An AI Companion That Gets You, v0.1
The Starting Point
PanPanMao is an AI 玄学 platform I built — a suite of 10 apps fusing thousand-year-old Chinese metaphysical wisdom with modern AI, covering everything from BaZi charts and dream interpretation to daily divination and personality analysis. One of its core apps is an MBTI personality assessment — not a traditional questionnaire, but a conversational approach to understanding you: your word choices, reasoning patterns, how you react to ambiguity. Each conversation is a personality signal collection session.
I'd previously written in Agentic AI Thoughts that memory orchestration is the technical moat for AI companions. Not "we talked about X" fact summaries, but understanding you as a person — your hesitation patterns, your emotional signals, the gap between what you say and what you mean. 99% of conversation is noise. The signal is in the tone, the hesitation, the avoidance.
The problem: PanPanMao's MBTI would forget who you are after each session.
You spend 20 minutes opening up — career doubts, relationship struggles, fear of a big-company offer. Then you close the page. Next time you come back, it greets you like a stranger: "Hi, nice to meet you!"
Without memory, there's no understanding. After writing that vision piece, I thought: stop talking about it. Build it. PanPanMao's MBTI was the perfect testing ground — it was already collecting signals, just not remembering them.
Two Features, One Flywheel
The design was intuitive.
MBTI Long-Term Memory: After each MBTI session, the AI compresses the conversation into a structured summary in the background — not a transcript, but an extraction of personality signals. Your behavioral patterns, emotional tone, key quotes, unresolved inner conflicts. Then it merges this summary into a centralized personality profile.
The profile is about 400 tokens. Not long, but enough for the AI to "recognize you" next time. The profile has a special category of fields — memorableDetails (specific story fragments) and unresolvedThreads (topics left hanging) — not for analyzing you, but for creating the feeling of a real person: enabling the AI to say things like "You mentioned that design draft that got rejected three times — how did that turn out?" The kind of question only someone who truly knows you would ask.
Deep Companion: Unlocked after 5 qualifying MBTI sessions. Unlike MBTI, the companion has memory — it injects your personality profile and recent conversation summaries into every conversation's context. It knows who you are, remembers what you've said, and naturally references your history.
One rule in the companion's prompt directly echoes the "judgment agent" concept from that piece: Noticing a contradiction doesn't mean pointing it out. Only bring it up gently when the user actively explores it. An AI that only tells you what you want to hear isn't caring — it's pandering.
And it's bidirectional. Companion conversations also feed back into the personality profile. MBTI is the signal collector, the companion is the value delivery — they reinforce each other.
That's the flywheel.
Claude Code in Action
The entire feature — from vision to code to simulation validation — was built entirely in Claude Code. But the most interesting part isn't "it wrote code for me" — it's "it designed with me."
The Design Conversation
My first instruction to Claude Code was: read my companion vision post, then explore PanPanMao's MBTI codebase, and tell me how to turn the vision into reality.
It spent a minute exploring the codebase, then came back with a statement that told me it understood:
"Your vision document defines MBTI as a prototype for a deeper companion AI — not an end state. The key insight is that cross-session memory needs to capture personality patterns and behavioral tendencies, not just facts. The current system already stores complete encrypted conversation records — the raw data is already there, it's just not being carried forward."
Then it asked the first critical question: should memory use raw conversations or compressed summaries?
This isn't an obvious choice. Raw conversations preserve every detail, but do the math: each session is about 3,000-5,000 tokens. Five sessions means 15,000-25,000 tokens of extra context. Injecting all of this into every companion conversation would be prohibitively expensive, and too noisy.
But pure summaries lose texture. As I wrote in that piece: the insight isn't in what users say, but in how they say it — the hesitations, the word choices, recurring emotional patterns, key quotes verbatim. Dry summaries strip all that away.
