HBM 凭什么这么贵
大家都知道 AI 的 GPU 贵吧?一张 B200,物料成本大概 $25,000 到 $30,000。但这个钱到底花在哪了,好像很多人就不太清楚。拆开来算,光 HBM 就 $15,000 以上,Nvidia 旗舰 GPU 的物料成本里,HBM 要占到 50% 到 60%。所以真不好说是 GPU 贵,你一半多的钱其实是花在内存上的。
那 HBM 到底是个啥?一块内存而已,凭什么能卖这么贵啊?
带宽是叠出来的
第一篇讲过存储墙的事:处理器越来越快,内存带宽跟不上,算力大把时间在干等数据。HBM 就是冲着带宽去的。但它的带宽不是靠把单个芯片压榨得更狠,做法听起来还挺朴素:把好几片 DRAM 芯片像千层饼一样叠在一起,垂直打孔穿线,让每一层的数据总线并联起来。叠 N 层,带宽就是单片的 N 倍。至于 DRAM 单片自己是怎么存数据的,第二篇讲过了。
光叠起来还不够,还得放得近。传统内存是插在几厘米以外的 PCB 板上的,HBM 不一样,它直接放在 GPU 旁边,跟 GPU 装在同一块硅上,物理距离缩到几毫米。距离一近,互连总线就可以开得特别宽。传统 GDDR 内存是 32 位总线,HBM 直接开到 1024 位,位宽差了 32 倍。层数叠上去,位宽再拉宽,带宽自然就上来了。
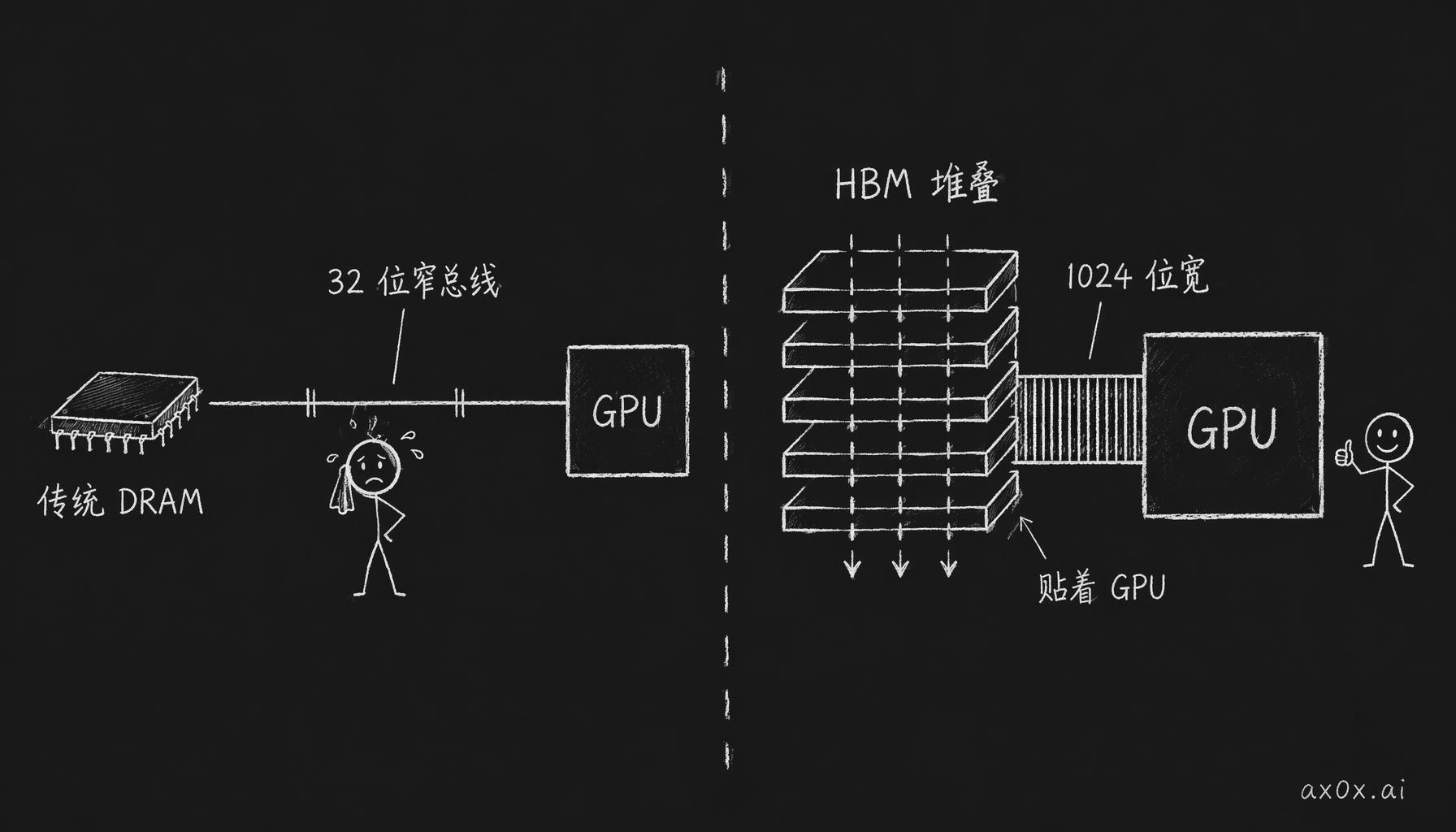 HBM 的带宽从哪来:把 DRAM 竖着叠、垂直打孔、总线拉到 1024 位宽再贴到 GPU 旁边——宽而近打败窄而远
HBM 的带宽从哪来:把 DRAM 竖着叠、垂直打孔、总线拉到 1024 位宽再贴到 GPU 旁边——宽而近打败窄而远
但叠芯片这个事,听着朴素,做起来贵得离谱。贵在哪?
