存储墙修不动了怎么办
前五篇把存储墙这个事情基本讲完了:处理器和内存之间,带宽、延迟、功耗三个问题;DRAM、NAND、HBM 各自怎么干活、物理极限卡在哪,也都过了一遍。那接下来很自然就有一个问题:墙修不动了,怎么办啊?HBM 已经算是把「往死里堆带宽」这条路走到头的做法了,再往后还能怎么走?这篇聊的就是这个——不修墙了,看看有哪几条路能绕过去。
把计算搬到数据旁边,行不行
先想一个很朴素的问题:凭什么一定是数据搬到计算单元那边去算啊?反过来,把计算搬到数据旁边,行不行?
传统架构里,一次计算的流程是这样的:数据从 DRAM 搬几千个比特到处理器,处理器算一个乘加,结果再搬回 DRAM。这一来一回有多亏呢?每搬一个 bit 花掉的能量,大概是算它本身的 1000 倍。等于说电大部分都花在跑腿上了,真正用来算数的没多少。1000 倍,这个比例真的挺离谱的。
那就别搬了嘛。在内存阵列内部直接嵌一些简单的计算单元,数据在哪就在哪算,乘法加法就地做掉,不用来回搬。这种把计算做进内存里的思路有个名字,叫存算一体,英文是 Processing-in-Memory。理论上能效可以改善几十倍到上百倍。
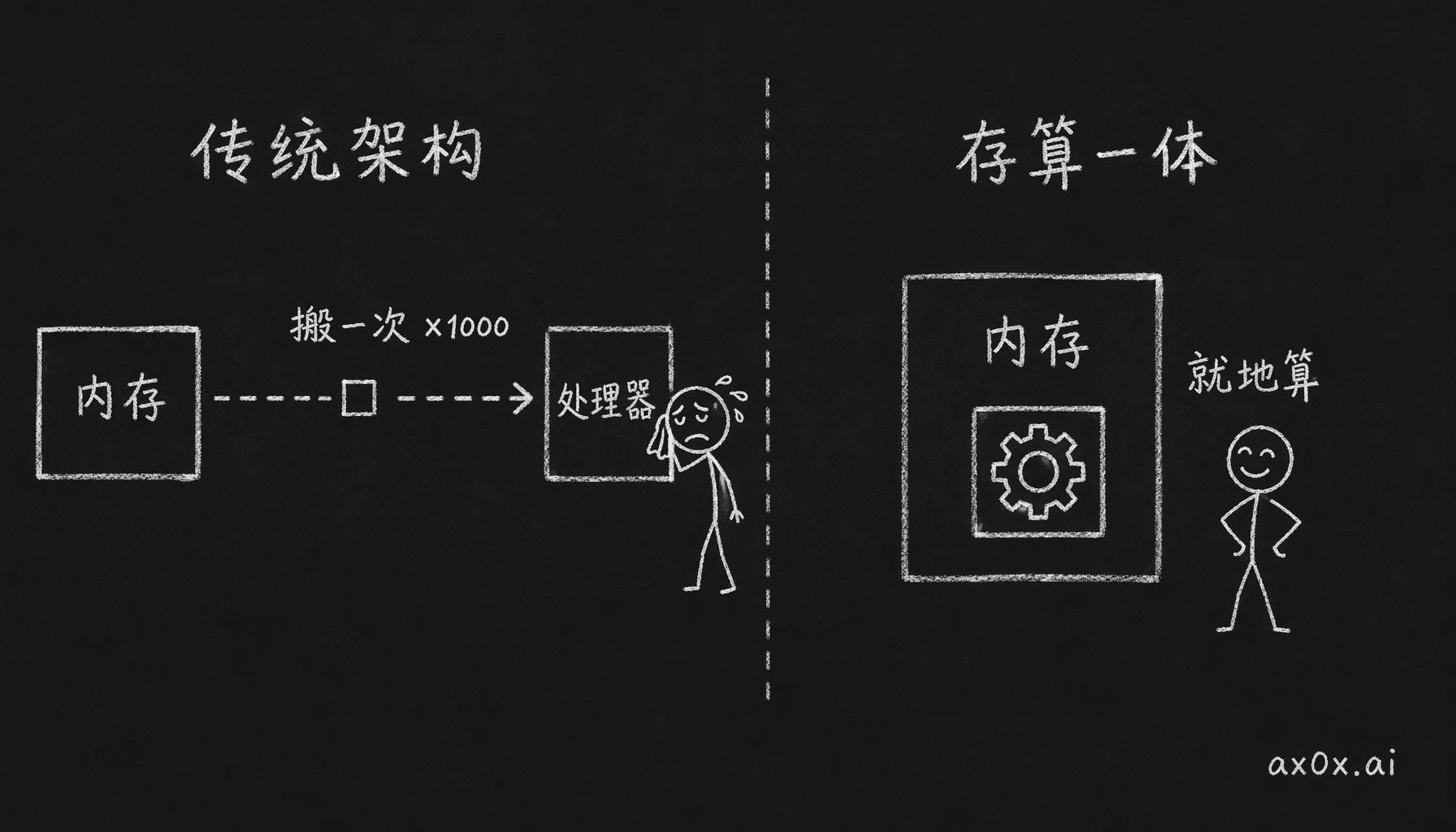 存算一体:不把数据搬到处理器,而是把计算单元嵌进内存里就地算,省掉那份比计算本身贵 1000 倍的搬运能量。
存算一体:不把数据搬到处理器,而是把计算单元嵌进内存里就地算,省掉那份比计算本身贵 1000 倍的搬运能量。
三星已经做出实际的东西了:HBM-PIM,在 HBM 堆叠内部塞了可编程的计算单元,每一层 DRAM 旁边放一个 FP16 乘加器,模型推理里的矩阵向量乘法就可以有一部分直接在内存内部做完。实测能效提升大概 2.5 倍。说好的几十上百倍呢?只能说 2.5 倍确实算不上质的飞跃,但方向是对的。
那卡在哪呢?卡在工艺上。DRAM 的工艺精度比逻辑工艺差得远,你非要在 DRAM 片上做计算单元,精度和速度都得打折。所以存算一体天生适合的是数据量大、计算又简单的活——也就是推理。训练它干不了,别指望它替代 GPU,它要替代的是推理卡。
计算搬过去了,还剩一个事没解决:芯片和芯片之间,数据总还是得传的吧?
