The Memory Wall
 A pyramid of memory tiers, from SRAM at the narrow top to HDD at the wide base
A pyramid of memory tiers, from SRAM at the narrow top to HDD at the wide base
I finance the machines AI runs on. At Compute Labs we buy GPU clusters, build the data centers to house them, and turn that compute into a financial asset other people can underwrite. So when I look at an AI server, I don't see a model. I see a bill of materials — every component, what it costs, how long it lasts, how scarce it is.
The first time I went through that bill of materials carefully, I expected the GPU die — the logic, the thing everyone calls "the chip" — to dominate. It doesn't, not the way you'd think. A large and growing share of the cost, and almost all of the supply anxiety, sits in something most people writing about AI never mention by name: the memory stacked right next to the processor.
That detail matters more than it sounds when your job is underwriting these assets. When you finance hardware, you live and die on two questions: what's the residual value, and what's the risk of the supply chain. For most of computing history the answer was boring — the logic die was the prize, the memory was a commodity you topped up at spot price. AI inverted that. The piece I now worry about most, the piece a cluster's economics actually hinge on, is the memory. If I can't get it, I can't build the box. If its price moves, my model moves.
That was the surprise that started this series. The part of the box that's hardest to get, that prices keep climbing on, that the whole industry is now fighting over — it isn't the FLOPS. It's the memory that feeds them.
This piece is the map. Six articles, top to bottom of the memory stack. We start with the most important and least understood idea in all of it: the wall.
The thing nobody buys is the thing that's scarce
Here is the cleanest way to see it. A modern flagship accelerator pairs a logic die with a ring of high-bandwidth memory — HBM — sitting on the same package. The logic die is what the marketing slides count in teraFLOPS. The HBM is what actually gates how fast that logic can work, and it is the harder thing to make.
You can feel this in the supply chain. Through 2024 and 2025, the constraint on building AI systems was rarely "we can't fab enough logic." It was "we can't get enough HBM." HBM sells out years forward. The companies that make it — three of them, really — have become some of the most valuable in the world on the strength of it. I'll get to those numbers in the supercycle piece. For now, just hold the shape of it: the bottleneck moved off the compute die and onto the memory next to it — the same dynamic I traced in TPU vs GPU, where everyone, Nvidia and Google alike, ends up fighting over the same scarce supply.
In an earlier essay I argued that compute is the root of all intelligence — that capability follows the machines. That's still true. This series is the sequel, and it's narrower and more uncomfortable: the bottleneck inside compute is now memory. You can own all the FLOPS you want. If you can't feed them, they sit idle.
To understand why, you have to understand that "memory" isn't one thing. It's a pyramid.
Memory is a pyramid, and every layer is a trade
Every computer ever built is a stack of memories trading off the same three things: speed, capacity, and cost per bit. You cannot have all three. Fast memory is expensive and small. Cheap memory is slow and huge. So engineers build a hierarchy — a little bit of blisteringly fast memory near the processor, a lot of slow cheap storage far away, and tiers in between.
For an AI accelerator the pyramid looks roughly like this:
Now put real numbers on it. This single table is the whole foundation of the series, so it's worth reading slowly. Notice that from top to bottom latency rises by about seven orders of magnitude, while across the working-memory tiers bandwidth falls by roughly four orders of magnitude and cost per gigabyte by about three.
| Tier | Bandwidth | Latency | Cost per GB |
|---|---|---|---|
| SRAM (on-die cache) | effectively unbounded on-chip | ~1 ns | very high (not sold by the GB) |
| HBM (on-package) | ~1.2 TB/s per stack; ~8 TB/s across a flagship GPU | ~100 ns class | ~$10–20+ |
| DRAM / DDR5 (system) | ~50–70 GB/s | ~80–100 ns | ~$3–8 |
| NAND / NVMe SSD | ~7–14 GB/s | ~10–100 µs | ~$0.06–0.15 |
| HDD | ~250 MB/s | ~5–10 ms | ~$0.02 |
Read the extremes against each other. HBM moves data on the order of a thousand times faster than an SSD, and a thousand times faster still than a hard drive. And it costs roughly a hundred times more per gigabyte than NAND, and five hundred to a thousand times more than an HDD. That is not an accident or a markup. It's physics, and it's the whole reason the pyramid exists.