打穿八层芯片的几千个孔
先说穿层连线怎么做。每层 DRAM 芯片先打磨到几十微米薄,激光打孔,孔里填满铜,然后再往上堆下一层。每一个孔,就是垂直方向的一条导线。这个东西有个名字,叫 TSV(Through-Silicon Via),穿过硅片的垂直连线。8 层堆叠,就是 8 层芯片靠几千个 TSV 并联着通信。
麻烦在良率。要穿过 8 层芯片,每个 TSV 都得对齐到微米级别,几千个 TSV,坏一个,整颗芯片就报废了。所以 HBM 的良率远低于普通 DRAM。它凭什么贵,最根上的原因就是这个,良率上不去,成本自然就下不来。
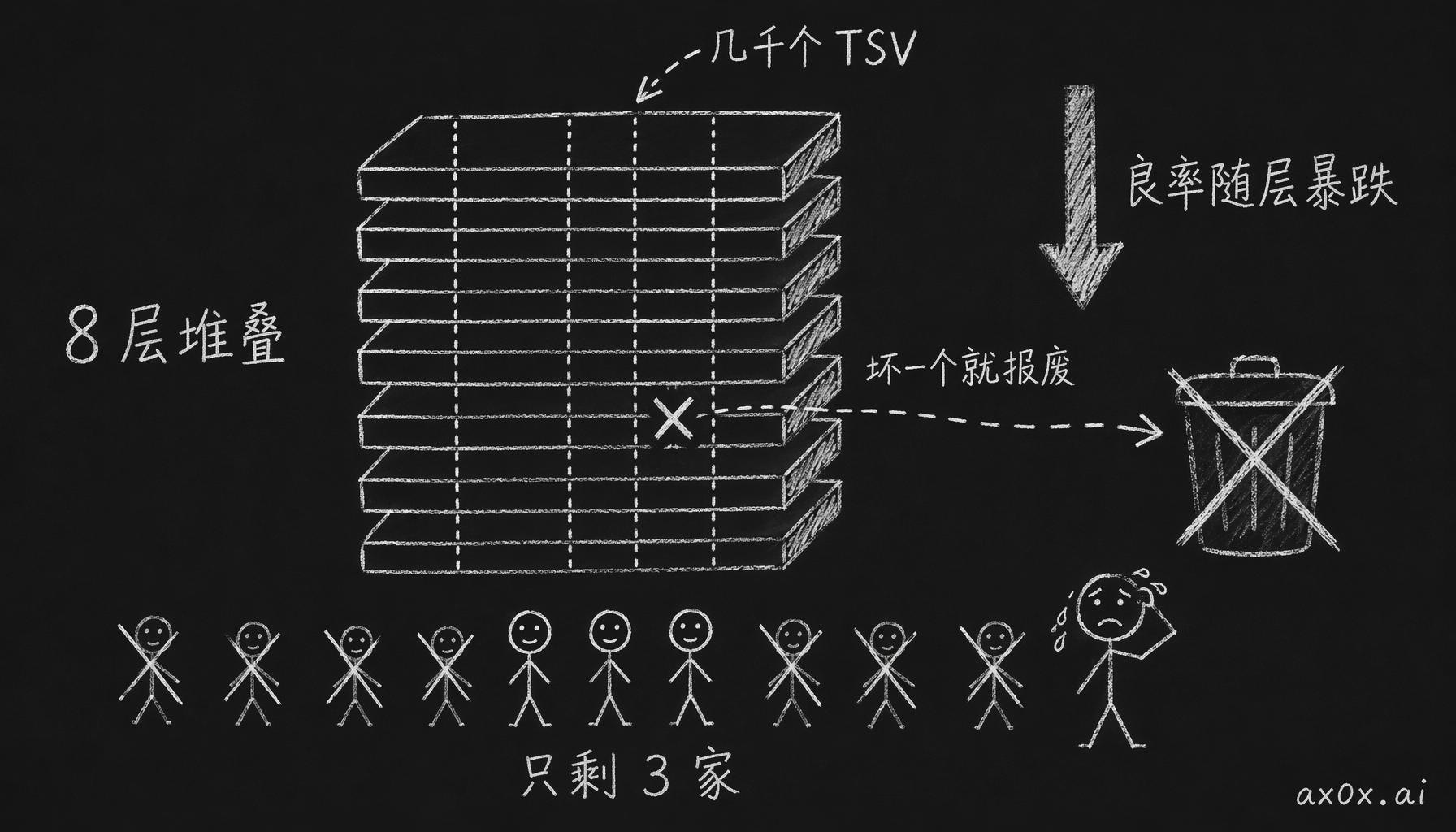 HBM 的护城河是良率:一摞芯片打几千个孔、叠八到十六层,任何一层或一个孔坏掉整摞就报废,层数越多失败概率越叠加——所以能量产的只有三家
HBM 的护城河是良率:一摞芯片打几千个孔、叠八到十六层,任何一层或一个孔坏掉整摞就报废,层数越多失败概率越叠加——所以能量产的只有三家
不过孔打好了、层也叠上了,还差一步:1024 位宽的总线,往哪儿铺?
垫在下面的那片硅也不便宜
GPU 芯片和 HBM 堆叠,是一起装在一块硅上的。这块硅内部有微米级的金属互连线,把 GPU 的存储接口和 HBM 的 I/O 接口连起来。它也有个名字,叫硅中介层。
为什么非得垫这块硅?你看传统方案,数据从 GPU 封装里出来,走 PCB 板到内存条,路程好几厘米,信号一路衰减、串扰,引脚数量也有限。换成中介层,数据就在硅内部走,几毫米的事,而且硅的介电性能远比 PCB 材料好,信号质量高得多。1024 位宽的总线,只有在硅中介层上才做得出来,PCB 上想都不用想。
代价也很直接:中介层自己就是一整片硅晶圆,制造成本很高。面积还得盖住 GPU 加好几个 HBM 堆叠,一块 H100 的中介层面积超过 2000 平方毫米。按晶圆成本和良率一算,光这块硅就得上百美元。
一张 B200 上的 HBM 是个什么量级
