DRAM 是怎么存下一个比特的
内存这个东西大家天天在用,但它到底是怎么把一个比特存下来的,好像很少有人说得清楚吧?其实你可以把内存想象成一个巨大的 Excel 表格,每一格存一个比特,0 或者 1。DRAM 的每一格里就俩零件:一个晶体管,一个电容。晶体管当开关用,电容用来装电荷。就这么朴素的一个结构。
存一个比特,靠的就是电容里那点电荷
写和读都特别直白。要写 1,把晶体管打开,给电容充电;要写 0,也是打开晶体管,让电容把电放掉。读的时候还是打开晶体管,看电容上有没有电荷,有就是 1,没有就是 0。
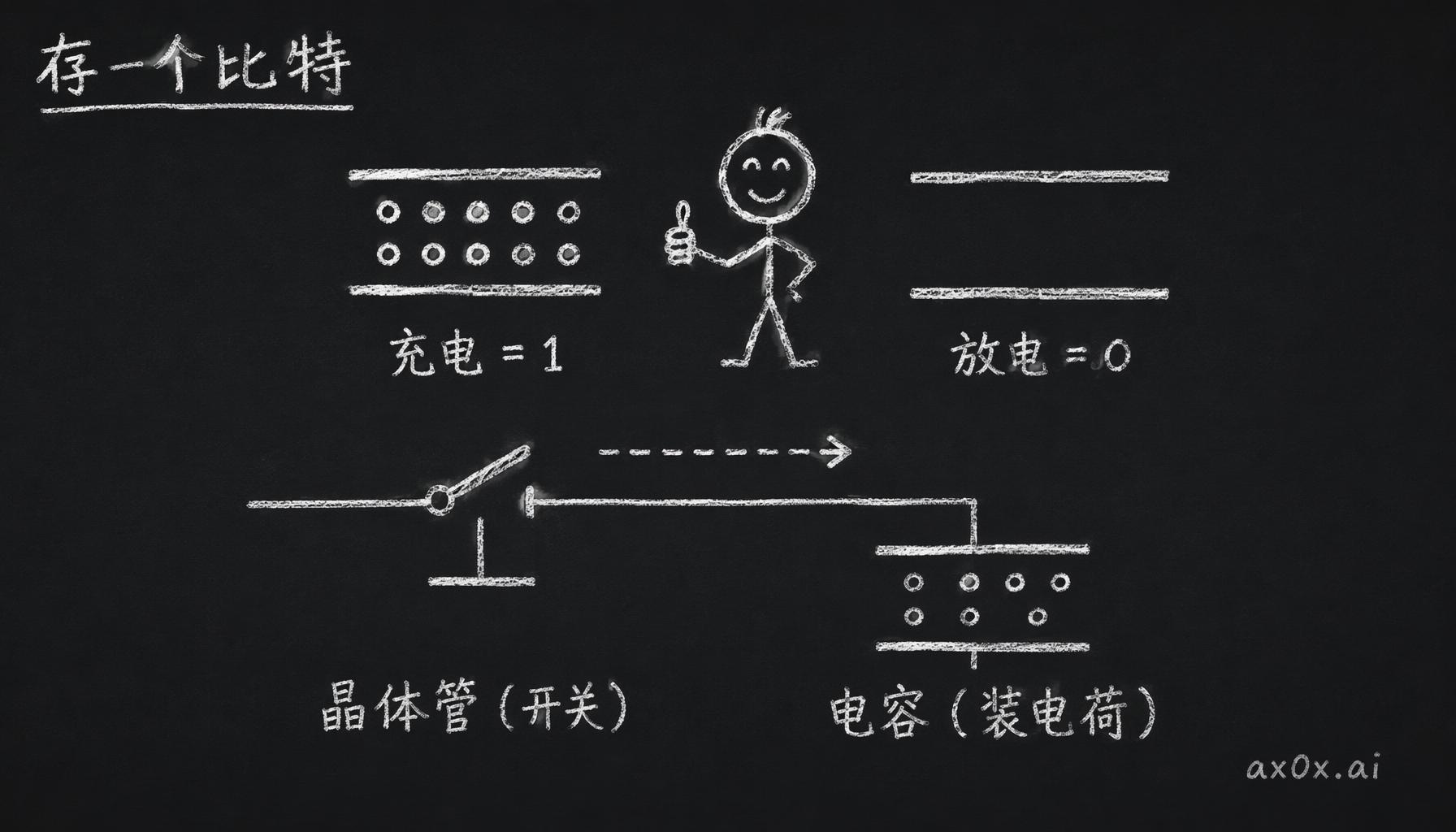 DRAM 的一个存储单元:晶体管当开关,电容装电荷,充电是 1、放电是 0
DRAM 的一个存储单元:晶体管当开关,电容装电荷,充电是 1、放电是 0
但麻烦来了:电容会漏电。DRAM 的电容做得极小,现代制程下大概就几十飞法。几十飞法是什么概念呢?里面那点电荷,毫秒级就漏光了。你不管它,数据自己就没了。
所以 DRAM 只能定期刷新——每隔几十毫秒,把所有电容读一遍、再重新写回去,相当于它得不停地给自己抄一遍笔记,不抄就忘。刷新期间它是干不了正常活的。你想啊,每隔几十毫秒就要停下来抄一遍笔记,这延迟还怎么降得下去啊?