The HBM number for an H100 — ~3.35 TB/s — and the ~8 TB/s on a newer flagship are the headline figures. Hold onto them. The entire argument below turns on the gap between how fast a GPU can compute and how fast its memory can feed it.
Closer to the processor means faster, smaller, and more expensive
Why is the pyramid shaped this way? Three constraints, all physical.
Distance is latency. Electricity is fast but not infinite — signals travel a few centimeters per nanosecond. Memory physically next to the processor answers in about a nanosecond. Memory across the board answers in tens to a hundred. Storage down a cable answers in microseconds to milliseconds. You can't argue with the speed of light, so the only way to be fast is to be close.
Close is small. The space immediately around a processor die is the most contested real estate in the machine. There's room for a few tens of megabytes of SRAM on the die itself, and for a handful of HBM stacks on the same package — call it a couple hundred gigabytes at the frontier. Everything bigger has to live farther out, which means slower.
Fast-and-close is expensive. SRAM uses six transistors to hold one bit so it can switch instantly; DRAM uses one transistor and one capacitor, which is denser and cheaper but slower. HBM gets its bandwidth by stacking DRAM dies vertically and wiring them with thousands of through-silicon vias, then mounting the whole stack next to the logic on a silicon interposer. That's a hard, low-yield manufacturing process — which is exactly why HBM costs what it does, and the subject of a later piece in this series.
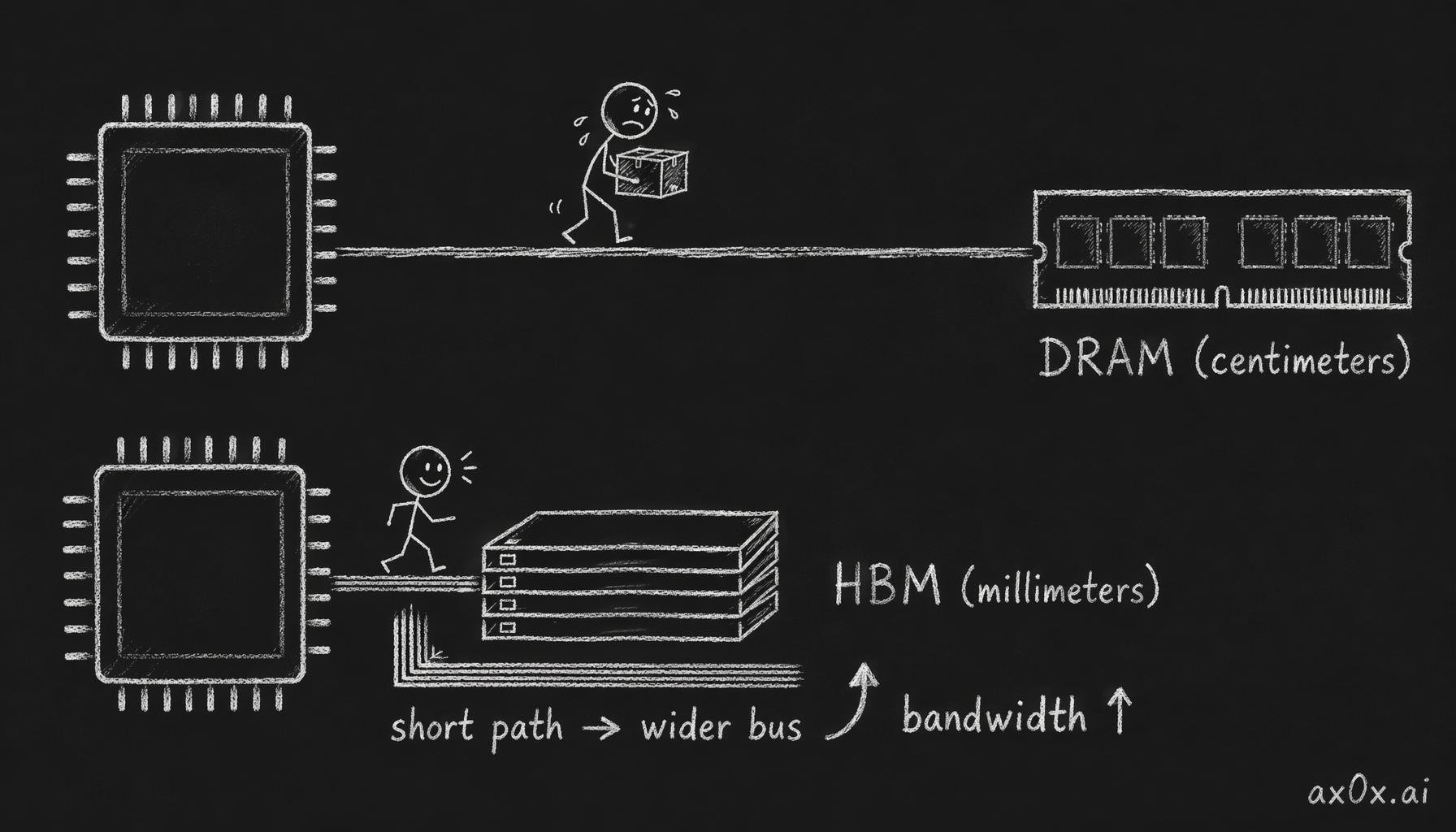 HBM stacks memory right next to the logic on an interposer, cutting the data path from centimeters to millimeters so the bus gets wider and bandwidth rises.
