TPU 凭什么挑战英伟达
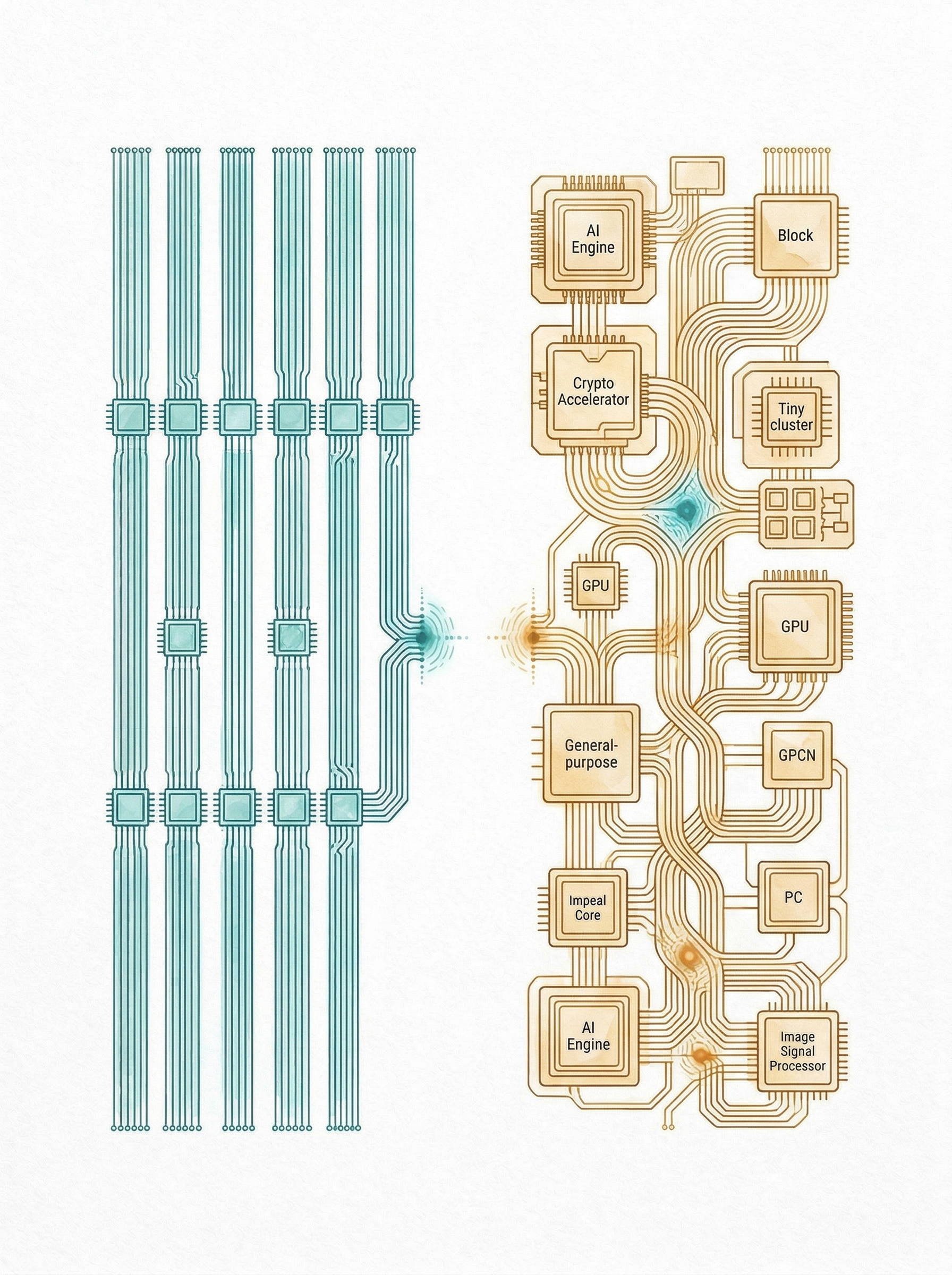 GPU 是一千个大厨,TPU 是一条流水线——两种计算哲学
GPU 是一千个大厨,TPU 是一条流水线——两种计算哲学
前几天听了一期硅谷101播客,嘉宾是前谷歌 TPU 工程师 Henry,在谷歌干了六年,深度参与过 V7(Ironwood)和 V8 的研发。
对硬件一直有兴趣,不算深入。听完两小时,脑子里很多模糊的东西突然清晰了。
不是"TPU 更好还是 GPU 更好"那种二选一。两套完全不同的哲学。
Henry 打了一个很好懂的比方。
GPU 架构叫 SIMT——Single Instruction Multiple Threading。想象厨房里塞了一千个大厨,每人独立思考,自己从冰箱拿食材,自己做菜,自己上菜。并行力极强。
TPU 不一样。一条流水线。第一个人从冰箱取菜,做完递给第二个人,第二个人加工完递给第三个人。每人只干一件事,中间没有等待,没有调度开销。
GPU 每个大厨经常等着食材从冰箱搬过来,闲着呢。TPU 流水线不会闲——软件已经把每一步的数据搬运提前安排好了。
GPU 硬件很聪明——TPU 的聪明在软件上。
这句话就是理解 TPU 最核心的切入点。
TPU 本质是 ASIC——专用集成电路。为矩阵计算而生,为 Transformer 优化。
巨大优势:workload 确定,定制芯片能拉到近满载。Henry 说 TPU 软件(XLA 编译器)在全局层面做算子融合、内存管理、数据搬运规划,相当于上帝视角安排每个计算单元每秒钟干什么。
代价也明确:得赌对方向。
V4、V5 时代,TPU 主力 workload 还是谷歌内部的推荐系统和排序算法——稀疏矩阵计算。ChatGPT 出来之后,大模型对稠密矩阵计算的需求暴涨,TPU 纸面参数一度被 GPU 拉开。直到 V6、V7,重心彻底转向大模型训练,参数才追上来。
