I Rewrote My AI Coding Harness Four Times in Two Months
The session that broke vanilla
Mid-March. I was refactoring a Shichuan feature that touched about seven files. Vanilla Claude Code — no scaffolding, no skills, just the main session doing everything itself. By the fourth file, the main thread was carrying the full text of every file I'd touched, the failing test output from each iteration, and my commentary on each. Context hit ~80%. I had to interrupt, run /compact, and watch the model lose about thirty minutes of nuanced state.
That's when I accepted that vanilla Claude Code is a tier-1/tier-2 tool. Single file, single function, single question — perfect. Anything bigger, and the main thread becomes a context landfill.
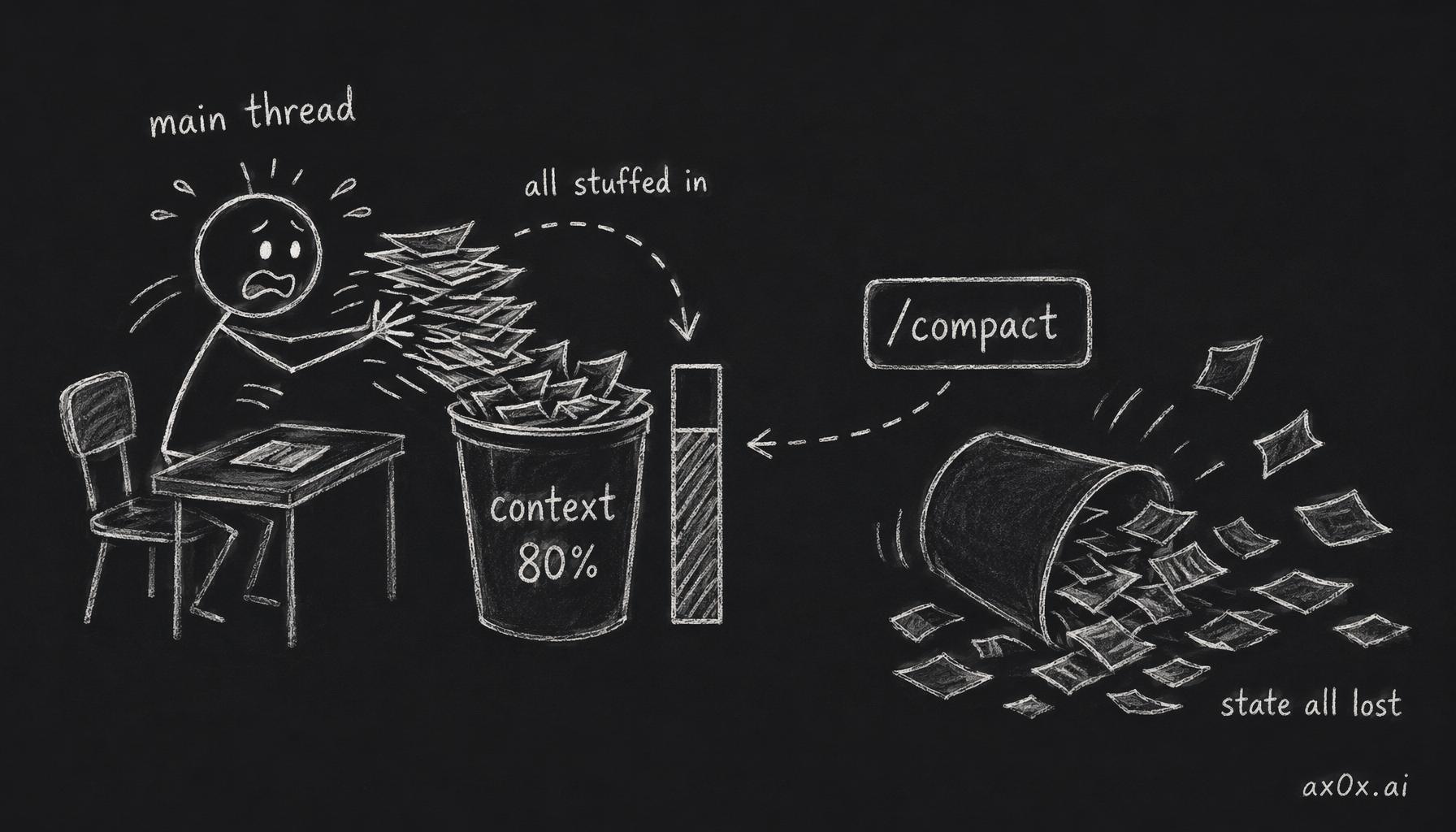 How a single main thread hoards every file, test output and note until context hits 80% and /compact wipes the accumulated state
How a single main thread hoards every file, test output and note until context hits 80% and /compact wipes the accumulated state
Since then I've rewritten my AI coding harness four times. Each rewrite came from a specific session that broke, not from "this looks cool on Twitter." Below is the trajectory, the breaking points, and what I eventually kept.