芯片之间改走光
芯片之间传数据,现在走的是电,铜线。电信号有个天然的毛病:线越长衰减越厉害,带宽一上去,线和线之间还会互相干扰——这个干扰有个专门的词,叫串扰。光就没这些毛病。光信号在波导里走,几乎不衰减,也不互相干扰,带宽基本就贴着物理极限走。
所以用光代替电来做芯片之间的数据传输,是解决带宽和功耗最根本的一条路。英特尔和 Ayar Labs 在做的硅光子收发器就是这个思路:把光收发模块直接集成到芯片封装上,芯片之间用光纤通信。功耗能降 5 到 10 倍,带宽能提 10 倍以上。
那难在哪呢?难在硅自己不会发光。你要光源,就得把 III-V 族材料和硅做异质集成,这一步本身就不容易。再加上光电转换有效率损失,光波导在芯片上的制造成本和良率也都是坎。
所以比较可能的样子是分工:计算用电子,数据传输用光子,各干各擅长的。
刚才顺嘴说了个词,异质集成。这个东西得单独讲讲。
不同工艺的芯片,拼到同一块基板上
「异质集成」这四个字听着挺书面的,干的事情说白了就是拼装:不同工艺、不同功能的芯片,封装到同一块基板上。逻辑芯片用 3nm,I/O 芯片用成熟制程就够了,DRAM 芯片用 DRAM 自己的工艺,模拟芯片用旧制程。每一块都用对它最合适的工艺去造,然后靠硅中介层或者高级封装连起来。
苹果的 M 系列芯片就是这个思路的先行者:CPU 和 GPU 放在同一个 SoC 上,统一内存架构,CPU 和 GPU 之间的数据搬运直接就消掉了。英特尔的 EMIB、台积电的 CoWoS-L,干的其实是同一件事——让异质集成更便宜、面积更大、能塞进更多芯片。
DRAM 和 NAND 之间的空白地带
再看存储介质本身。DRAM 快,但贵,断电还丢数据。NAND 便宜、断电不丢,但慢。这两个之间隔着一大片性能和成本的空白,有没有东西能填进去啊?
想填这个空白的候选其实不少:MRAM,用磁性隧道结存数据;ReRAM,电阻式内存,用电阻值存数据;还有 FeRAM,铁电内存。它们的共同点是比 NAND 快、比 DRAM 慢、断电不丢。这个位置听起来很理想——一块持久化的大容量工作内存。AI 推理的模型权重可以直接放在这里面,从 SSD 加载到 DRAM 的那段延迟直接省掉。
但现实是,到今天没有任何一种新介质能在成本、可靠性、密度这三样上同时过量产这一关。这个行业 30 年前就在找所谓的 universal memory——比 DRAM 快、比 NAND 便宜、断电不丢、随便写也写不坏的那种。找了 30 年,还没找到。
往远看,方向就三条
把上面这些放到一起看,演化的方向其实挺清楚的,就三条。
第一个是计算离数据越来越近。存算一体是一步,3D 堆叠是同一个方向上的另一步——逻辑和存储直接叠在一起,垂直互连就剩微米级那么一点长度,数据基本不用跑路了。
第二个,通用芯片的位置在被专用芯片一点点挤掉。大模型推理根本用不上 x86 那一整套指令集,矩阵乘加这一类操作就占了 GPU 95% 的执行量,那剩下那一大堆功能养着干嘛呢?做得越专用,功耗就省得越狠。
第三个方向说起来有点反过来:硬件开始跟着软件走了。以前都是软件迁就硬件,现在是反的。CUDA 生态的好处是什么矩阵计算都能跑,但你要是把特定算子直接固化到 ASIC 里,效能是数量级的提升,芯片设计的迭代周期也从几年缩到了几个月。
这个系列写到这就算完了。要说一个总的判断的话,内存这个部件,二十年前装机的时候谁在乎啊,插上能用、容量够就行,整台机器里最无聊的一块;现在它就是整个 AI 产业最核心的战场,这个话我觉得不算夸张。往后看,事情其实还卡在两个问题上:存算一体、光互连、新介质这几条路,哪条先过量产这一关?过了之后,现在围着 HBM 转的这套格局,会不会被重新洗一遍?我只能说都盯着看吧。


