当 AI 真的记住你说过的话
盘盘猫有一款 MBTI 人格测试,用对话来理解你:你的措辞、推理方式、碰到模糊问题时的反应。每一轮对话都是一次人格信号的采集,比勾选题问卷拿到的东西多得多。测试本身做得挺好,但有个致命问题:做完一次,下次 AI 就把你忘了。
用户聊了 20 分钟,坦白了职业困惑、感情纠结、对大厂机会的恐惧。关掉页面,下次回来还是那句"嗨,很高兴认识你!",跟初次见面一样。
我在AI 智能体随想里写过一个判断:记忆编排是 AI 伴侣的技术护城河。这里说的记忆,指对你这个人本身的理解:犹豫模式、情绪信号、嘴上说的和心里想的有什么不同,"我们聊过 X 话题"那种事实摘要不算数。99% 的对话是噪声,信号藏在语气里、在犹豫里、在回避里。盘盘猫的 MBTI 已经在采集这些信号了,只是采完就丢。写完那篇构想我就想:别光说了,做一个出来。
两个 feature,一条飞轮
设计很直觉。第一个 feature 是 MBTI 长期记忆:每次完成测试,AI 在后台把对话浓缩成一份结构化摘要,提取行为模式、情绪基调、关键语录、未解决的内心冲突这些人格信号,逐字记录不往里存。摘要再合并进一个中心化的人格画像。画像大概 400 个 token,不长,足够让 AI 在下次对话时"认识你"。
画像里有两类特殊字段:memorableDetails 存具体的故事片段,unresolvedThreads 存欲言又止的话题。这两类字段对人格分析帮助不大,作用是制造活人感:让 AI 在下次对话里问出"你上次提到那个被否了三次的设计稿,后来怎样了?"这种话。只有真正认识你的人才会这么问。
第二个 feature 是深度伴侣,5 次有效的 MBTI 对话之后解锁。跟 MBTI 不一样,伴侣是有记忆的:你的人格画像和最近的对话摘要会注入每次对话的上下文,它知道你是谁,记得你说过什么,能自然地引用你的历史。伴侣的提示词里有一条规则,直接呼应伴侣构想里的"判断 Agent":注意到矛盾不代表指出矛盾,只在用户主动探索时才温和地提及。一个只会说好话的 AI 不是用心,是讨好。
而且这是双向的:伴侣的对话也会反哺人格画像。MBTI 采集信号,伴侣兑现价值,两者相互强化,飞轮就是这么转起来的。