Harness 1: vanilla
What it is: Just Claude Code. Main session reads files, edits files, runs commands. No subagents, no skills.
Where it shines: Tier-1 and tier-2 work — hotfixes, typos, one-function rewrites, Q&A. Anything where the signal-to-noise ratio in the main thread stays high.
Where it breaks: The moment you exceed two or three files, or need to run tests iteratively, or want to do anything concurrent. The main thread hoards every file read, every test output, every thought. On a 10-file feature with TDD, you'll hit 80% context in an hour.
This isn't a Claude Code bug. It's just that "one thread does everything" doesn't scale to team-shaped work. And at some point, solo dev work starts to look team-shaped.
Harness 2: GSD
What it is: get-shit-done (GSD) by TÂCHES — a multi-agent framework that structures work into phases. Each phase runs a chain of skills: gsd-discuss-phase → gsd-plan-phase (with an internal plan-checker agent) → gsd-execute-phase → gsd-verify-work → gsd-audit-fix. Planning and execution are both done by subagents. State lives on disk in .planning/.
Where it shines: Genuinely large work. I ran a full Shichuan redesign through GSD — schema migrations, new subsystems, cross-phase dependencies. The multi-agent planning caught real bugs before execution. Parallel execute-phase waves ran while I did other things. GSD's execute-phase engine runs at ~15% main-thread budget because subagents self-load plan files from disk and return summaries, not raw output. For truly tier-4 work, that discipline is worth the setup cost.
Where it breaks: For solo dev and tier-3 work, GSD is over-engineered. Each phase generates six meta-artifacts — CONTEXT.md, PATTERNS.md, RESEARCH.md, REVIEW.md, VALIDATION.md, VERIFICATION.md — on top of the actual PLAN.md. I pulled .planning/ stats from two of my repos:
| Repo | .planning/ LOC |
|---|---|
| Shichuan | ~21,000 |
| ÉLAN | ~24,000 |
Some of those documents caught real bugs. Most of them were the same "what are we building? what's the risk? what could break?" checklist filled in six slightly different framings. For solo dev, reading through all six takes longer than the code change itself.
I used GSD for about three weeks and started resenting it every time I wanted to ship a three-file feature. But when I looked at throwing it out, I realized the multi-agent planning had actually caught things I would have shipped broken. So I couldn't just drop it.
Harness 3: superpowers
What it is: superpowers by Jesse Vincent — a skill library with about 14 general-purpose skills. brainstorming, writing-plans, subagent-driven-development, requesting-code-review, verification-before-completion, test-driven-development, using-git-worktrees, dispatching-parallel-agents, etc. No phase structure, no .planning/ — just skills you invoke.
What I liked:
- Skills are composable. You pick the ones that match the current work, not a fixed phase chain.
subagent-driven-developmentdoes per-task fresh subagents with two-stage review (spec compliance first, then code quality). Catches spec drift before merge.- Session-start hook auto-injects the meta-skill
using-superpowersinto every session, which tells the model "if there's even a 1% chance a skill applies, you MUST invoke it." Aggressive but it works — I stopped forgetting to invoke skills. - Skills explicitly say "user instructions override skill instructions." Priority ordering respected.
