harness 得按活的形状挑
这两个月我把自己的 AI 工作流推倒重来了四次。每一次都是被一个具体的 session 逼的,不是看到什么新框架觉得酷就跟风换,反正每次换完没多久,又会撞上一堵新的墙。
起因大概是三月中的一次。我改识川的一个功能,牵涉七个文件,当时就是裸跑 claude code,没脚手架也没 skill,所有事情主线程自己干。改到第四个文件,主线程已经塞满了:读过的每个文件的原文、每次跑失败的测试输出、我对每一轮改动的评注,全在里面。context 到 80%,只能打断,跑 /compact,然后看着模型把三十分钟攒下来的细节状态丢掉。
那次之后我才承认,裸的 cc 就是个 tier-1/tier-2 的工具。单文件、单函数、单问题,它干得很好;活再大一点,主线程就变成 context 的垃圾场。
 主线程单干时把读过的文件、测试输出、评注全吞进 context,到 80% 被迫 /compact,攒下的状态一起丢掉
主线程单干时把读过的文件、测试输出、评注全吞进 context,到 80% 被迫 /compact,攒下的状态一起丢掉
第一版:裸跑 claude code
第一版没什么可讲的,就是裸 claude code:主线程读文件、改文件、跑命令,没有 subagent,也没有 skill。tier-1/tier-2 的活它干得挺舒服的,一个 hotfix、一个 typo、改个函数、问个问题,主线程信噪比很高,干净利落。
问题是活一大就不行了。超过两三个文件,或者要反复跑测试,或者你想同时并行干点别的,主线程会把每一次读的文件、每一次测试输出、每一步推理全吞进去。吞进去就不吐了,或者说吐也能吐(/compact),代价是把攒下来的状态一起吐掉。一个 10 文件的 feature 加上 TDD,不到一小时主线程一定到 80%。
这个我倒不觉得是 claude code 的 bug。「一个线程干所有事」这个模式,本来就干不了团队规模的活。solo dev 的活干着干着也会变大,七个文件、十个文件,其实跟小团队的活已经没什么区别了。
第二版:GSD
第二版换成了 get-shit-done (GSD),TÂCHES 做的一个多 agent 框架。它的思路是把活拆成 phase,每个 phase 跑一条 skill 链:gsd-discuss-phase → gsd-plan-phase(里面内置一个 plan-checker agent)→ gsd-execute-phase → gsd-verify-work → gsd-audit-fix。规划和执行都由 subagent 去做,状态落盘在 .planning/ 目录里。
真的大活它是好用的。我用 GSD 跑过识川的一次完整重设,schema 迁移、新子系统、跨 phase 的依赖全都有。多 agent 规划在执行之前抓出过真 bug;execute-phase 的并行波次跑起来之后,我可以去干别的事。它的 execute 引擎主线程只占 ~15%:subagent 自己从磁盘加载 plan,只回结构化的 summary,不回原文。像这种 tier-4 的活,没这套纪律真的跑不下来,跑到一半就散了。
但 solo dev 的 tier-3 活,用 GSD 就是过度工程了。每个 phase 会生成六个 meta 产物(CONTEXT.md、PATTERNS.md、RESEARCH.md、REVIEW.md、VALIDATION.md、VERIFICATION.md),全在实际的 PLAN.md 之外。
| 项目 | .planning/ 行数 |
|---|---|
| 识川 | ~21,000 |
| ÉLAN | ~24,000 |
这些文档里确实有抓到真 bug 的。但大部分内容,就是同一个「要做什么?风险在哪?会崩在哪?」的 checklist,被六个略微不同的框架重复问了一遍。对 solo dev 来说,把六份读完比代码本身还长。
GSD 我大概用了三周。每次想 ship 一个三文件的小活,都会在心里骂它一遍。但真要扔掉的时候又发现,多 agent 规划确实抓出过会 ship 错的东西,这个不能直接丢。
第三版:superpowers