设计是聊出来的
整个 feature 从构想到代码到仿真验证,全程在 Claude Code 里完成。最值得记的部分发生在写代码之前:它和我一起做了设计。我给它的第一条指令是去读我的伴侣构想,再探索盘盘猫的 MBTI 代码库,然后告诉我怎么把构想变成现实。它花了一分钟探索完代码库,回复的第一段话就让我觉得它读懂了:
"你的构想文档把 MBTI 定义为更深层伴侣 AI 的原型——不是终点。关键洞察是跨会话记忆需要捕捉的是人格模式和行为倾向,而不仅仅是事实。当前系统已经存储了完整的加密对话记录——原始数据已经在那里了,只是没有被向前传递。"
然后它问了第一个关键问题:记忆该存原始对话,还是存压缩摘要。这个问题不像表面上那么简单。原始对话保留了所有细节,但算算账就知道行不通:每次会话大约 3,000-5,000 token,5 次就是 15,000-25,000 token 的额外上下文,每次伴侣对话都要注入,成本爆炸,噪声也太多。纯摘要又丢失了质感。我在那篇文章里写得很明确,洞察藏在用户怎么说:犹豫、措辞、反复出现的情绪模式、关键原话。干巴巴的摘要会把这些全丢掉。
Claude Code 提了折中方案:结构化摘要加原话保留。每次会话压缩成约 350 token 的结构化 JSON,包含人格信号、情绪基调、关键语录原文;再维护一份约 400 token 的中心化人格画像,每次会话后合并更新。我在此基础上做了进一步收敛:只总结 10 轮以上的合格会话,注入最近 5-10 条摘要,画像持续演进。最终的两层数据模型就这么定下来了。
产品层面的决策也是对话式推进的。Claude Code 问了几个问题,每个都列好选项让我选:解锁后用户看到什么、伴侣放在 /mbti 下还是独立路由、记忆要不要对用户可见。我一个个拍了板:伴侣走独立的 /companion 路由,按独立产品原型来做,不挂在 MBTI 下面;定价一条消息 1 金鱼干,深度伴侣应该是值得付费的体验;解锁时弹庆祝弹窗;记忆面板只读但可清除,信任感比控制感重要。