Where it breaks:
First, the auto-injection costs about 5,000 tokens per session. That's a fixed tax on every conversation, whether or not the work would benefit from any skill.
Second, and more importantly, subagent-driven-development is explicitly serial. From the skill itself: "Never dispatch multiple implementation subagents in parallel (conflicts)." That's correct for shared-file implementations — two agents editing the same file is a merge nightmare. But it means superpowers can't do what GSD's execute-phase does: dispatch parallel waves of implementation across disjoint files. For long autonomous runs, superpowers runs sequentially per task, with three subagents per task (implementer + spec reviewer + quality reviewer). The main thread coordinates the sequence, holding all the task text in memory. On a 20-task plan, the controller's context swells faster than I expected.
So now I had two partially-right harnesses. GSD did parallel waves well but drowned small work in planning ceremony. Superpowers was light for small work but couldn't match GSD's lean orchestrator for long runs.
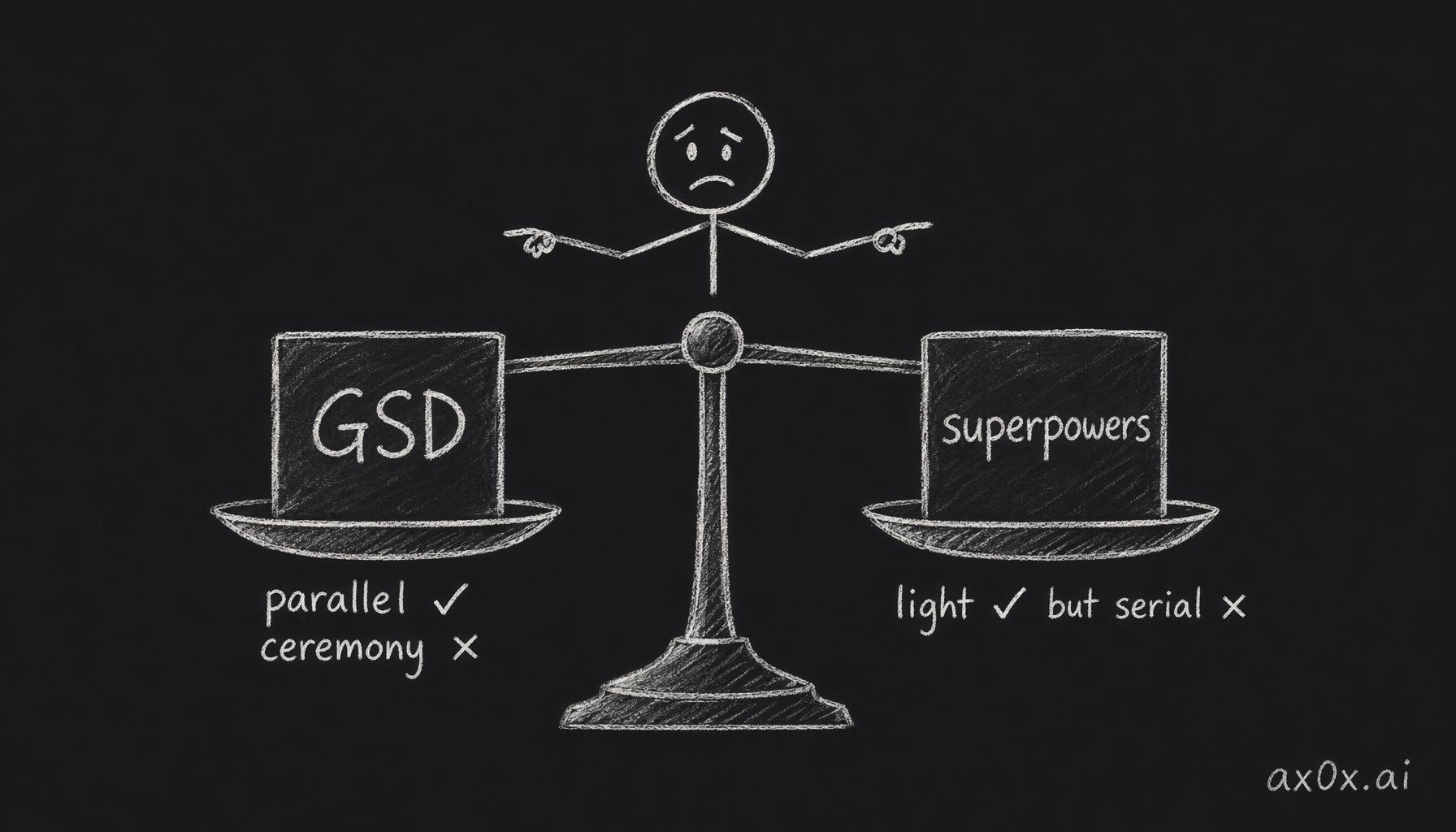 GSD nails parallel waves but drowns in planning ceremony while superpowers is light but serial — each harness is only half-right
GSD nails parallel waves but drowns in planning ceremony while superpowers is light but serial — each harness is only half-right
Harness 4: big-task
What it is: An orchestrator skill I wrote that hides the other three behind a single memorable name. It auto-triggers when I describe work that touches 3+ files or introduces new functionality. It decides which underlying harness to use based on the work shape, not a default.
