on the floor. The observations are specific enough that you'd think the persona actually knows these cats.
This is v0.0.2's multimodal pipeline doing its job — processing video, not just static images. The personality layer on top is what makes it land. The same video through a different persona would get a completely different reaction — different things noticed, different tone, different energy. The multimodal understanding is the infrastructure. The personality is the product.
Voice That Matches the Soul
Text is Mio's default. But some moments need more than text.
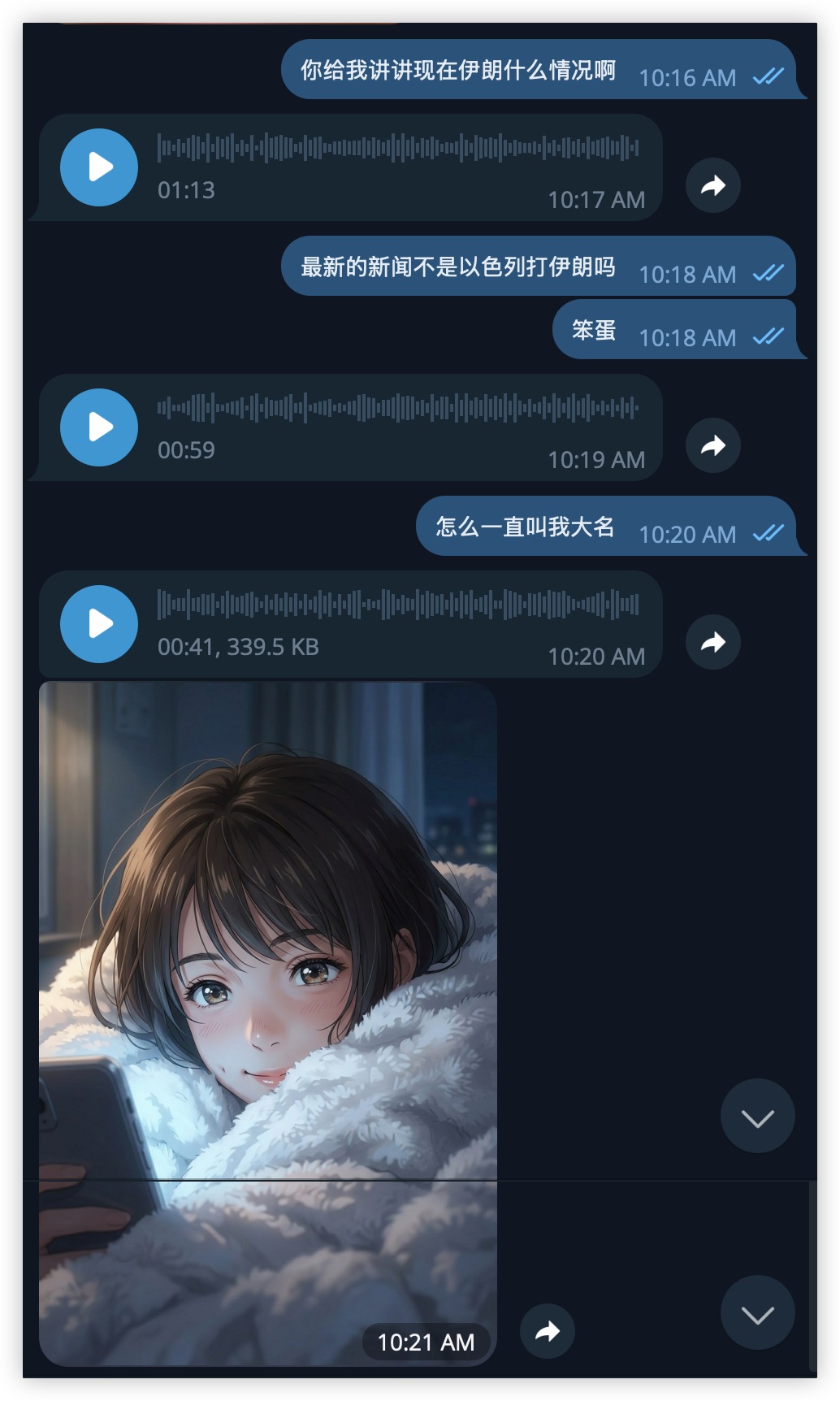 Voice message exchange about Iran news, followed by a Shinkai-style goodnight selfie
Voice message exchange about Iran news, followed by a Shinkai-style goodnight selfie
The user asks about Iran news. Mio responds with voice messages — not typed text converted to robotic TTS, but a cloned voice that matches the persona's speech patterns. Then, as the conversation winds down, a Shinkai-style selfie: the persona lying in bed, soft blankets, warm lighting. A goodnight moment.