整个设计对话大概 30 分钟,Claude Code 把决策整合成了一份完整的 spec 和 6 阶段实现计划。然后我让它在隔离的 git worktree 里开始实现:数据库迁移、后端 API、记忆管道、前端流程、解锁流程,每一层都是它写的。
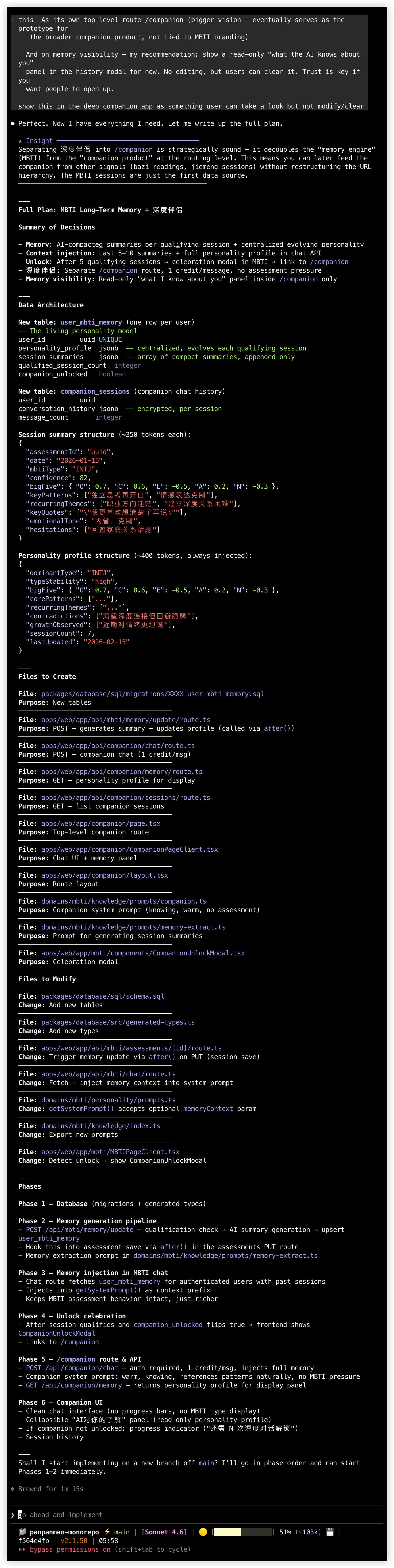 Claude Code 设计 MBTI 长期记忆的实现计划
Claude Code 设计 MBTI 长期记忆的实现计划
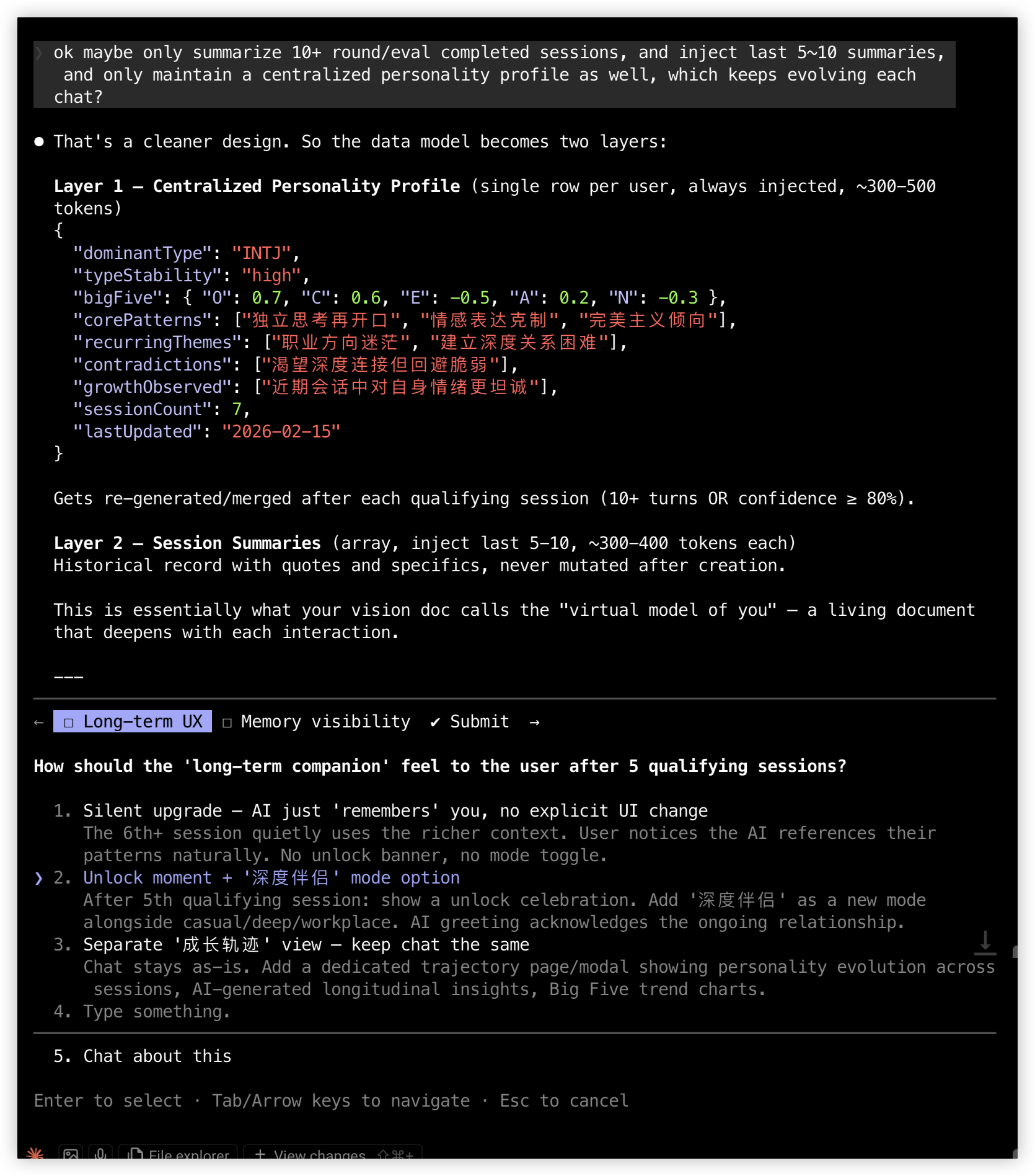 产品层面的决策:解锁体验、人格画像数据模型、深度伴侣路由
产品层面的决策:解锁体验、人格画像数据模型、深度伴侣路由
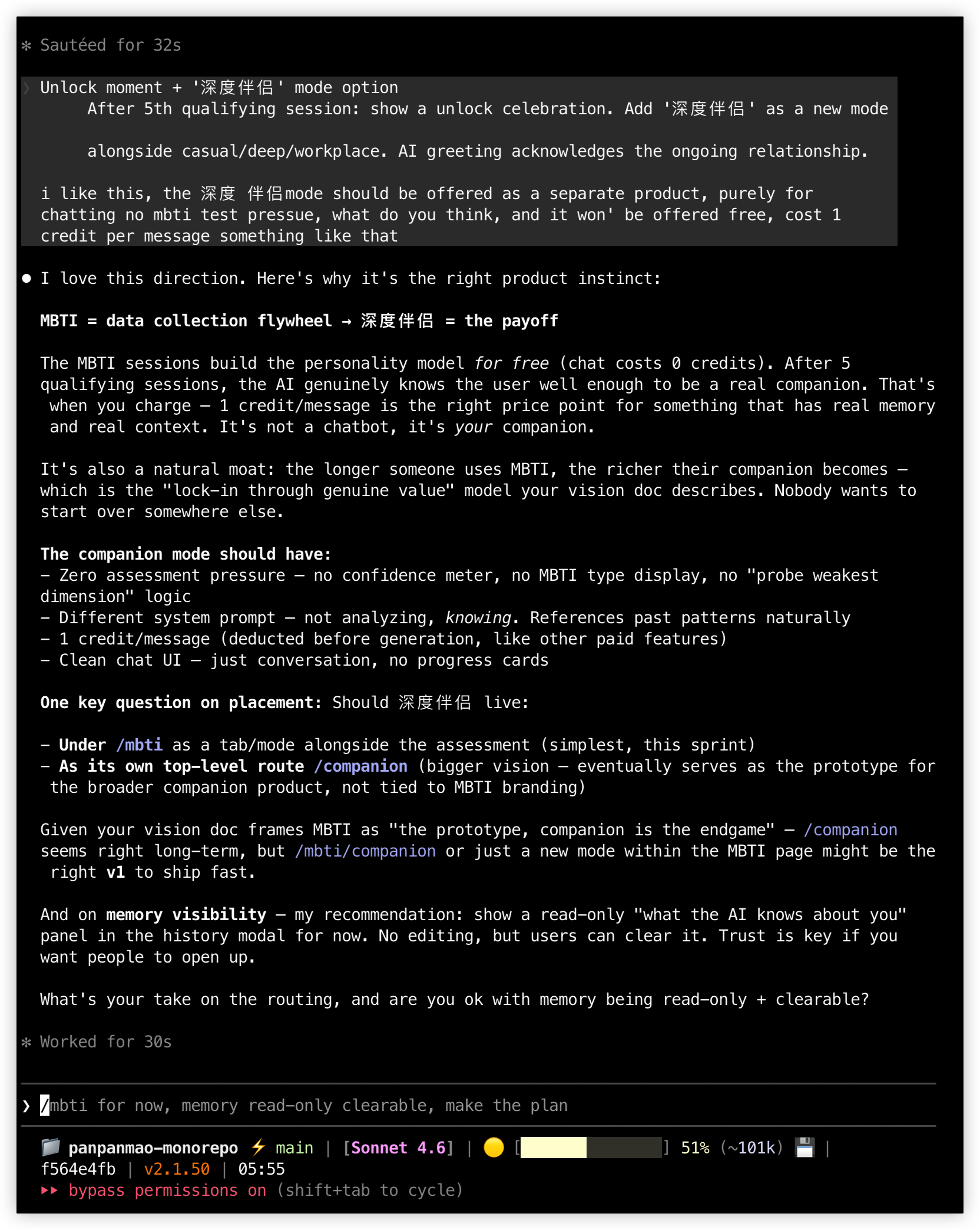 伴侣模式的设计:记忆可见性、定价和路由决策
伴侣模式的设计:记忆可见性、定价和路由决策
仿真调试,跑一次炸一次
写代码只是前半程,后半程是仿真调试,这部分才见真章。我让 Claude Code 搭了一个端到端的算法仿真:一个 AI 模型扮演虚拟用户,另一个扮演盘盘猫的 MBTI 和伴侣 AI,第三个当评审打分。三个模型互相喂数据,模拟完整的 5 次会话流程。
第一次跑就炸了。评审模型的 maxTokens 设了 600,太小,JSON 输出到一半截断,整个评分管道崩掉,改到 1200 重跑。第二次跑,对话生成器吐出来的格式和验证器对不上,对话生成了 66 行,JSON 在中间断了,maxTokens 从 3000 拉到 5000,同时改了提示词里的输出格式约束。
第三次跑,Sessions 1 和 2 的质量评分都到了 9/10,但画像合并到 Session 2 时又截断了,画像的 JSON schema 比预期大,maxTokens 从 800 改到 1400。第四次跑,终于看到有意义的质量反馈,评审说"hesitations 捕捉准确,但可以补充用户对某个行为变化的回避"。每轮大概 10 分钟,四轮下来,Claude Code 的上下文窗口已经用到 79%。真实的开发过程就是这种循环:跑一次,看哪里炸了,改一行,再跑一次。
 仿真测试代码:三个 AI 模型互相喂数据
仿真测试代码:三个 AI 模型互相喂数据