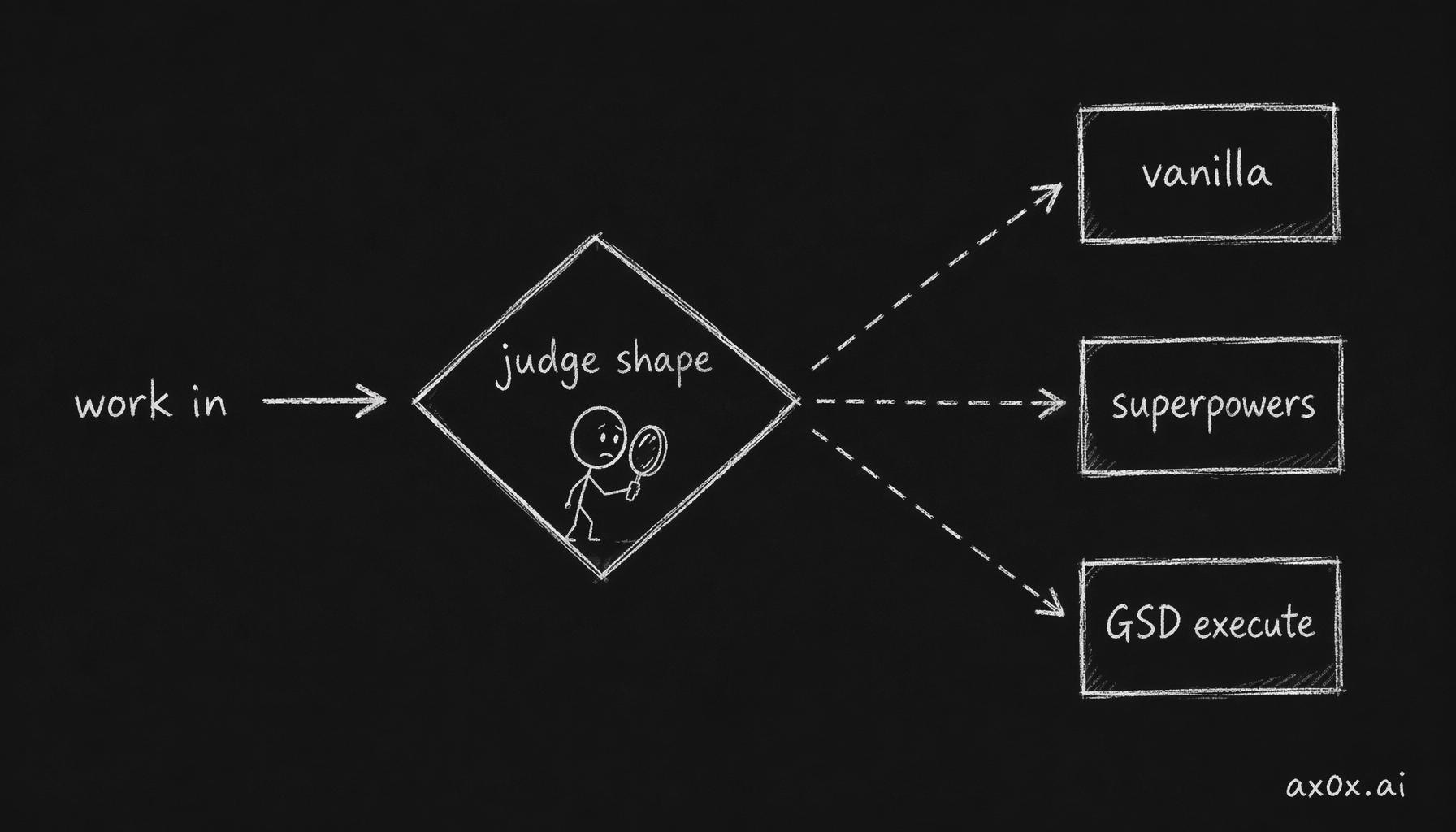 big-task keeps no default engine and routes each task by its work shape to vanilla, superpowers, or GSD's execute engine
big-task keeps no default engine and routes each task by its work shape to vanilla, superpowers, or GSD's execute engine
The mental model is routing, not replacement. big-task doesn't re-implement TDD, it delegates to the tdd-workflow skill when appropriate. It doesn't re-implement subagent dispatch, it delegates to superpowers:subagent-driven-development or gsd-execute-phase. Its only job is picking correctly.
Phase 0.0: auto-detecting the project shape
Before any tier decision, big-task classifies the project into one of four workflow profiles: light, ui, heavy, or unknown. It runs a single bash heuristic (~1 second) that emits signals:
content-N— number of markdown files incontent/posts/,_posts/, etc.components-ui—components/directory + UI library inpackage.json(tailwind / radix / shadcn / mui / chakra)design-ref— presence ofHANDOFF.md,directions/, ordocs/design/schema— presence of Prisma / Drizzle / Knex config, or SQL migrationsauth-payment— Stripe / Better-Auth / NextAuth / Lucia in dependenciesplaywright—@playwright/testin dependenciesbackend-lang— Go, Rust, or Python detected
Rules apply first-match: content ≥ 20 → light (a 270-post blog stays light even if it has a components directory). Schema OR auth-payment AND backend-shaped → heavy. Components-ui OR design-ref → ui.
