电脑卡,多半是处理器在等内存
训练过神经网络的人大概都见过这个场景:GPU 利用率飘在 60% 上下,怎么都拉不满。卡是好卡,钱也花了,它就是跑不满。为什么啊?其实那些时间里处理器都在干等,等数据从内存过来。这个事也不光 GPU 有——你 Chrome 开三十个标签,切过去白屏半秒;翻一个很大的 Excel,卡一下。多半也是同一个原因,处理器在等内存。
先看两个数字
过去五十年,处理器的算力涨了大概 (10^{12}) 倍;DRAM 的访问延迟,降了大概 4 倍。没写错,就是万亿倍对 4 倍。带宽那边也好不到哪里去:内存带宽一年涨 15% 左右,算力需求一年翻一倍。一边指数一边线性,差距拉了二十年,还在越拉越大。所以每次你觉得电脑「卡」,处理器多半闲着呢,活儿全堵在数据还没到这一步上。
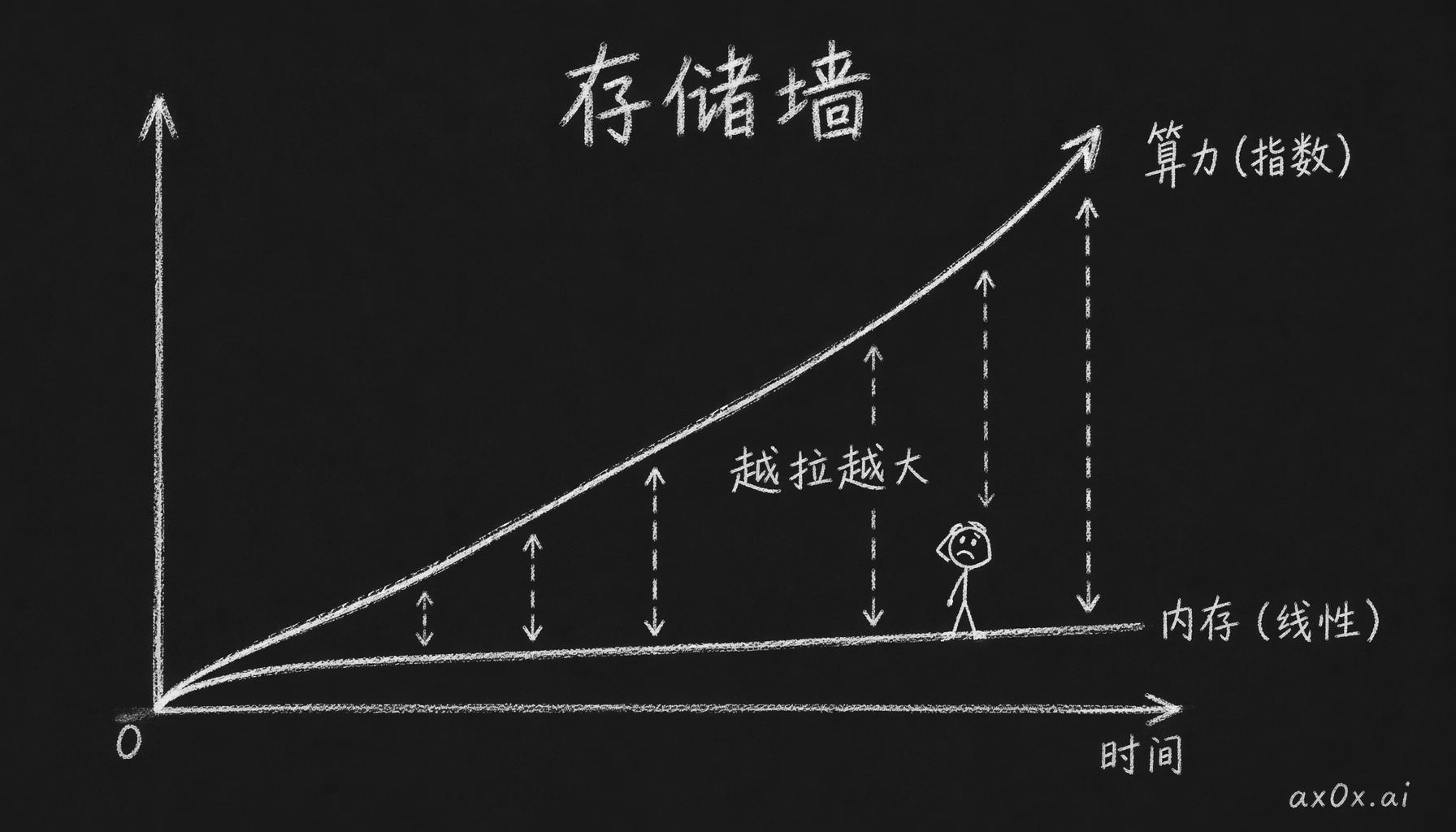 算力指数增长、内存只线性增长,两条曲线之间的缝隙越拉越大,就是「存储墙」。
算力指数增长、内存只线性增长,两条曲线之间的缝隙越拉越大,就是「存储墙」。
这笔账其实早就有人算过。1994 年,William Wulf 和 Sally McKee 写了篇论文,叫 Hitting the Memory Wall。结论是按当时的趋势推下去,用不了几年,处理器速度就会被内存带宽完全锁死,加再多核心也没用——每个核心都在等饭吃。「存储墙」这个说法就是从这来的。这篇论文到现在快三十年了,问题不但没解决,在某些领域反而更严重了。
那问题来了:内存凭什么就是跟不上啊?