HBM stacks memory right next to the logic on an interposer, cutting the data path from centimeters to millimeters so the bus gets wider and bandwidth rises.
So the rule of the pyramid is simple and unforgiving: closer to the processor = faster + smaller + pricier. Every system design is a negotiation up and down this stack. You want a working set to live as high in the pyramid as it can afford to, because every tier you drop costs you orders of magnitude in speed; but the higher tiers are tiny and brutally expensive, so most data has to live lower than you'd like. That tension — wanting everything fast and close, but only being able to afford a sliver of it — is the central problem of computer architecture, and it predates AI by half a century.
AI didn't change the rule. AI just shoved a workload into it that's brutally sensitive to the top two layers — and ran straight into a wall that's been there, named and documented, for thirty years.
The memory wall is not new — it's just finally binding
In 1995, two computer architects, Wm. A. Wulf and Sally A. McKee, published a short, ominous paper called "Hitting the Memory Wall." Their observation was almost arithmetic. Processor speed was improving far faster than memory speed. If that gap kept widening — and there was no reason to think it wouldn't — then sooner or later the processor would spend essentially all its time waiting for data, and making the processor faster would stop helping at all. They called that endpoint the memory wall.
The numbers since have been merciless. Over the two decades following that paper, raw compute throughput scaled by something on the order of 60,000x. Over the same stretch, DRAM bandwidth improved roughly 100x — and DRAM latency, the time to fetch a single piece of data, barely moved at all. Compute ran away. Memory crawled. The gap Wulf and McKee warned about didn't close; it became a canyon.