This is repo shape. But it's not the whole story.
Phase 0.0, step 2.5: task intent (judgment, not keyword matching)
The repo scan answers "what shape is this codebase?" It doesn't answer "what shape is the current request?" A blog repo is light, but "add a Stripe paywall to premium posts" is a heavy task that happens to sit in a light repo. I don't care what the repo signals say for that one — it's a trust-boundary, revenue-path change, and it needs heavy process regardless.
My first pass at this used keyword matching. Scan the task description for "stripe", "auth", "migration", "schema" → force heavy. That was wrong in the dumbest way: I am an LLM reading the task description. Regex-over-natural-language inside an LLM context is an anti-pattern. Someone saying "I was reading about Stripe's API yesterday" is not the same as "integrate Stripe payments", even though both contain "Stripe."
The fix: replace the keyword list with judgment criteria. The skill now asks me to classify what the task does to the system:
- Heavy by nature — persistence changes, trust boundaries, revenue path, atomicity/concurrency, cross-system contracts, new architectural subsystems
- Light by nature — written prose, cosmetic visual tweaks, single stable-schema config tweaks
- UI by nature — applying existing design patterns, N+1 application of a known pattern
Plus framing questions when those don't settle it: blast radius (customer money vs. bad afternoon), reversibility (git revert vs. data migration unwind), design-vs-translation, pattern novelty.