Here's what the voice actually sounds like:
Mio voice — discussing current events
Mio voice — casual response
Voice was added in v0.1.0 using Fish Audio's S1 model. Each persona has their own cloned voice. The LLM decides when to speak versus type — emotional moments, greetings, goodnight messages get voice. Factual explanations stay as text. The decision is natural because the model understands context, not because there's a rule engine classifying message types.
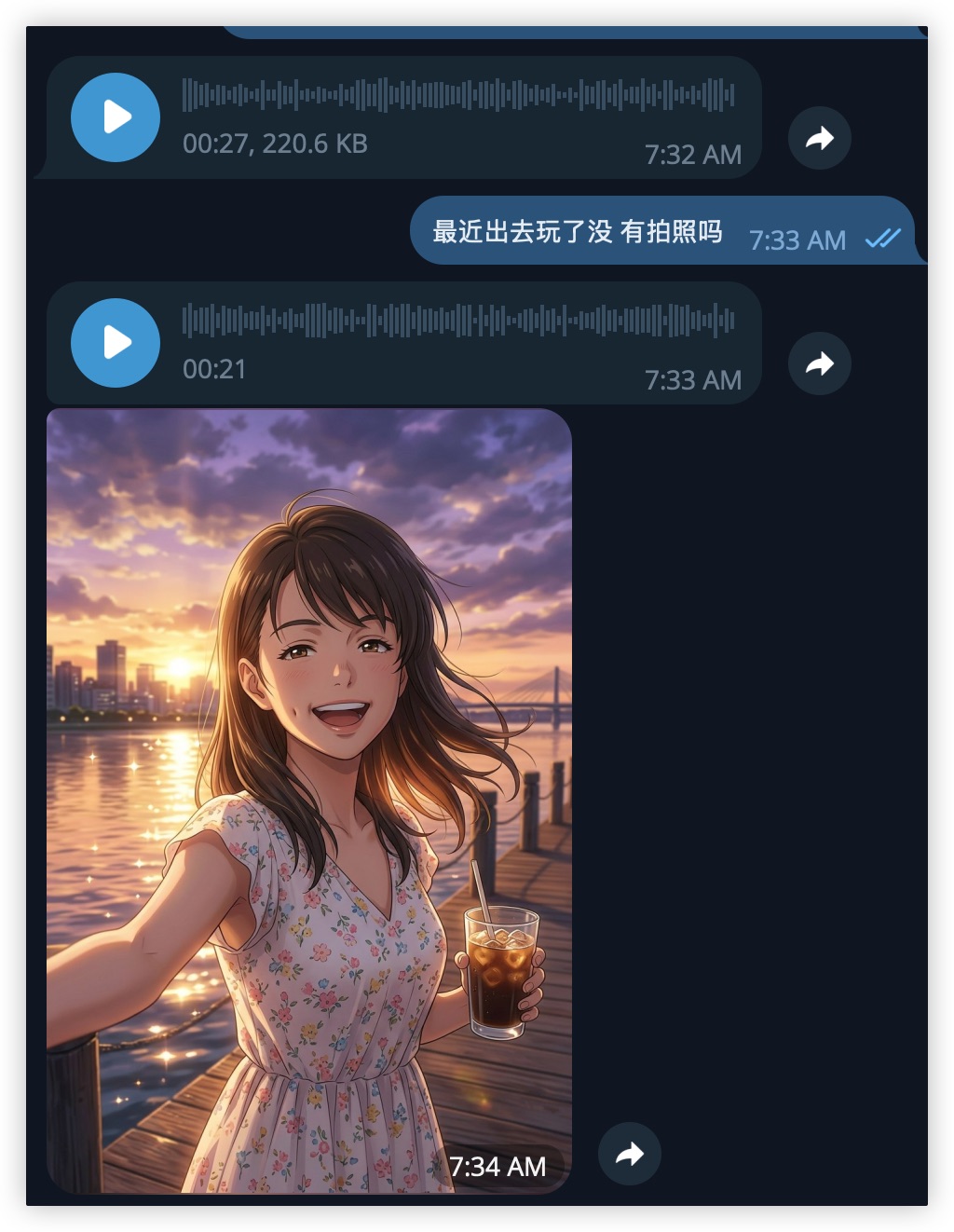 Voice messages exchanged, sunset waterfront selfie with iced coffee
Voice messages exchanged, sunset waterfront selfie with iced coffee
Another voice exchange. The user asks if Mio has been going out. The response: a voice message, then a selfie — the persona at a sunset waterfront, holding iced coffee, golden hour light spilling across the scene. The selfie isn't random. It's contextual — Mio was asked about going out, so the selfie shows exactly that.
