HBM 这波涨价其实是推理带起来的
HBM 这个市场最近涨得挺吓人的。我去翻了下数,2024 年整个市场一年也就 50 亿美元左右,大家对 2027 年的预测已经给到 400 亿往上了,等于三年翻了八倍。一个半导体细分市场能有这种涨法,挺少见的。
八倍是从哪来的啊?大家都知道 AI 缺芯片,但具体缺的是什么,好像没多少人说得清吧?背后其实是一个正在发生的转换:AI 的重心在从训练挪向推理。训练是把模型造出来的那一步,要花几亿、几十亿美元,听着很吓人,但就发生那么一次。模型造出来之后呢,剩下的全是推理,全世界每一次调用都是推理,你每问它一句话,它都在做推理。Deloitte 预测 2026 年推理会占掉总算力的三分之二,推理芯片市场从两百亿美元跳到五百亿以上。
而推理要的不只是 GPU 算力,它要内存。模型越大,推理吃的内存越多。为什么会这样?得看推理这个活具体是怎么干的。
推理为什么这么吃内存
训练和推理,干的其实不是一种活。训练 GPT-4 级别的模型,要访问整个模型的参数、激活值、梯度、优化器状态,一个训练 batch 同时处理几千个 token,GPU 那一大堆并行核心能喂得很满。
推理不是这样。每个用户请求独立处理,一次生成一个 token,自回归地一个一个往外蹦。这时候 GPU 的并行计算核心大量闲置,但模型参数呢,每生成一个 token 都得完整读一遍。算力多得用不完,卡住的是把参数搬进来的速度——这种计算能力富余、带宽成了唯一瓶颈的状态,有个名字,叫 memory-bound。小 batch 推理就是典型的 memory-bound 任务。
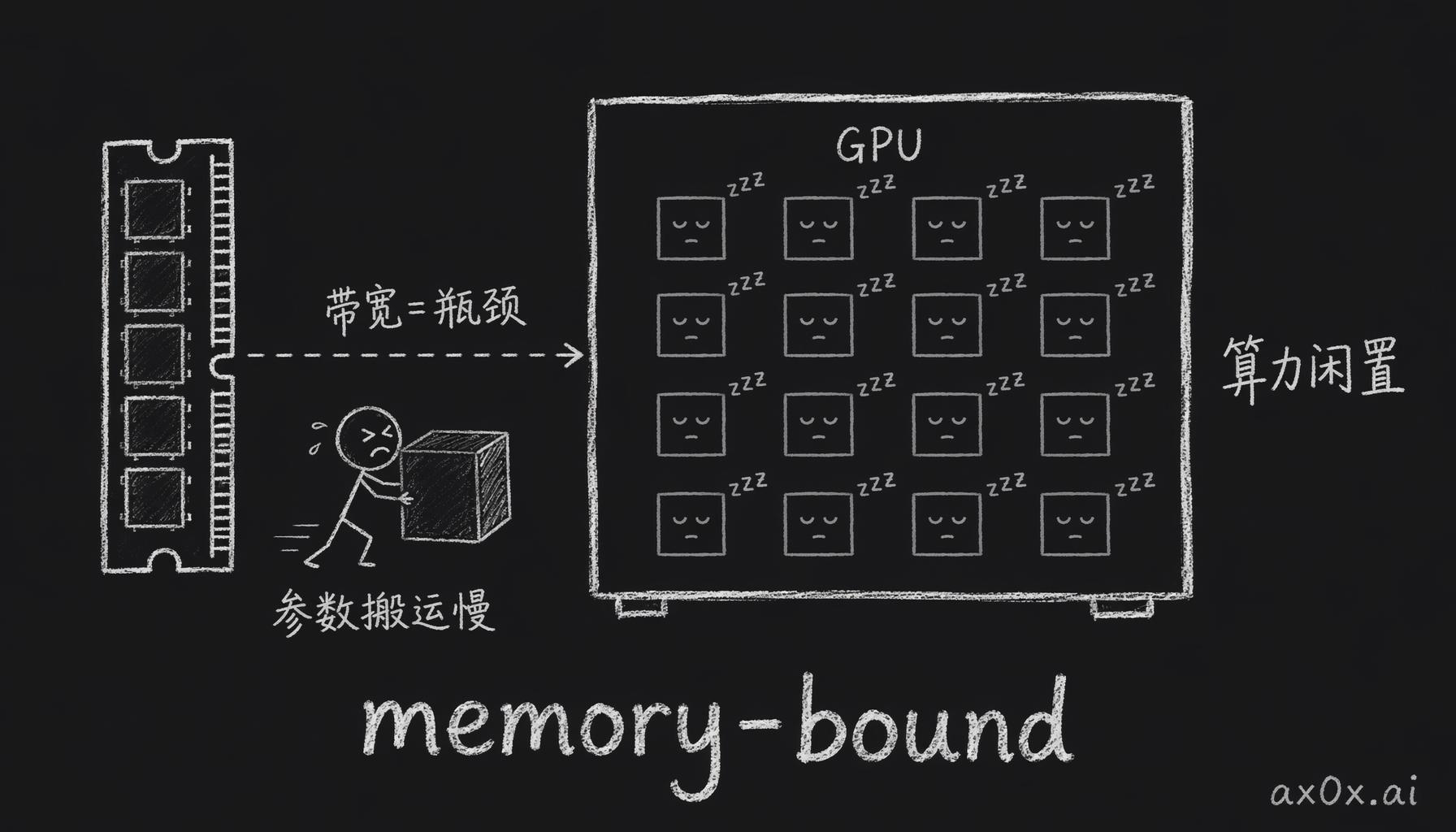 推理时 GPU 的算力大量闲置,真正卡脖子的是把模型参数从内存搬进来的带宽——这就是 memory-bound
推理时 GPU 的算力大量闲置,真正卡脖子的是把模型参数从内存搬进来的带宽——这就是 memory-bound
模型越大,这个矛盾越突出。GPT-5 级别的模型有数万亿参数,哪怕只推理一个 token,光把参数完整读一遍就要占掉几十 GB 的内存带宽。所以看推理卡不能光盯着 TFLOPS,关键指标是 HBM 带宽。需求端是这么个情况,那供给呢?产能跟不跟得上啊?
产能为什么扩不动
