I Added a Claude Code Skill That Forces Planning Before Code
Where This Started
I recently saw something that got me excited. ByteDance's Trae IDE has a mode called MTC — More Than Coding. Unlike the standard code editing mode, MTC is a full-stack agent: it handles design, analysis, data generation, documentation, and oh yeah, it also writes code.
A developer named Peng Chao used it to build a complete puzzle game in two hours. Zero handwritten code. A game called ClassOS. I played it, then immediately wanted to do the same. But I use Claude Code, not Trae.
So I built a /mtc skill in Claude Code that replicates this workflow.
This post covers what the skill does and why I think it beats typical vibe coding.
Everything Before the Code
MTC's core thesis clicks for me: MTC isn't a watered-down version of Code mode — it's "everything before the code."
When Peng Chao built ClassOS, he revised the script three times, generated five mock data files, and broke the competitive analysis into five dimensions. All of that happened before writing a single line of code.
The order matters.
Most vibe coding fails because humans start with a vague idea, tell the AI to build it, then halfway through realize something's wrong with the concept. They fix the concept, which breaks the data, which breaks the code. Every phase overturns the previous phase. What ships is a patchwork.
MTC's approach: each phase produces a file. Phase 1 outputs a script doc. Phase 2 outputs a data design doc. Phase 3 outputs a system architecture doc. Each phase feeds the next. No skipping.
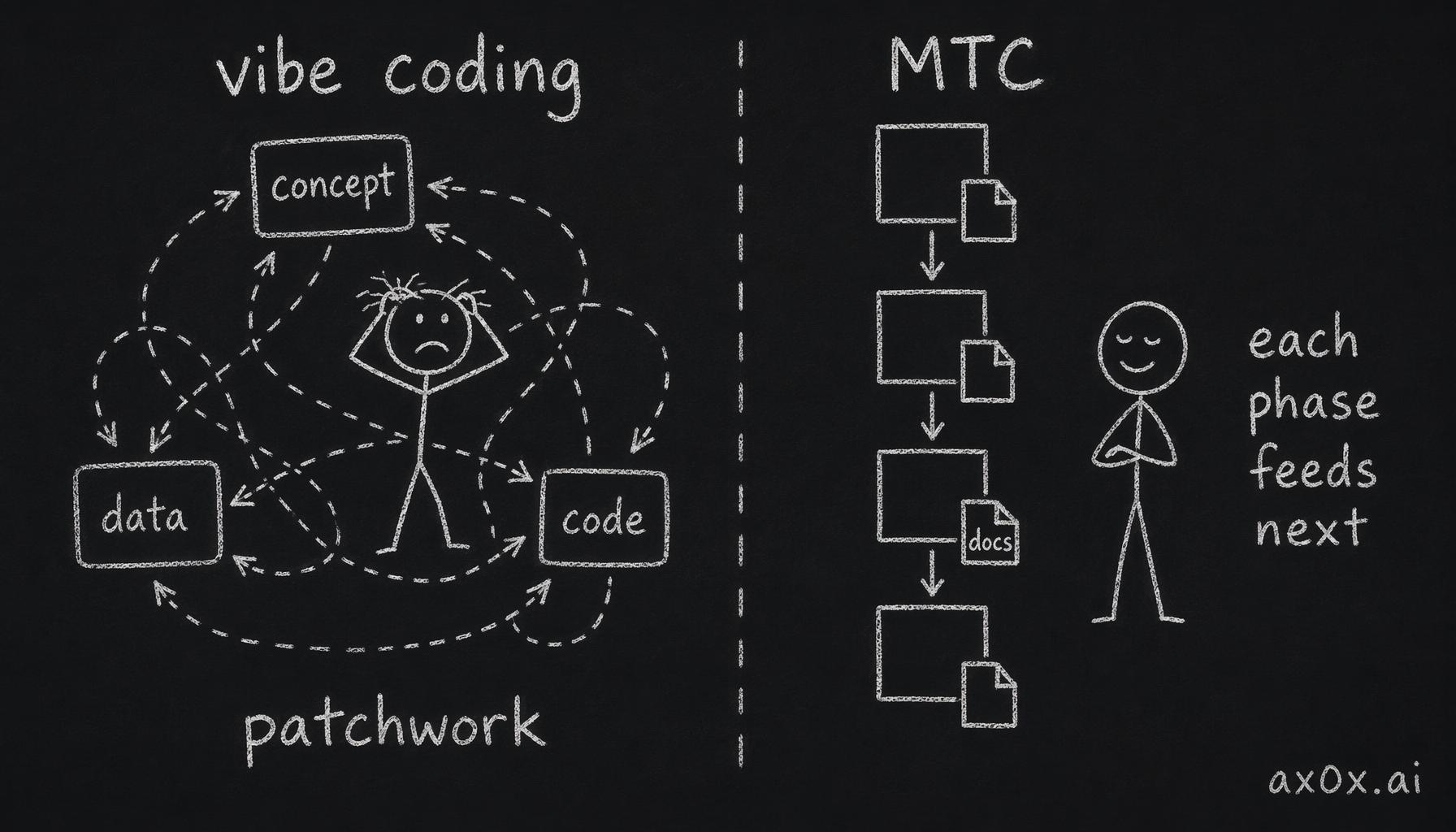 Contrasts vibe coding's back-and-forth rework with MTC's forward-only pipeline where each phase drops a doc
Contrasts vibe coding's back-and-forth rework with MTC's forward-only pipeline where each phase drops a doc
10 minutes of concept work saves 1 hour of rework.