内存为什么跟不上
DRAM 的基本结构,从 1970 年代到现在就没变过:一个电容,存 1 或者 0,隔一段时间刷新一次,防止电漏光了。读数据的流程是给出行地址和列地址,等电容放电,放大器把电压读出来。
卡就卡在「等电容放电」这一步。电容放电是个物理过程,速度是物理定律定死的,几十年下来优化空间极小。说白了就是这一步快不起来,你换什么架构它都快不起来。你可以把马路修宽,也就是加带宽;但每辆车的车速提不上去,也就是延迟降不下来。
还有个更根本的矛盾。芯片上晶体管数量翻倍,是在二维平面里长的;数据要在不同芯片之间跑,走的是三维空间里实打实的物理距离。所以搬数据花的能量和时间,远远高于计算本身——算这一下本身花不了多少电,大头全在把数据搬到能算的地方这一路上。
三层缓存,治标不治本
CPU 的应对办法大家多少听说过:L1/L2/L3 三层缓存。把数据预测性地从慢的 DRAM 搬到快的 SRAM 缓存里,处理器直接从缓存拿。
这套机制管用了很多年,但它有个前提:程序访问数据得有规律,你才猜得到它下一步要什么。深度学习恰好把这个前提打破了。神经网络每一层的权重摊在内存各处,每个 token 都要访问全部参数,注意力机制的访问又稀疏又随机,缓存的预取算法根本预测不了。