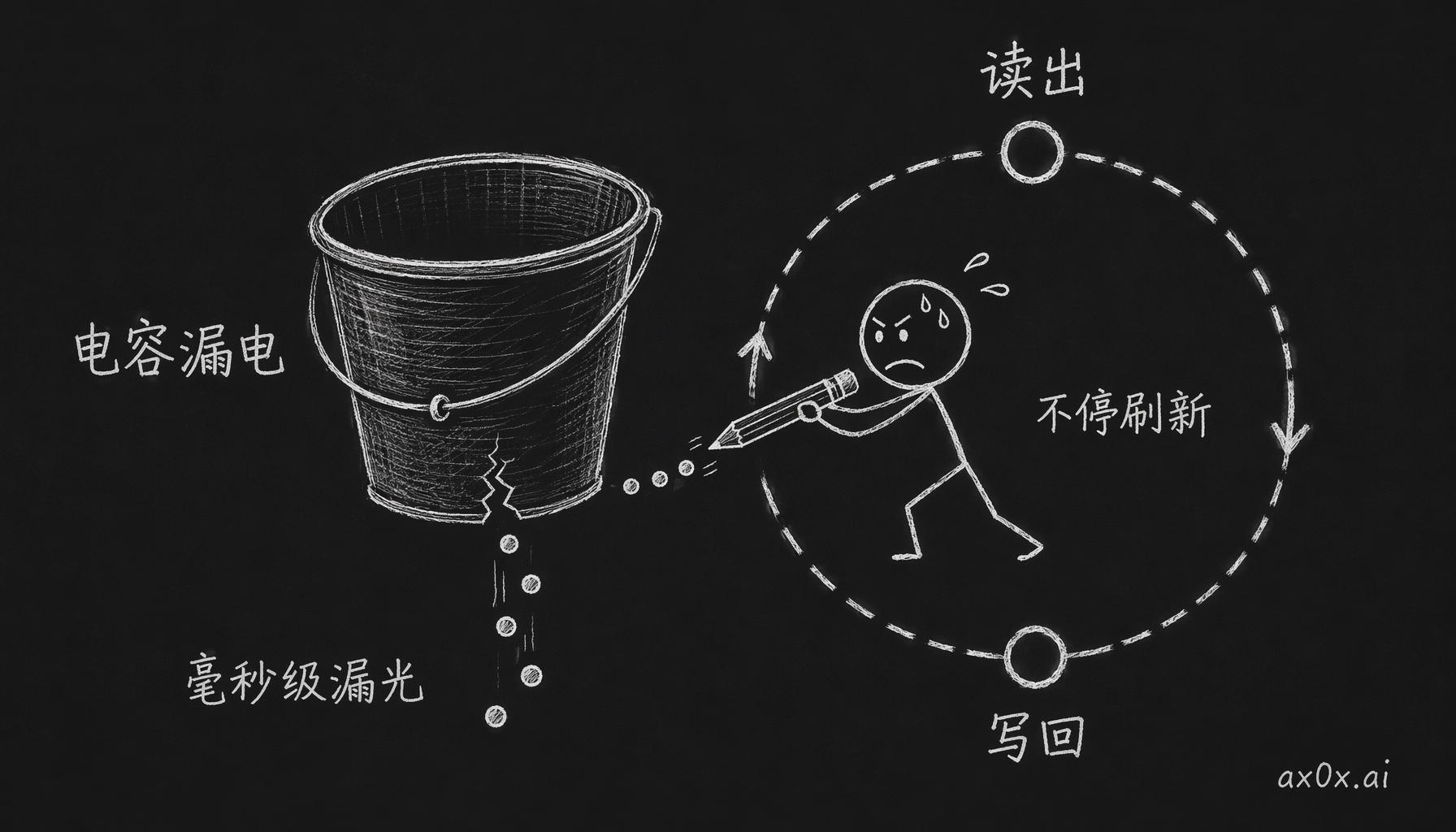 DRAM 电容像漏水的桶,电荷毫秒级漏光,只能不停地读出再写回——这就是刷新
DRAM 电容像漏水的桶,电荷毫秒级漏光,只能不停地读出再写回——这就是刷新
更难受的是,这个问题只会越来越糟。制程每缩一次,电容就更小,漏电相对就更快,刷新就得更频繁。存这个比特的单元本身变成了瓶颈——这也是为什么内存频率的提升,远远慢于处理器频率。
为什么顺序访问比随机访问快几十倍
DRAM 内部,电容是排成阵列的,有行有列。你要访问某一格,得先选行,把一整行电容的电荷全部读出来,放进一块临时的 SRAM 缓冲里——这个东西叫行缓冲器,然后再从行缓冲器里选列。
这里面藏着一个关键的效率来源:如果你连续访问的是同一行里的不同列,行只需要打开第一次,后面直接从行缓冲器里读,延迟低得多。顺序访问比随机访问快几十倍,根子就在这。软件里天天讲的「内存局部性」,其实说的就是这个事情。
其实很多内存优化说到底都在利用这个特性。比如 CPU 缓存,它能起作用就是因为程序通常连着访问相邻的内存地址。矩阵乘法也是,访问模式是可预测的顺序扫描,所以才能被优化得那么狠。
内存到底比处理器慢多少
来点具体数字。打开一行,大概 15 到 20 纳秒;从行缓冲器读一列,5 到 10 纳秒;再加上总线传输和控制器的开销,一次「随机」内存访问下来,大概 40 到 100 纳秒。
40 纳秒听着挺快吧?人是完全感受不到的。但处理器的时钟周期是 0.2 纳秒(按 5 GHz 算)。等一次内存的工夫,处理器本来能执行 200 条指令。处理器大部分时间其实在空转,在干等内存。这个现象有个名字,叫存储墙。