The 6 Phases
I broke MTC's methodology into 6 phases and turned it into a Claude Code skill:
Phase 0: Context Gathering — What are you building? For whom? What should it feel like? No documents produced — just direction alignment.
Phase 1: Concept & Narrative — Story and concept iteration. Forces V1 → self-critique → V2 → V3. The critical rule here: the AI must critique its own V1, not stop at V1.
Phase 2: System Design — Mechanics, progression, information architecture. Output: a system design document.
Phase 3: Data & Content — Mock data generation. All data must align with the narrative. A character's chat history must match their personality profile.
Phase 4: Build — Write the code. By now, all prior documents are inputs. The AI doesn't need to decide what to build, only how.
Phase 5: Polish — Sound effects, animations, easter eggs. No new features at this stage, only texture.
Each phase outputs files to docs/, which become inputs for the next phase. Phases 3 and 4 can spawn subagents to parallelize when subtasks are independent. Every phase ends with a user checkpoint.
Why You Can't Skip Phases
You might think: if the concept is already clear in my head, why write it down? Why not just have the AI start coding?
Because you forget.
Not the AI — you. Three days from now, you'll look at the code and notice a mechanic that doesn't match the concept. You won't know if the concept was wrong from the start, or if the AI drifted during implementation. If every phase has a document, you can go back and see the original decision.
There's a more critical reason though. The AI critiquing its own V1 must happen in a dedicated phase. If you let it reflect on concept while writing code, it won't reflect. It will just keep writing.