 仿真结果:MBTI 会话评分、人格画像提取、质量反馈
仿真结果:MBTI 会话评分、人格画像提取、质量反馈
算法仿真验证的是记忆质量,还有一层要验证:整条管道在真实环境里跑不跑得通。记忆提取是异步的,跑在请求结束之后的后台任务里,如果静默失败了,用户根本不知道。Claude Code 又搭了一套集成仿真:创建真实的测试用户,打真实的 API,轮询数据库等异步记忆提取完成,然后直接问伴侣 AI:"你还记得我在哪里工作吗?"如果能回答出"上海"和"UI 设计师",从对话到摘要到画像到注入的整条管道就是通的。
集成仿真跑出 7 个阻塞性 Bug,全是算法仿真发现不了的工程层问题:数据库字段名不匹配但 Supabase 静默返回 200、异步任务没转发鉴权头导致记忆提取永远跑不通、token 预算不够导致 JSON 截断。Claude Code 在同一个会话里逐个定位并修复。
整个 feature 从零到可测试,不到一天。我全程没有写一行实现代码,也没有手动跑过一次测试。我做的是设计、讨论、拍板:记忆用摘要还是原文、画像多大、伴侣放什么路由、解锁门槛几次,这些是需要人来判断的问题。数据库迁移、API 路由、记忆管道、仿真脚手架、三个 AI 模型的编排、跑四轮调参、搭集成测试,这些重活脏活全是 Claude Code 干的。
设计对话和代码实现发生在同一个上下文里。我说"记忆应该只增不减",它就改提示词;我说"跑一个集成仿真验证管道",它就搭测试用户、打 API、轮询数据库。决策和执行之间没有断层,没有翻译损耗。
"你上次说过'我想要的不是建议'"
算法仿真的完整设定是 3 次 MBTI 会话加 2 次伴侣会话,验证记忆的提取、积累和跨会话引用。虚拟用户叫"林晓月",28 岁,UI 设计师。第一次 MBTI 会话里,她提到一件事:
"改了好几版设计稿,最后选了第一版,会觉得有点无力。"
AI 把这句话提取为一个记忆锚点,归在人格信号下面,记录的是她应对挫败的方式,跟事实类摘要分开存。两次会话之后,她解锁了深度伴侣。第一次伴侣对话里,她说最近在纠结一个大厂的机会,来回聊了几轮,AI 说了一句:
"改了几版最后用第一版那种无力感,是不是又来了?"