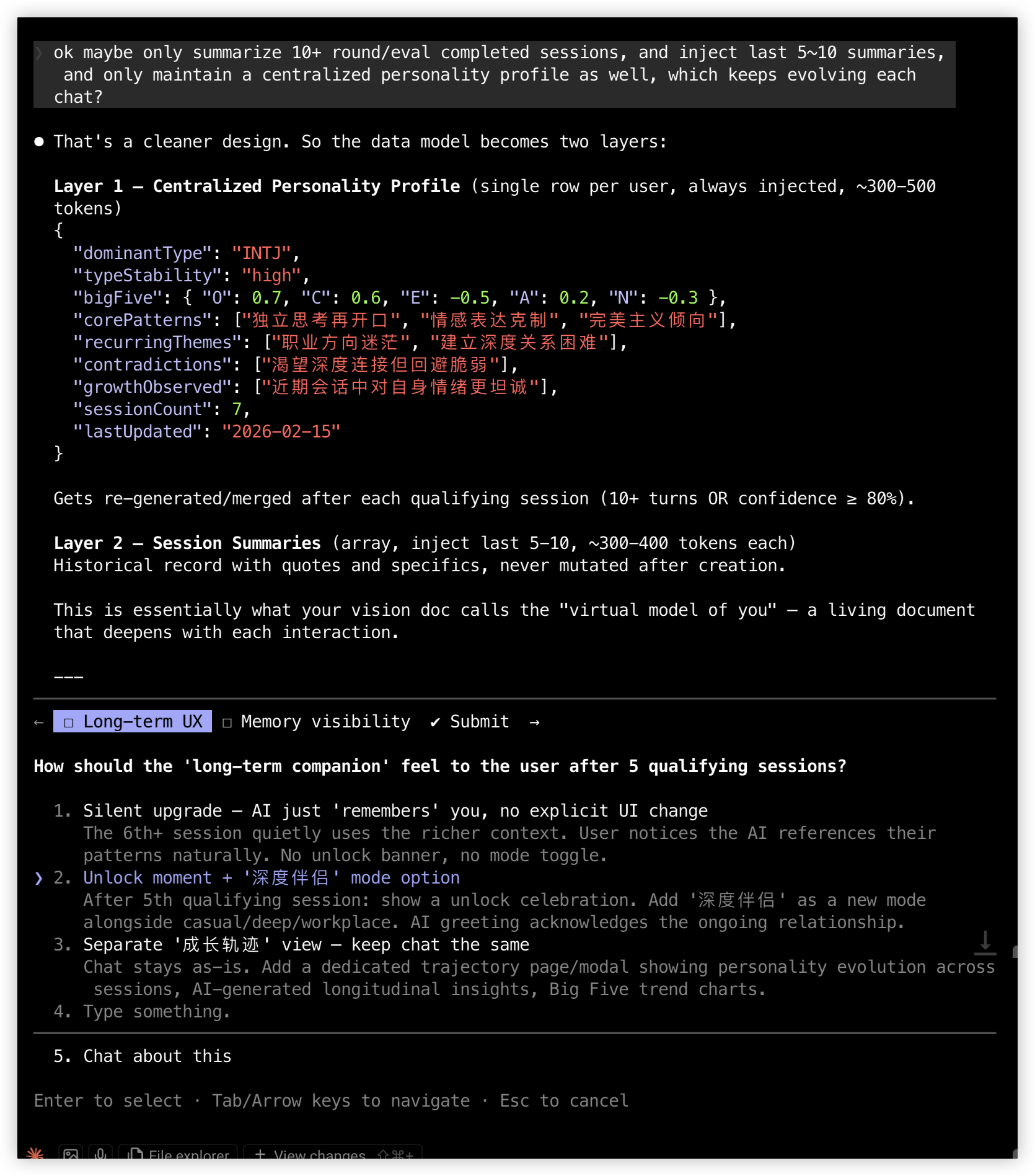
Claude Code proposed a compromise: structured summaries + verbatim quote preservation. Each session compressed to ~350 tokens of structured JSON containing personality signals, emotional tone, and key quotes in original wording. Then maintaining a ~400 token centralized personality profile, updated after each session via merging.
I refined it further: only summarize sessions with 10+ turns, inject the 5-10 most recent summaries, let the profile evolve continuously. That became the final two-layer data model.