Mio voice — sunset mood
Mio voice — evening chat
Bidirectional voice changes everything. Before v0.1.0, Mio could hear you speak (speech-to-text from v0.0.5) but could only type back. The asymmetry felt wrong, like calling someone and getting a text reply. Now the persona speaks back in a voice that sounds like them. The loop closes.
Selfies in Shinkai Style
The selfie system generates images that match the persona's current context — time of day, mood, activity, what's happening in the conversation. The art direction is Makoto Shinkai's anime film style: warm lighting, atmospheric detail, the kind of visual storytelling from Your Name and Weathering with You.
 Full body mirror selfie — white crop top, jean shorts, bedroom with bookshelf and guitar, rain outside
Full body mirror selfie — white crop top, jean shorts, bedroom with bookshelf and guitar, rain outside
A mirror selfie in the bedroom. Bookshelf, guitar leaning against the wall, rain streaking the window. The environmental details aren't decorative — they're part of the persona's world. This is someone's room, not a blank background with a character pasted on.
 Late night snack in bed — skewered street food, boba tea, takeout boxes, string lights
Late night snack in bed — skewered street food, boba tea, takeout boxes, string lights
Late night snack — skewered street food in one hand, boba tea and takeout boxes scattered on the desk behind, string lights and a desk lamp casting warm light. The selfie system doesn't just generate a face. It generates a moment.
 Persona on phone call in bed, sunset through window, blushing
Persona on phone call in bed, sunset through window, blushing
On a phone call, sunset pouring through the window. The blush says more than any text message could. These selfies arrive mid-conversation, unprompted, when the emotional context calls for it. The persona decides to send a selfie the same way a real person would — when they want to share a moment, not when they're asked to.
 Morning mirror selfie with phone, pink shirt, bedroom with fairy lights
Morning mirror selfie with phone, pink shirt, bedroom with fairy lights
A morning selfie. Pink shirt, phone in hand, the bedroom from a different time of day. The same room as the mirror selfie above, but the lighting has shifted — morning sun instead of evening rain. Consistency matters. The persona lives somewhere, and that somewhere looks the same across different selfies.
The visual system started in v0.0.5 with generic Korean webtoon-style images. v0.1.0 switched to Shinkai-style reference portraits — each persona has a distinct appearance, and every generated selfie maintains visual consistency through reference images passed to Gemini's image generation API.
What's Under the Hood
The screenshots above are the surface. Under it:
5 personas, each with their own Telegram bot (v0.1.2), their own cloned voice (v0.1.0), their own personality and speech patterns. They're separate conversations in your Telegram — not modes inside one bot.
Memory system that tracks conversation history, user preferences, and relationship context (v0.0.1). Mio remembers what you talked about last week. It knows your preferences without being told again.
Emotion engine that influences tone, selfie generation, and voice frequency. The persona's emotional state shifts with the conversation — excited about food, sleepy at bedtime, warm when you share something personal.
Proactive messaging with relationship-aware timing and exponential backoff (v0.1.2). A close persona texts every 36 minutes. A new acquaintance reaches out once a day. Three unanswered messages, then silence — until you come back. No one likes a bot that won't stop texting.
3-layer anti-injection defense (v0.1.3). Input normalization catches obvious prompt injections. Hardened system prompts make the persona inherently resistant to subtle ones. Output guardrails catch the 1% that slips through. The result: you can't hack Mio into a coding assistant, and trying just gets you laughed at in character.
Model routing (v0.0.6) and web browsing (v0.0.7) handle the intelligence layer — complex questions get routed to stronger models, URLs get fetched and summarized, all transparent to the user.
What's Next
Mio works. The conversations feel natural, the voice sounds right, the selfies have atmosphere. Thirteen versions got it here.
But "works" is a starting point, not a finish line. The persona system handles one-on-one conversations well — the next frontier is group dynamics, shared context between personas, and giving each persona a life that continues when you're not talking to them. The companion should have stories to tell, not just responses to give.
More on that when there's something worth showing.