Phase 1's rule: after V1 ships, the AI is required to list 3 problems with it, then propose a V2 direction for each problem, and let the user pick. The structure forces reflection.
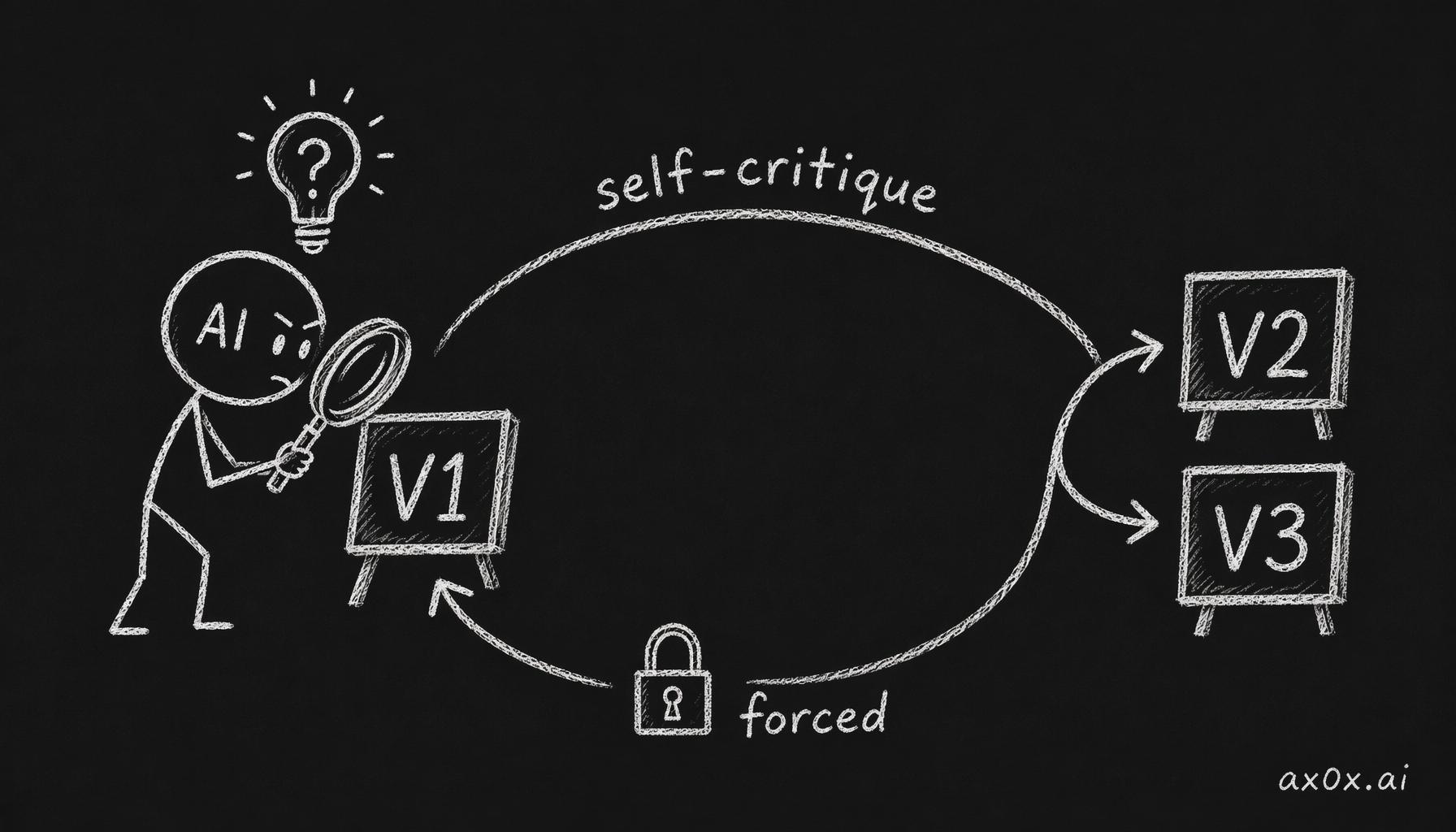 Phase 1 forces the AI to critique its own V1, list problems, and iterate into V2 and V3
Phase 1 forces the AI to critique its own V1, list problems, and iterate into V2 and V3
When I was designing Inside Job, V1 looked fine — I couldn't articulate what was off. But Claude Code, following Phase 1's rules, critiqued its own V1, identified three problems, and proposed three V2 directions. When V2 came back, I was genuinely impressed: it had broken "solid but predictable" into three specific issues, proposed three improvement directions, and when I said "combine all three," it merged them into a three-layer narrative structure.
This kind of self-critique isn't something AI does by default. The workflow forces it.
How It Pairs With Subagents
Claude Code has a great capability: spawning subagents to work in parallel. /mtc's Phases 3 (data generation) and 4 (coding) benefit the most from this.
For Phase 3, a game might need mock chat logs, emails, photo metadata, calendar events — all independent. You can spawn 4 subagents in parallel. Each subagent focuses on one data type, which keeps attention tight and speeds things up.
Phase 4 coding works the same way. Frontend components can be split across subagents. The main agent handles integration and architecture decisions.
Key constraint: subagent parallelism only happens in Phases 3 and 4. Phase 1 (concept) must stay single-threaded, because concept iteration needs a global view — splitting it creates chaos.