第三版换成 superpowers,Jesse Vincent 做的一个 skill 库,大约 14 个通用 skill:brainstorming、writing-plans、subagent-driven-development、requesting-code-review、verification-before-completion、test-driven-development、using-git-worktrees、dispatching-parallel-agents。没有 phase 结构,没有 .planning/,哪个 skill 适合当前的活,模型自己调。
我喜欢它的地方是 skill 可以组合,按当前的活挑匹配的,不走固定的 phase 链。subagent-driven-development 每个 task 起一个新 subagent,做两段 review,先查 spec 合规,再查 code 质量,merge 之前能抓住 spec 漂移。它还有一个 session-start hook,自动把 meta-skill using-superpowers 注入每个 session,告诉模型「只要有 1% 概率某个 skill 适用就必须调」。这个设计挺强势的,但真的管用,我再也没漏调过 skill。skill 里还明写了 user instructions > skill instructions,优先级摆得很对。
崩的地方有两个。第一个是 auto-injection 每个 session 固定吃掉 ~5,000 token,不管这个 session 用不用 skill,这笔税都得交。第二个更麻烦:subagent-driven-development 明文规定串行,原文是「Never dispatch multiple implementation subagents in parallel (conflicts)」。对共享文件的实现任务,这个规定是对的,两个 agent 改同一个文件就是 merge 灾难。但这也意味着 superpowers 做不了 GSD execute-phase 那件事:在互相独立的文件上跑并行波次。跑长时间的自动 session,superpowers 就是每个 task 串行走,每个 task 三个 subagent(实现者 + spec 审查 + 质量审查),主线程协调整个序列,所有 task 的文本全塞在主线程里。
到这一步,我手里其实是两个各对了一半的 harness。GSD 的并行波次是真的强,问题是小活也得先过它那一整套规划仪式。superpowers 反过来……也不能完全说反过来,它轻是轻,就是长跑的时候 orchestrator 管不住主线程,这一块 GSD 做得更精简。反正两个我都不想扔,也都不想全用。
 GSD 并行强但规划仪式重,superpowers 轻但长跑串行——两个 harness 各只对了一半
GSD 并行强但规划仪式重,superpowers 轻但长跑串行——两个 harness 各只对了一半
第四版:自己包一个 big-task
第四版就是自己写了一个 orchestrator skill,叫 big-task,把前面三个全藏在一个记得住的名字后面。描述的活涉及 3 个以上文件,或者要引入新功能时,它自动触发。选哪个底层 harness,按工作的形状来定,不预设哪一个,来了活先看活。
它不是要替代那三个。big-task 不重新实现 TDD,合适的时候委托给 tdd-workflow;也不重新实现 subagent dispatch,委托给 superpowers:subagent-driven-development 或者 gsd-execute-phase。它自己就干一件事,把这次的活路由到合适的那个 harness 上。
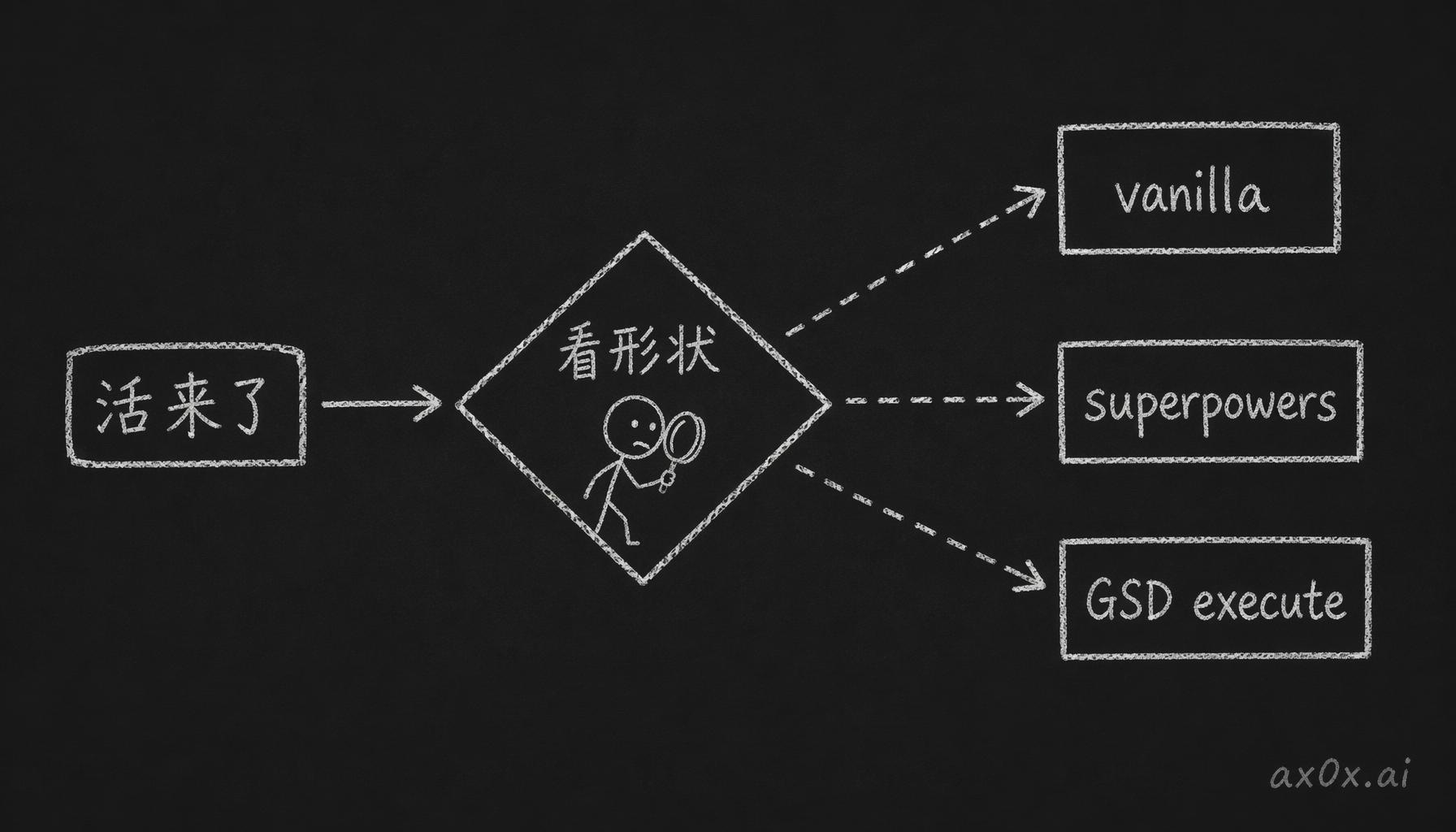 big-task 不设默认引擎,按活的形状把每个任务路由到 vanilla、superpowers 或 GSD execute
big-task 不设默认引擎,按活的形状把每个任务路由到 vanilla、superpowers 或 GSD execute
先扫 repo 形状(Phase 0.0)