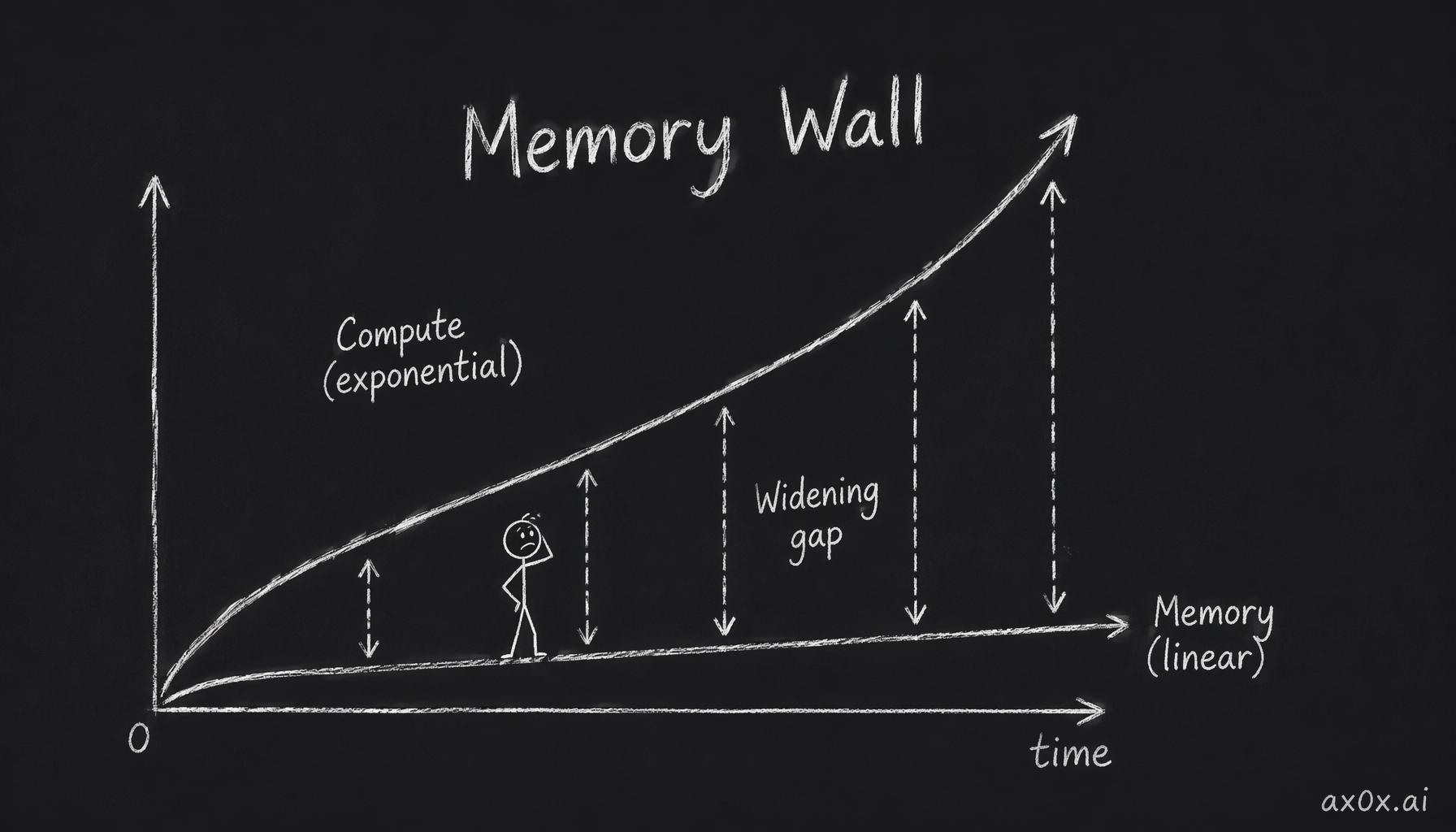 Compute climbs exponentially while memory only grows linearly, and the ever-widening gap between the two curves is the memory wall.
Compute climbs exponentially while memory only grows linearly, and the ever-widening gap between the two curves is the memory wall.
For a long time, clever engineering papered over the canyon. Bigger caches, deeper prefetching, smarter scheduling, branch prediction, out-of-order execution — a whole discipline devoted to hiding the wait so the processor stayed busy while data was in flight. The bet underneath all of it is the same: that the data you need next is either already close, or predictable enough to fetch before you ask for it. When that bet holds, the wall is invisible. Most software, most of the time, reuses a small working set in tight loops, and the caches catch it. You never feel the canyon because you almost never have to cross it.
Then came a workload that breaks the bet. A workload where the data you need next is all of it, every time, and there's nothing to reuse and nothing to predict your way around. A workload that defeats nearly every one of those tricks at once.