现在全球 HBM 月产能大概 15 到 20 万片(12 英寸等效)。SK 海力士占约 55%,三星约 35%,美光约 10%。需求远超供应,2025 年的 HBM 产能已经全部被预定完了。
那为什么不赶紧扩产啊?瓶颈其实不在 DRAM 颗粒本身,全球的 DRAM 产能反而是供过于求的。卡的是封装。HBM 是把好多层 DRAM 叠在一起,层和层之间要打几千个垂直的孔把上下连通起来,这个工艺叫 TSV,对良率和精度的要求极高。TSV 产能扩一轮要 12 到 18 个月,比 GPU 芯片本身的扩产节奏慢得多。
 HBM 扩不动不是因为缺 DRAM 颗粒,而是卡在 TSV 封装这道工序,扩一轮要 12 到 18 个月,慢到 GPU 都比 HBM 先到货
HBM 扩不动不是因为缺 DRAM 颗粒,而是卡在 TSV 封装这道工序,扩一轮要 12 到 18 个月,慢到 GPU 都比 HBM 先到货
所以就出现了一个挺离谱的局面:GPU 交货比 HBM 还快。B200 芯片在台积电 4nm 的产能是充足的,但给 B200 配的 HBM3e 不够。GPU 有算力,内存配不上,就只能等着。
中国存储产业在什么位置
美国对华芯片制裁,主要卡的是先进逻辑芯片(7nm 以下)和计算 GPU,存储芯片这块的管制相对宽松——三星和 SK 海力士在国内的 NAND 和 DRAM 工厂,现在还是获准进口设备的。
国内厂商的进展,只能说超出预期。长鑫存储(CXMT)在 DRAM 上 DDR5 已经量产,LPDDR5 开始给手机厂商供货。长存(YMTC)的 NAND 做到 232 层,追平了国际主流。
但 HBM 上的差距还是巨大的。HBM 要 TSV 封装、要硅中介层、要多层堆叠,这些技术在国内的成熟度远低于标准 DRAM,目前还没能量产 HBM2e 及以上级别的产品。这大概也是美国制裁下一步最可能收紧的领域。
最后说说我怎么看这个周期。存储超周期的底层驱动是 AI 从训练向推理的永久性迁移,不是一次短期的芯片短缺。推理需求是跟着 AI 应用的渗透率走的,渗透率涨它就涨,甚至涨得更快。产能那边不是这个节奏,前面说了,TSV 扩一轮就是 12 到 18 个月,只能一个台阶一个台阶上。所以这个缺口中长期会一直在。要说谁受益,我自己会盯 HBM 产业链上的那几环,设备、封装、材料。做算力基建的朋友应该早就有体感了,内存成本在 TCO 模型里已经是占比最大的单一项。