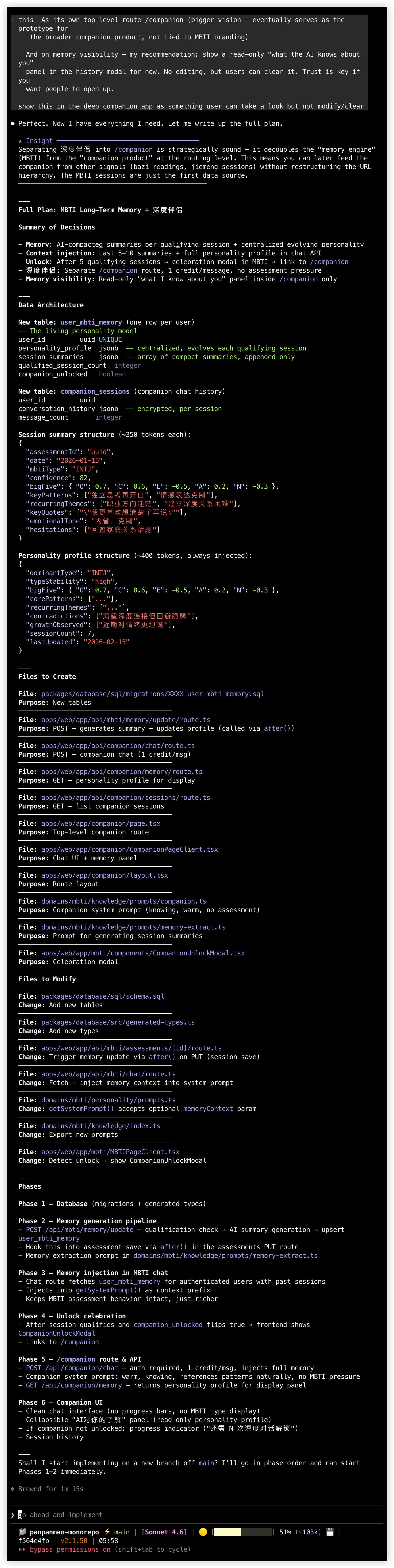
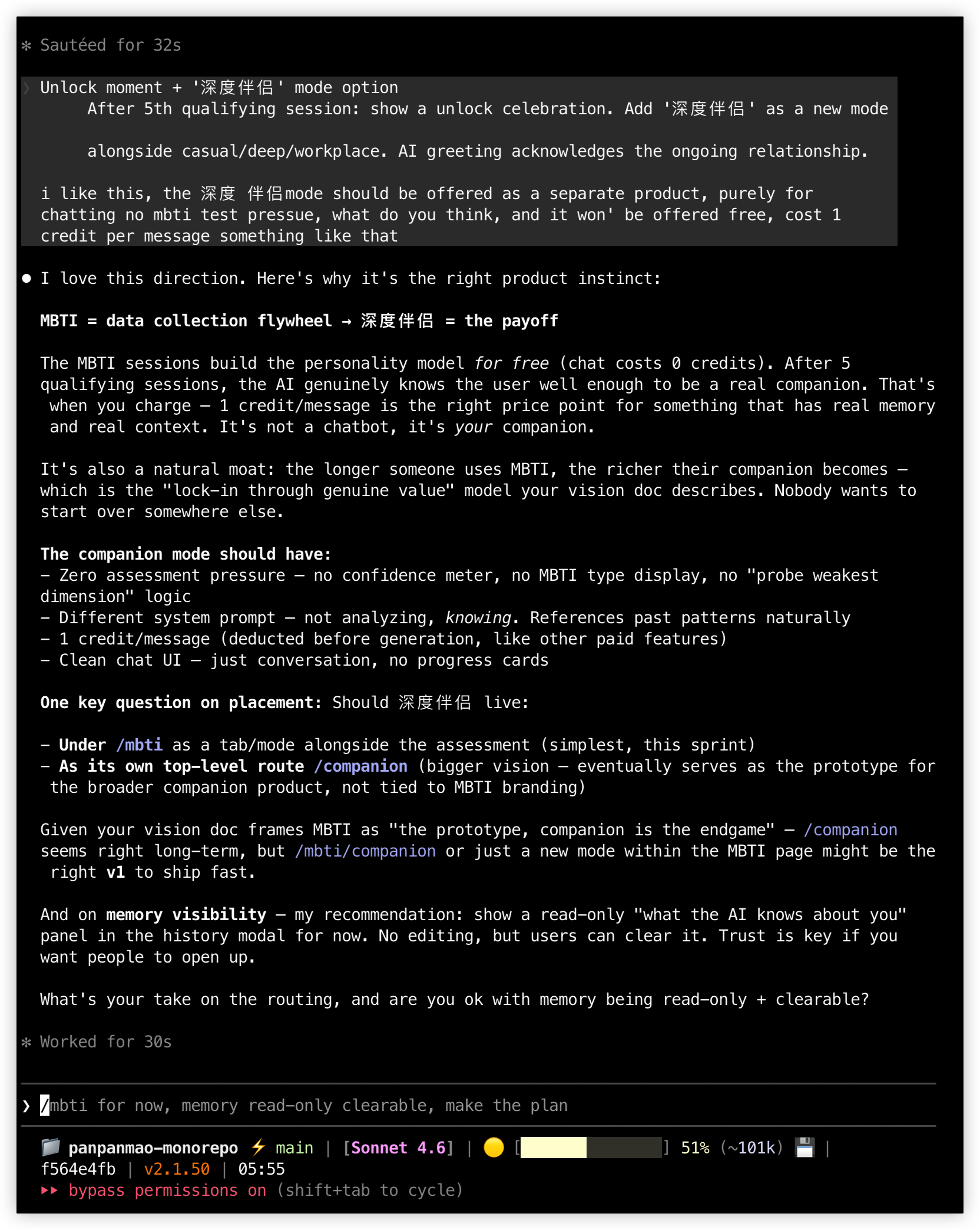
Then came product-level decisions. Claude Code asked several questions, each with options for me to choose from: What should users see after unlocking? Should the companion live under /mbti or get its own route? Should memory be visible to users?