GPU 的解法是拿海量线程把这 200 个周期的空白盖住:一个 warp 在等内存,调度器就切到另一个 warp 去算。只要活跃线程足够多,内存延迟就被完全藏起来了。但 batch size 小到 1 的时候(比如实时推理),能切换的线程不够用,存储墙立马又冒出来了。
内存为什么进步这么慢
那为什么内存这么多年进步这么慢啊?一个容易被忽略的原因是,DRAM 工艺和逻辑芯片工艺走的是两条完全不同的路。逻辑芯片(CPU/GPU)追求的是开关速度和功耗,DRAM 追求的是电容密度和漏电控制。同样叫 5nm,两边的工艺参数完全是两回事。所以 DRAM 厂没法借台积电的逻辑工艺线来用,得自己养一套完全独立的研发和产线。
而全世界玩得起这个游戏的就三家:三星、SK 海力士、美光,加起来占了 95% 的市场,各有各的闭源工艺和设计。进入壁垒高到挺离谱的:百亿美元级的资本开支,十年以上的技术积累。这么一看,DRAM 的创新这么多年一直远远落在处理器后面,也就不奇怪了。
为什么运行内存用 DRAM,存储用 NAND
最后说一下 DRAM 和 NAND 的区别。DRAM 存数据靠电容,只要通电(外加不停地刷新),数据就一直活着,一断电就全没了。NAND 不一样,它是把电子「困」在一层绝缘层里,断电了电子也跑不出来,数据不丢。代价是什么呢?NAND 的读写速度比 DRAM 慢三个数量级。
所以计算机的分工就这么定下来了:DRAM 快,就拿去当运行内存,断电丢数据这个毛病只能认了。NAND 呢,慢是慢了点,但断电之后数据还在,存东西这个活自然就归它。
对了,这五十年也不是没人想换掉 DRAM——磁阻内存、相变内存、铁电内存,全都试过,每一个都卡在成本或者良率上过不去。所以短期看,运行内存大概率还是 DRAM 这套东西。