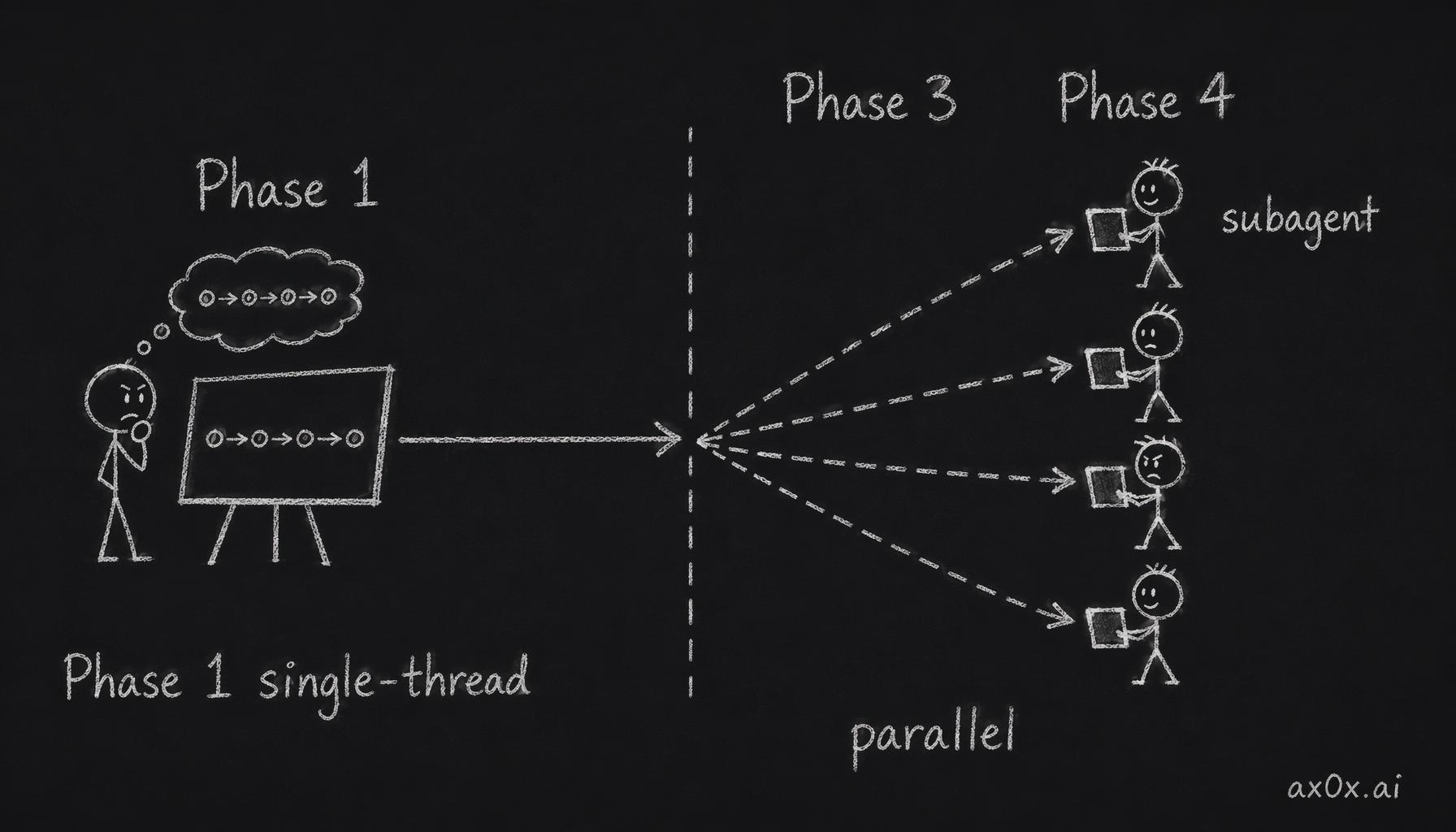 Concept must stay single-threaded; only Phases 3 and 4 fan out into parallel subagents
Concept must stay single-threaded; only Phases 3 and 4 fan out into parallel subagents
Not a Silver Bullet, But Worth It
The cost of using /mtc is that you spend 30-60 minutes on pre-work before writing any code. For small changes, this is overkill.
But for a full project, that 30-60 minutes saves hours of rework every time. Inside Job's pre-work took 40 minutes to produce the concept and system design docs, then implementation began. Compared to my past experience with direct vibe coding on small projects, I saved at least 2-3 hours of debugging and rework.
More importantly, this workflow raises the quality of the AI's output. It's not writing code in a local context — it's writing code guided by a complete design. The difference between these two modes is significant.
Trae's MTC is a great idea. Claude Code users can have it too — just takes a bit of skill-building. My setup is already making three games, and the results are better than expected.
The series is called I Am the AI Game Producer — check it out if you're curious.