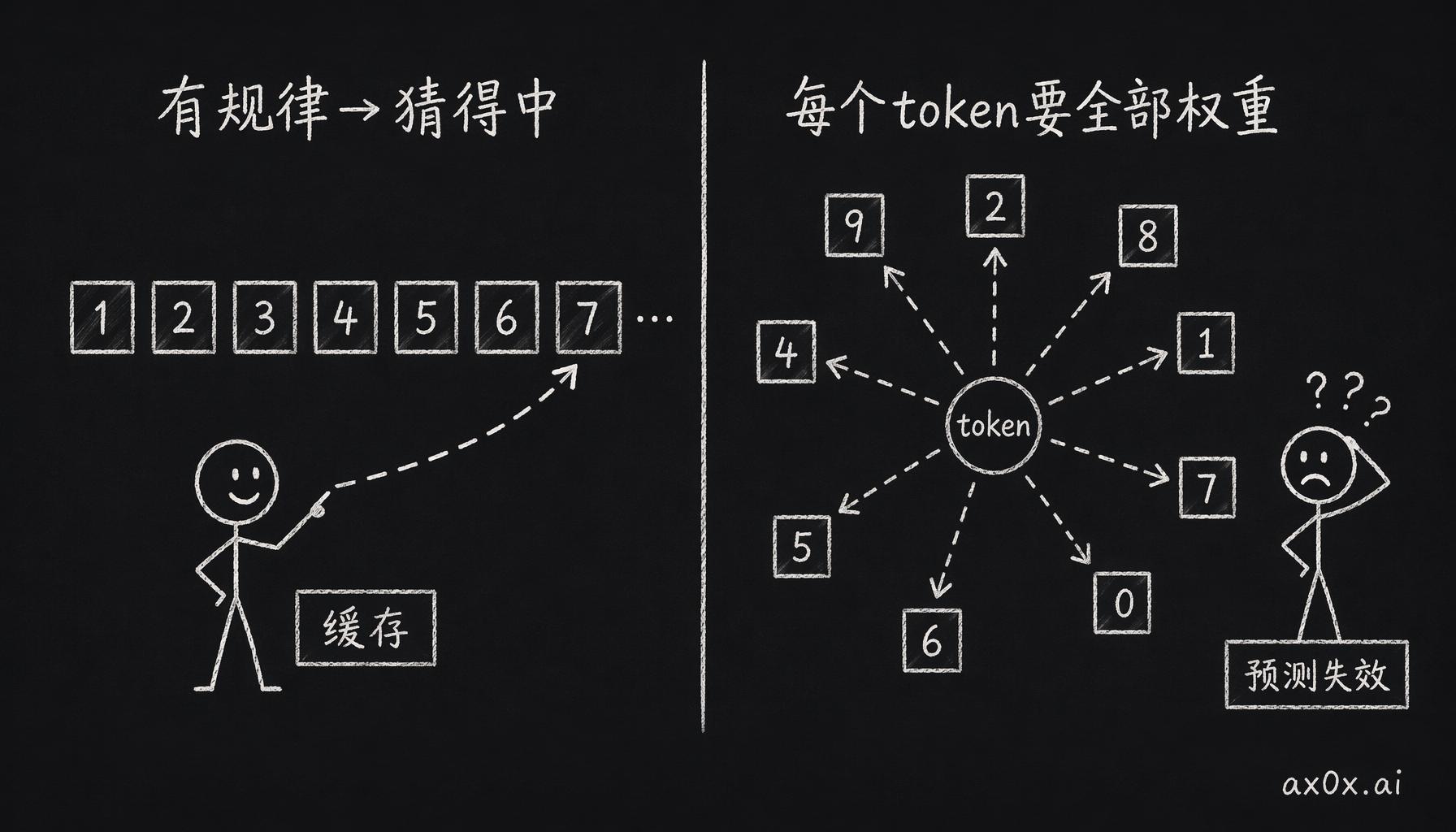 缓存靠预测提前取数据,访问有规律时猜得中;但 AI 每个 token 要访问全部权重,预测彻底失效。
缓存靠预测提前取数据,访问有规律时猜得中;但 AI 每个 token 要访问全部权重,预测彻底失效。
GPU 的思路不一样:不猜了,用海量线程把延迟盖过去。这一组线程在等数据?那就切到另一组先算着。听着挺聪明吧?但它的前提是手里得有足够多的线程可以切。batch size 小到 1 的时候,也就是实时推理的场景,这招就失效了。
所以墙还是没绕过去。那这堵墙到底卡在哪啊?拆开看,带宽、延迟、功耗,三个地方都堵着。
带宽、延迟、功耗,三个地方都堵
最常撞上的是带宽。GPU 的 FLOPS 早就够快了,实际吞吐是内存带宽说了算。H100 的显存带宽大概 3.35 TB/s,听着很大吧?但 GPT-4 这个级别的推理,每个 token 都要把模型参数全部访问一遍。拿带宽除以参数总量你就会发现,模型越大,每秒能处理的 token 反而越少。
延迟是另一码事。就算带宽堆够了,从发出数据请求到数据真的到手,中间那段等待还是省不掉,处理器就在那干等。平时大家都盯着带宽数字看,这一块反而容易被忽略。
再往下挖是功耗,我觉得这个才是最要命的。搬数据烧的电,比计算本身高出好几个量级。同一颗芯片上两个晶体管之间搬一下,和跨芯片、跨板卡搬一趟,能耗能差 (10^3) 到 (10^4) 倍。AI 数据中心的总功耗里,40% 到 60% 都烧在搬数据这件事上,真正用来算的反而是小头。而且这个是物理极限,工艺再怎么进步也绕不开。