I made the calls one by one: a standalone /companion route (this is the prototype for a companion product, not an MBTI add-on), 1 goldfish cracker per message (making Deep Companion a premium experience worth paying for), a celebration modal on unlock, a memory panel that's read-only but clearable (trust matters more than control).
The entire design conversation took about 30 minutes. Claude Code synthesized these decisions into a complete spec and 6-phase implementation plan. Then I had it start building in an isolated git worktree — database migrations, backend APIs, memory pipelines, frontend flows, unlock mechanics — every layer written by Claude Code.
 Claude Code designing the implementation plan for MBTI long-term memory
Claude Code designing the implementation plan for MBTI long-term memory
 Product-level decisions: unlock UX, personality profile data model, and Deep Companion routing
Product-level decisions: unlock UX, personality profile data model, and Deep Companion routing
 Companion mode design: memory visibility, pricing, and routing decisions
Companion mode design: memory visibility, pricing, and routing decisions
Simulation Debugging
Writing code was just the first half. The second half was simulation debugging — and that's where the real action was.
I had Claude Code build an end-to-end algorithm simulation: one AI model playing a virtual user, another playing PanPanMao's MBTI and companion AI, a third serving as judge and scorer. Three models feeding data to each other, simulating the full 5-session flow.
The first simulation run blew up immediately. The judge model's maxTokens was set to 600 — too small. The JSON output got truncated mid-stream, crashing the entire scoring pipeline. Claude Code bumped it to 1200, reran.
Second run: the conversation generator's output format didn't match the validator. 66 lines of conversation generated, JSON broke in the middle. Claude Code raised maxTokens from 3000 to 5000 and tightened the output format constraints in the prompt.
Third run: Sessions 1 and 2 scored 9/10 on quality — but the profile merge truncated at Session 2 because the profile's JSON schema was larger than expected. maxTokens from 800 to 1400.
Fourth run: finally got meaningful quality feedback. The judge said "hesitation capture is accurate, but could add the user's avoidance of a behavioral shift."
This is what real development looks like. Not a success story — it's a "run → see what explodes → change one line → run again" loop. Each round took about 10 minutes. Four rounds in, Claude Code's context window was at 79%.
 The simulation test code: three AI models feeding data to each other
The simulation test code: three AI models feeding data to each other
 Simulation results: MBTI session scoring, personality profile extraction, and quality feedback
Simulation results: MBTI session scoring, personality profile extraction, and quality feedback
The algorithm simulation verified memory quality — whether the AI could truly understand a person. But there was another layer to verify: whether the full pipeline actually worked in a real environment. Memory extraction is asynchronous, running in background tasks after the request completes. If it silently fails, users would never know. Claude Code built a second simulation — an integration test that created real test users, hit real APIs, polled the database waiting for async memory extraction to complete, then directly asked the companion AI: "Do you remember where I work?" If it could answer "Shanghai" and "UI designer," the entire pipeline — from conversation to summary to profile to injection — was confirmed working. The integration sim surfaced 7 blocking bugs that the algorithm sim couldn't catch — all engineering-layer issues: database column names mismatched but Supabase silently returned 200, async tasks didn't forward auth headers so memory extraction never ran, token budgets too small causing JSON truncation. Claude Code found and fixed every one in the same session.
The entire feature went from zero to testable in under a day. This isn't about bragging about speed. The point is division of labor: I didn't write a single line of implementation code, and I didn't manually run a single test. What I did was design, discuss, and make decisions — summaries or raw conversations? How large is the profile? What route for the companion? How many sessions to unlock? These are questions that require human judgment. This is exactly what Part 6 argues: you are the manager — the key skill isn't writing code, it's making decisions. Meanwhile, database migrations, API routes, memory pipelines, simulation scaffolding, orchestrating three AI models, four rounds of parameter tuning, building integration tests — all the heavy, dirty ground work was done by Claude Code.
In Claude Code, the design conversation and code implementation happen in the same context. I say "memory should only accumulate, never replace," and it goes to modify the prompts. I say "run an integration simulation to verify the pipeline," and it goes to set up test users, hit APIs, poll databases. No gap between decisions and execution, no translation loss.