在任何 tier 决定之前,big-task 先把项目分成四种 workflow profile 之一:light、ui、heavy 或 unknown。做法是跑一个 bash 启发(~1 秒)去收集信号:
- content-N:
content/posts/、_posts/这类目录里的 markdown 文件数 - components-ui:有
components/目录,加上package.json里有 UI 库(tailwind / radix / shadcn / mui / chakra) - design-ref:
HANDOFF.md、directions/、docs/design/任意一个存在 - schema:有 Prisma / Drizzle / Knex 配置,或者 SQL migration
- auth-payment:依赖里有 Stripe / Better-Auth / NextAuth / Lucia
- playwright:依赖里有
@playwright/test - backend-lang:检测到 Go、Rust 或 Python
规则是首次匹配胜出:content ≥ 20 → light(一个 270 篇文章的博客,就算有 components 目录,它还是个 blog);schema 或 auth-payment 加上 backend 形状 → heavy;components-ui 或 design-ref → ui。
不过光看 repo 形状还不够。
再判断任务意图(Phase 0.0 的第 2.5 步)
repo 扫描看的是 codebase 本身,你这一次让它干什么活,它其实不知道。blog repo 是 light,但「给 premium 文章加 Stripe paywall」是个 heavy 任务,只是碰巧落在一个 light repo 里。这种活我不在乎 repo 信号怎么说——它跨了 trust boundary,动的是 revenue 路径,不管 repo 什么形状都得走 heavy。
第一版的实现用的是关键词匹配:扫描任务描述里有没有 stripe / auth / migration / schema,有就强制 heavy。这个做法现在回头看真的很蠢。你本来就有一个 LLM 在读任务描述,在 LLM 的 context 里拿 regex 去过自然语言,就是反模式。「我昨天在看 Stripe 的 API」和「集成 Stripe 支付」完全不是一回事,但两句话里都有 Stripe 这个词。
改法是把关键词列表换成判断标准,让模型去分类这个任务对系统做了什么。本质重的活:持久化变更、trust boundary、revenue 路径、原子性/并发、跨系统合约、引入新的架构子系统。本质轻的活:书面文字、纯视觉微调、单一稳定 schema 上的配置改动。UI 性质的活:套用已有的设计模式,已知模式的第 N+1 次应用。
还定不下来的时候,再问几个框架问题:爆炸半径有多大(客户的钱,还是一个糟糕的下午);可逆性怎么样(git revert 就能回,还是要做数据迁移回滚);这是个设计决定还是设计翻译;模式的新颖度有多高。
组合规则按顺序走:本质重 → heavy,不管 repo;本质轻 → light,不管 repo;引入新模式 → max(repo, 上一档);其余的用 repo profile。改完我自己都有点意外,新规则写出来比原来那个关键词列表还短,判断反而准了。
subagent 派发策略
最后一块是今天才加的。big-task 里每个 phase 现在带一行 Subagent policy,按工作性质选,不按 tier 选:
| 模式 | 何时用 | 主线程占比 |
|---|---|---|
| parallel-worktree | 独立文件上的实现 | <20% — 每个 subagent 在自己的 worktree 写 |
| parallel-readonly | 调查、审查、审计、视觉验证 | <20% — 每个目标一个 subagent |
| serial-subagent | 共享文件上的实现 | ~30% — superpowers 的 subagent-driven-development,每 task 新 context |