HBM 是怎么缓解的
HBM,全称 High Bandwidth Memory,名字听着像是更快的内存,其实它干的事说白了就一件:把内存搬到芯片旁边。传统 DRAM 焊在 PCB 上,数据要走好几厘米才到芯片;HBM 用一层硅中介层(interposer),把 DRAM 直接堆叠在芯片边上,数据路径缩到几毫米。路径短了,总线就能做得更宽,带宽就上去了。
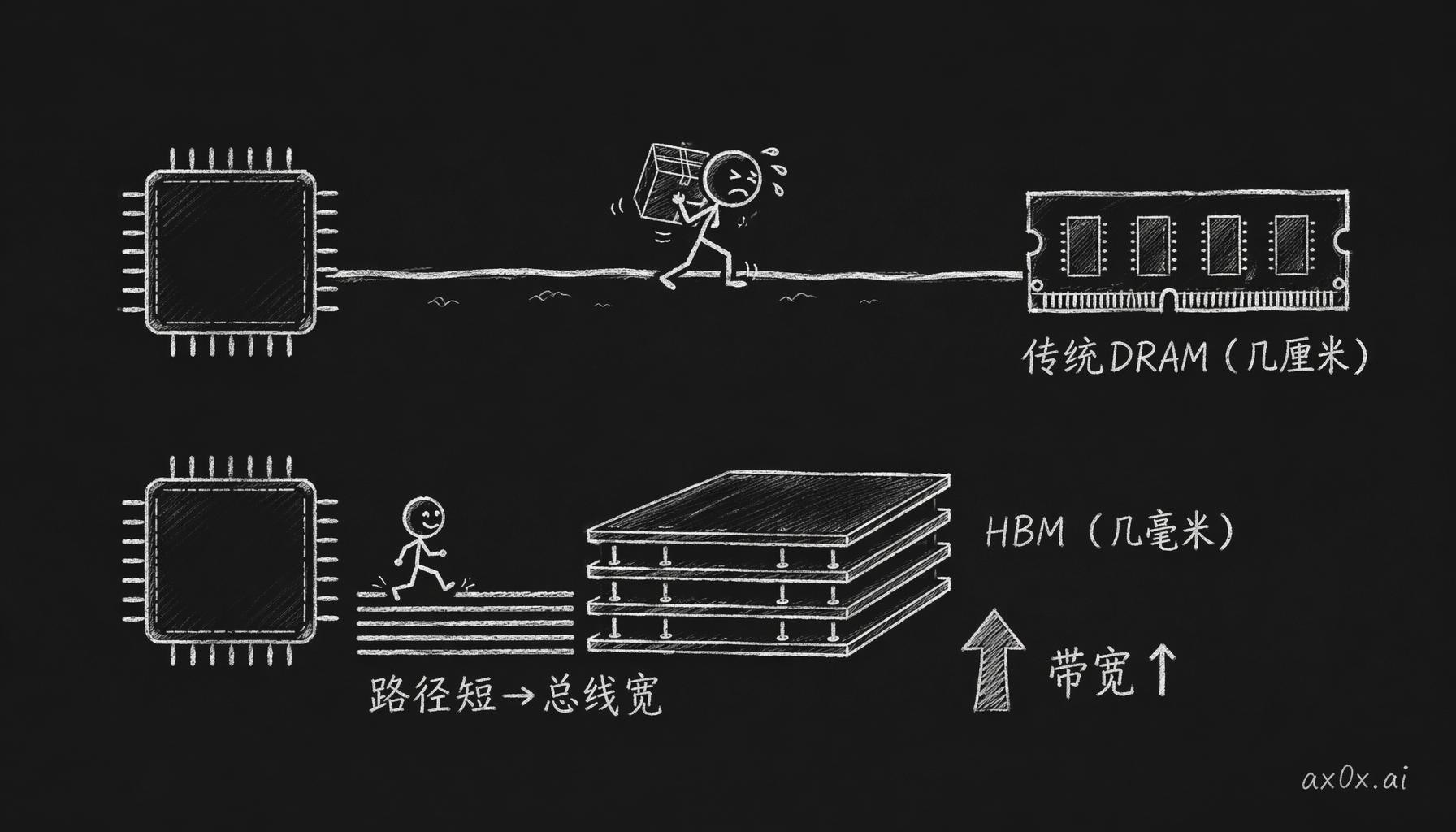 HBM 把内存从几厘米外搬到芯片旁的几毫米处,路径短了总线就能做得更宽,带宽随之提上去。
HBM 把内存从几厘米外搬到芯片旁的几毫米处,路径短了总线就能做得更宽,带宽随之提上去。
代价是 HBM 贵得离谱。一张 H100 的成本里,HBM 占了超过 50%。所以真不是 Nvidia 贵,是 HBM 贵。
只能说,存储墙是过去二十年最被低估的技术瓶颈。你关心的功耗也好、成本也好、延迟也好,追到最后基本都会追到内存这上面。那 HBM 到底是怎么造的?良率为什么那么低?为什么全世界能稳定量产的只有 SK 海力士一家?这背后的产业链又在怎么博弈?后面的文章一个一个展开。