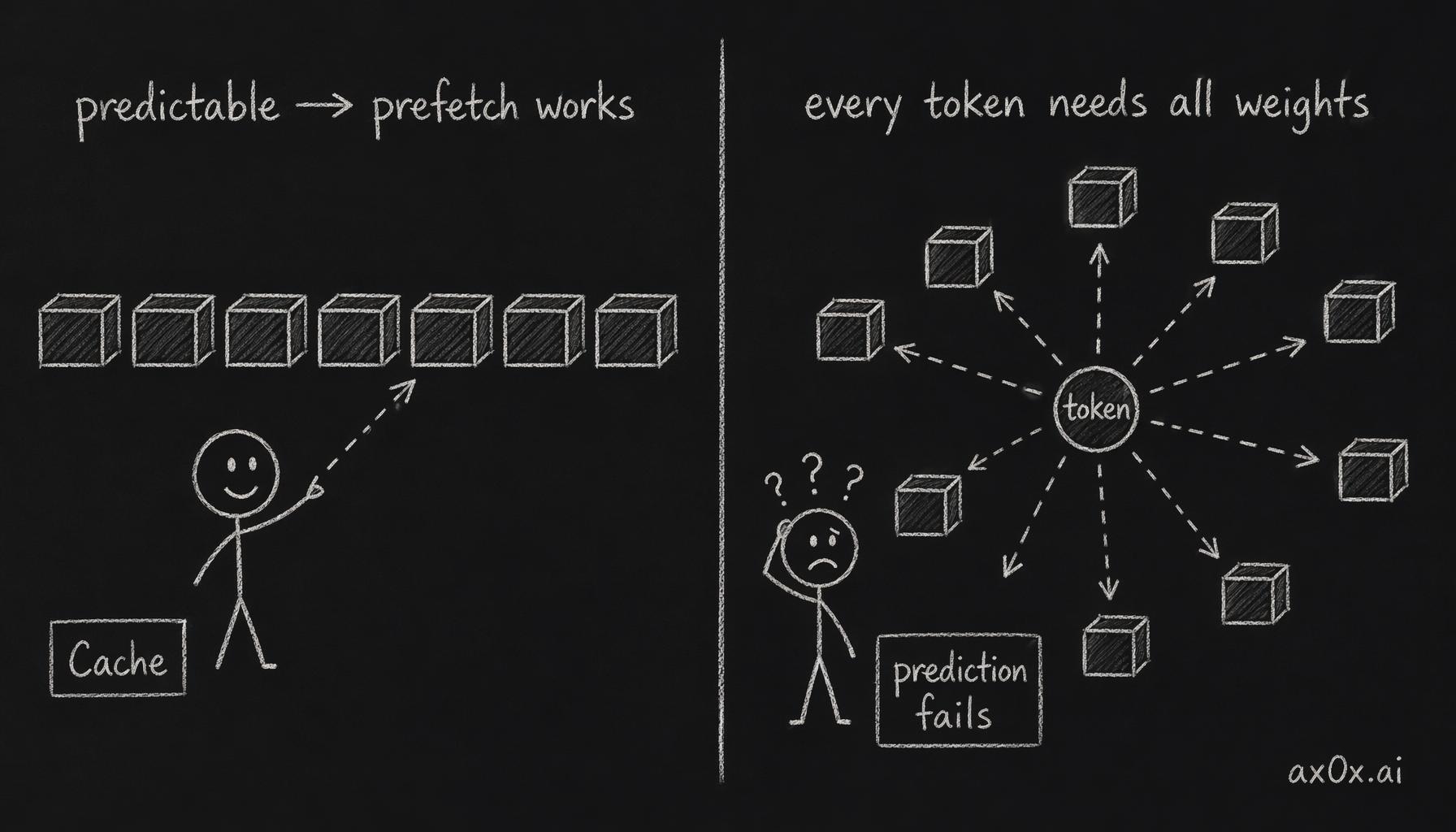 Caches prefetch by prediction and win when access is regular, but AI needs all the weights for every token, so the prediction bet collapses.
Caches prefetch by prediction and win when access is regular, but AI needs all the weights for every token, so the prediction bet collapses.
Generating a token is a memory problem, not a math problem
Here's the part that reframes everything, and it's the reason this series exists.
When a large language model writes its answer, it does it one token at a time. To produce each new token, the GPU has to read the model's weights — all of them, or all of the relevant ones — out of memory, do a comparatively small amount of arithmetic, and emit the next token. Then it does it again for the token after that. And again. This phase is called decode, and it is the phase you actually wait on when you talk to an AI.