| inline | 单文件改、tier-2 hotfix、琐碎决策 | 100% |
再配一条强制规则:tier ≥ 3 且独立任务 ≥ 3 个时,绝不 inline。活到了这个规模还 inline,主线程一定臃肿,subagent 架构的整个意义就没了。
orchestrator 自己的纪律,跟模式选择一样重要。subagent 自己从磁盘加载输入,主线程不把 task 全文塞进每个 subagent 的 prompt。superpowers 的 controller 在一个 20 task 的 plan 上,就是这么不小心把 context 囤爆的。subagent 回传的是 ≤200 token 的结构化 summary,不是原始输出;状态放磁盘,不放 chat history;并行之前先用 worktree 隔离,这样就绕开了「禁止并行实现者」那个共享状态的门槛。
进 phase 的时候要声明模式,比如 Phase 2b · parallel-readonly (4 routes)。这样路由是可审计的,也抓得住 inline 滥用:连续三个 phase 都声明 inline,但活还是 tier-3 的,那一定哪儿错了。
GSD 这件事我两个月才看明白
有一个东西我差点扔掉。GSD 的规划开销是真的重,每个 phase 六个 meta 产物。但它的 execute-phase 引擎本身是精简的,orchestrator 跑在 ~15% 的主线程 budget 上,因为 subagent 自己从磁盘加载 plan、只回 summary。对长时间的自动跑(你不在旁边盯着、希望实现自己走完的那种活),这套纪律真的很牛,我只能说目前没见过更好的。
我之前是把规划开销和执行开销搞混了。想扔 GSD 的时候,想扔的其实是 gsd-discuss-phase 和 gsd-plan-phase 的那套仪式,不是 gsd-execute-phase 的机制。把这两个东西分开看,花了我一点时间。
现在的 big-task 配置尊重了这一点:tier-4 的多 phase 实现、依赖图清楚、预计要跑好几个小时的活,路由去 gsd-autonomous;spec 不清楚、架构决策比吞吐量更重要的探索性 feature,路由去 superpowers 的 brainstorming → writing-plans → subagent-driven-development 链。反正现在没有哪个是默认的,每次都是看活。
如果你也是 solo dev,中等规模的活总撞 context 上限,那大概率你也需要一套 harness。挑的方式就是按工作的形状:
- 琐碎改动:vanilla 就够了。
- 内容或者纯视觉的活:vanilla,或者 light profile 的 big-task。
- 标准 feature、设计已经锁死:superpowers 的 subagent-driven-development。
- 多 phase 实现、跨文件可以并行:GSD 的 execute-phase 引擎。
- spec 不清、架构决策重:superpowers 的 brainstorming → spec → plan 链。
回头看,前几轮我基本都是先把 harness 定下来,活来了再往里塞。用 GSD 那阵子最明显,三文件的小 feature 一半 token 花在规划仪式上,我还跟自己说这叫纪律。后来才慢慢改成先看活再挑工具。big-task 那个 orchestrator 也没什么神奇的,就是把「这个活该用哪套」这个判断自动化了,省得每次自己想一遍。目前用着还行,说不定过俩月又推倒了,到时候再写一篇。
链接:
- big-task skill:github.com/xingfanxia/claude-config/blob/main/skills/big-task/SKILL.md
- GSD(TÂCHES):github.com/gsd-build/get-shit-done
- superpowers(Jesse Vincent):github.com/obra/superpowers