落到具体产品上:H100 用 HBM3,H200 和 B200 用 HBM3e。HBM3e 单个堆叠带宽 1.2 TB/s,八层堆叠容量 24 到 36 GB。一张 B200 配 8 个这样的堆叠,总带宽 8 TB/s,总容量 192 GB。
8 个堆叠,每个都要打穿几千个孔,底下还垫着一整片硅。再回头看开头那笔账,整卡物料 $25,000 到 $30,000,HBM 占掉 $15,000 以上,就一点都不奇怪了。
为什么赚到钱的只有 SK 海力士
HBM 市场目前几乎是 SK 海力士的天下,HBM3 初期它的份额接近 90%。三星在追,美光也在追,但差距没怎么缩小。
它的先发优势在哪?TSV 工艺积累得最早,2013 年就跟 AMD 合作做出了第一代 HBM。起步早,堆叠良率和量产能力到现在也没人追得上。再就是跟 Nvidia 绑得特别深——Nvidia 一家的 HBM 需求,就占了全球总量的 70% 以上。
还有一个容易被忽略的护城河。HBM 不是造出来就能卖的,得跟 GPU 一起做联合验证和封装。「联合验证」这个词听着挺书面,其实就是把内存和 GPU 装在一起反复磨合,证明这俩配起来能稳定干活。海力士跟 Nvidia 已经走完了好几代产品的磨合,后来者就算做出同等质量的 HBM,也得从头把验证再走一遍,一走就是一到两年。等你走完,市场已经被下一代 HBM 占满了。
它也有堆不动的一天
堆叠层数不能无限往上加。TSV 良率随层数指数下降,散热也是个大问题——DRAM 就挨着 GPU 放,两边互相加热。HBM4 计划堆到 16 层,但业界对能不能做出来一直有争议。
更麻烦的是产能。全球的 HBM 产能,2024 年的全部被预定完了,2025 年的大部分也已经有主了。新进场的玩家,比如特斯拉、微软的自研芯片,根本排不上 HBM 的供货——这也是他们转向 GDDR 或者自研架构的重要原因之一。
HBM 很贵,以后只会更贵,可算力需求还在指数往上涨。这个矛盾怎么收场我也说不好,感觉接下来几年整个行业都得围着它想办法。至于 HBM 的需求为什么涨得这么猛,下一篇接着讲。