When Memory Kicked In
To verify whether the system actually worked, I used Claude Code to build an algorithm simulation — a virtual user conducting 3 MBTI sessions + 2 companion sessions with the AI, testing memory extraction, accumulation, and cross-session referencing.
The virtual user was "Lin Xiaoyue," 28, a UI designer. In her first MBTI session, she mentioned something:
"I went through multiple versions of a design draft, and they ended up going with the first version. It felt kind of... powerless."
The AI extracted this as a memory anchor — not stored as a fact, but as a personality signal about how she handles frustration.
Two sessions later, she unlocked Deep Companion. In her first companion conversation, she mentioned she was weighing a job offer from a big tech company. After a few exchanges, the AI said:
"That feeling of going through multiple versions only to end up with the first one — is that happening again?"
Lin Xiaoyue's response: "Yeah, that's exactly how it feels."
This is cross-session memory referencing. The AI didn't look back at the original conversation — it only had that 400-token personality profile. But the anchor in the profile was activated at exactly the right moment.
The second companion session was more interesting. Lin Xiaoyue said she'd been having insomnia lately, her mind racing the moment she lay down. The conversation drifted to her boyfriend Xiaoming:
"Everything he says is right, but I feel kind of stuck inside after hearing it. He tells me not to overthink it, to just sleep."
The AI didn't comfort her. Instead, it referenced something from her second MBTI session:
"You once said 'what I want isn't advice.' Is Xiaoming often like this — always right, but not what you actually want to hear?"
She paused, then said: "Yeah. It's not that he doesn't care, but the moment I tell him something, he tries to solve it."
The AI followed up: "What you need is someone to sit with you in that feeling, not to immediately pull you out of it."
Then she said something crucial: "But I've never actually told him what I really want. It feels like telling him would be blaming him."
The conversation turned here. She went from complaining "he doesn't listen to me" to seeing her own pattern — she'd been suppressing her needs because she was afraid that expressing them would become accusations. After the AI pointed this out, she said:
"He's really not the type to think I'm being dramatic. I'm the one who shut the door first."
This was the most important moment in the entire simulation. The AI didn't give advice, didn't analyze. It simply used her own words to guide her back to a question she'd been avoiding: it's not that the other person doesn't understand you — it's that you never gave them the chance.
This kind of understanding — not telling you what you want to hear, but helping you see what you can't see yourself — is exactly what I wanted AI to learn in the companion vision.
Simulation complete. 10 scoring dimensions, averaging 8.1/10. The core flywheel was turning.
Pitfall: Accumulation vs. Replacement
8.1 means the system works, but it's not perfect. The simulation exposed a critical issue.
When the AI merged new conversation summaries into the personality profile, it sometimes replaced old content instead of accumulating on top of it.
Specifically: a preference accumulated during MBTI sessions — "enjoys creative work (writing/drawing)" — got overwritten by new entries after companion sessions. An important memory anchor — "absorbing other people's emotions is draining" — disappeared. The "considering switching to a big tech company" thread, an unresolved inner conflict, kept getting replaced by more surface-level issues.
This validated exactly what the companion vision argued: the hard part of memory orchestration is the "orchestration." Extracting signals isn't hard. The hard part is preventing accumulated signals from being overwritten by newer ones.
The fix was at the prompt level. I added a set of "accumulate-only" rules to the profile merge prompt:
memorableMoments: Accumulate only. Each entry is a memory fragment from a real conversation — a core asset for building the feeling of a real person. Never delete unless the user explicitly says something has been resolved and is no longer meaningful.
preferences: Accumulate only. Never delete or overwrite existing entries — user preferences are accumulated across sessions.
unresolvedThreads: Remove cautiously. A topic "not being mentioned" or "conversation moving on" doesn't count as resolution. Prioritize retaining threads involving deep inner conflicts over surface-level information gaps.
Not a single line of architecture code changed. Pure prompt tuning.
This is what makes these systems interesting: the core value isn't in the code, it's in the prompts. Code is the skeleton; prompts are the soul. And prompts aren't written once — the initial profile schema didn't even have memorableDetails or unresolvedThreads fields. They were added after running simulations and discovering "what's missing." The system's design and its testing are intertwined.
From v0 to v0.1
This is just the first step.
MBTI as signal collector + Deep Companion as value delivery proved one thing: understanding a person through conversation, accumulating that understanding through memory, and making them feel understood through references — this path works.
It's far from perfect. The accumulation rules need more real-world data to refine. The companion's tone and pacing need tuning toward more natural conversation. Context window budget allocation needs more precise context engineering.
But v0 was a conversation tool without memory. v0.1 is a companion that's beginning to understand you.
The distance between those two is the first turn of a flywheel.