The combining rule applies in order: task is heavy by nature → heavy regardless of repo. Task is light by nature → light regardless of repo. Task introduces a new pattern → max(repo, one-level-up). Otherwise use the repo profile.
The rule that replaced my keyword list is shorter than the keyword list was, and it's also more correct.
Subagent dispatch policy
This is the last piece, added today. Every phase in big-task now carries a Subagent policy line, chosen by work nature, not tier:
| Mode | When | Main-thread consumption |
|---|---|---|
| parallel-worktree | Implementation on disjoint files | <20% — each subagent writes in its own worktree |
| parallel-readonly | Investigation, review, audit, visual verification | <20% — fan out one per target |
| serial-subagent | Implementation on shared files | ~30% — superpowers' subagent-driven-development, fresh per task |
| inline | Single-file change, Tier 2 hotfix, trivial decision | 100% |
The rule I enforce: never inline when tier ≥ 3 AND independent task count ≥ 3. Inline past that scale bloats main-thread context and defeats the whole point of the subagent architecture.
The orchestrator discipline matters as much as the mode choice:
- Subagents load inputs from disk themselves. The controller does not inject full task text into every subagent prompt. That's how superpowers' controller accidentally hoards context across a 20-task plan.
- Subagents return structured summaries ≤200 tokens, not raw output.
- State lives on disk, not in chat history.
- Worktree isolation before parallel-worktree dispatch — removes the shared-state bar that otherwise forbids parallel implementers.
Announce the mode when entering a phase: Phase 2b · parallel-readonly (4 routes). Makes routing auditable. Also catches inline overuse — if I notice myself announcing inline three phases in a row on tier-3 work, something's wrong.
What GSD got right that took me two months to see
Here's the thing I nearly threw out. GSD's planning overhead — the six meta-artifacts per phase — is real. But GSD's execute-phase engine itself is lean. Orchestrator sits at ~15% main-thread budget because subagents self-load plan files from disk and return summaries. For long autonomous runs where you just want the implementation to go without constant supervision, that discipline is unmatched.
I had conflated the planning overhead with the execution overhead. When I wanted to ditch GSD, what I actually wanted to ditch was gsd-discuss-phase and gsd-plan-phase's ceremony, not gsd-execute-phase's mechanics. Took me a while to separate those two.
The current big-task config respects that: for tier-4 multi-phase implementation with a clear dependency graph and expected runtime in hours, it routes to gsd-autonomous. For exploratory features where the spec is unclear and architectural decisions matter more than throughput, it routes to superpowers' brainstorming → writing-plans → subagent-driven-development chain. No single default.
What I'd tell you
If you're a solo dev and you keep bumping into context limits on medium-sized work, you probably need a harness. But don't pick one harness as your default. Pick by work shape:
- Trivial change — vanilla
- Content / cosmetic — vanilla or light-profile big-task
- Standard feature, locked design — superpowers subagent-driven-development (great two-stage review gates)
- Multi-phase implementation, parallelizable across files — GSD's execute-phase engine (lean orchestrator for long runs)
- Unclear spec, architectural decisions — superpowers brainstorming → spec → plan chain
The mistake I made three times was picking a harness first, then forcing the work to fit it. GSD for everything wasted half my tokens on planning ceremony for 3-file features. Superpowers for everything serialized my long runs. Vanilla for everything blew up my context on medium work.
Match the harness to the work shape. The orchestrator on top of those three (big-task, in my case) isn't the important part — it's just a router. What's important is knowing which harness to route to, which requires knowing what the work actually is.
References:
- big-task skill: github.com/xingfanxia/claude-config/blob/main/skills/big-task/SKILL.md
- GSD by TÂCHES: github.com/gsd-build/get-shit-done
- superpowers by Jesse Vincent: github.com/obra/superpowers