林晓月的回复是"对,就是那种感觉"。这是一次跨会话的记忆引用:AI 没有回看原始对话记录,手里只有那份 400 token 的人格画像,画像里的锚点在正确的时刻被激活了。
第二次伴侣会话,她说最近失眠,躺下脑子就转,聊着聊着说到男朋友小明:"他说的都对,但我听完心里堵堵的。他让我别想太多,早点睡。"AI 没有顺着安慰她,把她在第二次 MBTI 会话里说过的话引了回来:
"你上次说过'我想要的不是建议'。小明是不是常这样,道理都对,但不是你想听的?"
她回答:"对。他不是不关心,但我说完一件事他就想帮我解决。"AI 接着说:"你需要的是有人陪你待在那个情绪里,不是马上被拉出来。"她的下一句话是这轮对话的转折:"但我也没跟他说过我真正想要什么,觉得说了好像在怪他。"
她从抱怨"他不听我说",开始看到自己的模式:一直压着需求不说,因为怕表达需求变成指责。AI 把这一点指出来之后,她说:
"他确实不是那种会觉得我矫情的人。是我自己先把门关上了。"
整段对话里,AI 没给建议,没做分析,只是用她自己说过的话,把她引回一个她一直在回避的问题:不是对方不理解你,是你从没给对方机会理解你。这种理解给的未必是你想听的,但能帮你看见自己看不见的。我在伴侣构想里想让 AI 学会的,就是这个。仿真跑完,10 个评分维度平均 8.1/10,核心飞轮转起来了。
新记忆把旧记忆吃了
8.1 分意味着系统可用,但不完美。仿真暴露的问题是:AI 把新的对话摘要合并进人格画像时,有时候直接拿新内容替换旧内容,积累变成了覆盖。具体来说,MBTI 阶段积累的偏好"喜欢创作(写作/绘画)",在伴侣会话之后被新条目覆盖了;记忆锚点"被别人的情绪吸收会觉得累"消失了;大厂跳槽这条悬而未决的线索,反复被替换成更表面的问题。
这验证了伴侣构想的判断:记忆编排难在"编排"两个字。信号提取是容易的部分,难的是让先存下来的信号活过后面一轮轮合并。
修复是提示词级别的。Claude Code 在画像合并的提示词里加了一组"只增不减"规则,没改一行架构代码,纯粹是 prompt 调优:
memorableMoments:只增不减。每条都是一次真实对话的记忆碎片,建立"活人感"的核心资产。除非用户明确说某件事已经解决并且不再有意义,否则永远不要删除。
preferences:只增不减。绝对不要删除或覆盖已有条目——用户的喜好是跨会话累积的。
unresolvedThreads:谨慎移除。"话题没被提到"或"对话转移"不算解决。优先保留涉及深层内心冲突的线索,而非表面信息缺口。
这类系统的行为,大半定义在提示词层,而且提示词也不是一次写成的:初版画像 schema 根本没有 memorableDetails 和 unresolvedThreads 这些字段,是跑仿真的过程中发现缺了什么,才补上的。设计和测试是交织在一起的。
MBTI 采集信号,深度伴侣兑现价值,这条链路验证下来是通的:理解从对话里来,靠记忆累积,再通过引用传回给用户,让人感受到被理解。
当然还不完美:画像的积累规则需要更多实战数据打磨,伴侣的语气和节奏要调得更自然,上下文窗口的预算分配需要更精细的 context engineering。v0 的盘盘猫是个没有记忆的对话工具,v0.1 开始有点像一个理解你的伴侣。下一步是把它交给真实用户,看画像在仿真之外长不长得出来。