The thing that gates decode is not how fast the GPU can multiply. It's how fast it can read the weights out of HBM. The arithmetic per token is tiny next to the volume of data that has to be streamed to do it. Decode is memory-bandwidth-bound.
There's a clean way to see why. Architects talk about arithmetic intensity — how many math operations you do per byte you fetch from memory. If you do a lot of math per byte, you're compute-bound and the FLOPS matter. If you do little math per byte, you're memory-bound and bandwidth is the only number that counts. Generating one token at a time has terrible arithmetic intensity: you drag the entire weight set across the bus to produce a single token's worth of output. There's almost no math to amortize that traffic against. On top of the weights, the model also has to re-read its growing memory of the conversation so far — the KV cache, which I'll dig into later in this series — and that traffic only grows as the context gets longer. Either way, the bus is the bottleneck, not the math.
The consequence is stark, and once you've seen it you can't unsee it. During single-stream decode, a flagship GPU can run at just a few percent of its peak FLOPS — the math engines starve hundreds of times below their ceiling. A batch-of-one decode does on the order of one or two floating-point operations per byte it reads, against a ridge point that wants roughly 591. The expensive math units — the thing the whole chip is named and sold for — sit idle most of the time, starved, waiting on memory.
Put concrete numbers on it. An H100 can do on the order of 1,000 teraFLOPS of dense FP16 math. It is fed by HBM at ~3.35 TB/s. During token generation, that ~1,000 TFLOPS of compute is throttled by that ~3.35 TB/s of bandwidth — and the bandwidth, not the math, sets the speed. You bought a sports car and you're stuck behind the on-ramp's speed limit. Buying a faster engine doesn't help. Widening the on-ramp does.
It's worth being precise about where this bites, because it doesn't bite everywhere equally. Training a model, and the prefill phase of inference — where the model reads your whole prompt at once before it starts answering — both have high arithmetic intensity. You're doing big dense matrix multiplies over batches of data, lots of math per byte, and the FLOPS earn their keep. That's the workload the marketing benchmarks are built around, and on that workload a flagship GPU really does scream.
It's decode — the one-token-at-a-time generation that happens every time anyone uses the thing — that falls off the cliff. And decode is most of what production AI actually is. A model is trained once and then serves answers billions of times. The lifetime of an AI system is overwhelmingly spent in the memory-bound phase, not the compute-bound one. So the benchmark that sells the chip and the workload that runs on it are measuring two different worlds.
This is why "we have the most FLOPS" stopped being the flex it was in 2020. For the part of AI that runs all day, every day, the binding constraint is whether you can feed those FLOPS. Memory bandwidth and capacity are the real spec sheet now.
Where the money went
So follow the money, because the money already moved.
When the constraint was logic, the value pooled around whoever made the best logic die. When the constraint shifted to memory, the value started pooling around whoever can supply the memory — and specifically the HBM that sits on the package. The HBM market was roughly $35 billion in 2025 and is projected toward $100 billion by 2028 at around 40% CAGR (Micron IR), with 2027 estimates spanning $68–90 billion across TrendForce, Yole, and JPMorgan. HBM content per flagship GPU has roughly doubled about every two years — from 80GB on the H100 in 2022 to 288GB on the B300 in 2025. More memory per chip, more chips, higher prices per gigabyte. That's three multipliers stacked on top of each other, all pointing the same way.
That's the story this series tells, layer by layer. The wall is the why. Everything after it is the consequence:
- DRAM — the commodity workhorse underneath all of it, and the supercycle it's caught in.
- NAND and the cold tier — where data goes when it doesn't need to be fast.
- How HBM actually works — the stacking, the vias, the packaging, the yield, and why it's so hard and so expensive to make.
- The supercycle — the financials, the capex, the three companies, and the prices.
- The frontier — what comes after HBM, and whether the wall can be moved at all.
(The DRAM and NAND pieces are next up in the series.)
I came into this expecting to write about compute. I keep ending up writing about memory, because that's where the constraint actually lives. The industry spent a decade asking who had the most FLOPS. The more useful question now is the quieter one: who can feed them?