Henry 说谷歌能赌对 Transformer,因为 Transformer 本就是谷歌发明的,比行业外的人更早知道架构 workload 长什么样。先发优势,来自 insider knowledge。
他坦言担忧:万一下一代范式不是 Transformer 呢?GPU 通用性强,能快速适应新算法。TPU 一旦方向错,两到三年的芯片设计周期,根本追不上。
MOE 是个很能说明问题的例子。
早期 TPU 用 2D Torus 网络拓扑——每张芯片只能跟相邻的芯片通信。MOE 需要把不同的 token 路由到不同的专家,专家分布在不同芯片上。2D Torus 下,想找不相邻的专家,中间要经过很多跳,拥堵严重。MOE 在早期 TPU 上跑不起来。
V4 的时候,TPU 团队搞了 3D Torus + OCS(光纤交换机),软件可编程的方式重新配置通信路径。MOE 的效率一下就上来了。
芯片设计周期两到三年,算法迭代周期六个月。中间的时间差,就是 ASIC 最大的风险。
听完最大感受:TPU 的竞争力不在单芯片性能,在系统。
英伟达是一张一张卡地卖。买了卡,还得买 NVLink、NV-Switch 交换机组网。infrastructure 成本巨高。
TPU 从一开始就按集群设计——TPU Pod。芯片间用铜线直连,只在关键节点用光纤交换机。用户感觉是"一张卡的性能",背后是几千张芯片在协同。
两个直接好处:通信成本低,不用买贵交换机。训练效率高,整个系统级优化,不是单卡优化。
Henry 的说法:同样训练 Gemini 级别的模型,TPU 的总拥有成本(TCO)比 GPU 更低。前提是软件栈能充分利用 TPU 的特性。
CUDA 生态有多强大不用多说。全世界 AI 研究者、工程师,默认 PyTorch + CUDA。成千上万的算子、库、工具链,全围绕 CUDA 建的。
TPU 呢?得用 JAX + XLA。
XLA 是静态编译器。好处是能做全局优化——知道整个计算图长什么样,在系统层面做最优调度。坏处是黑盒。出了 bug,难 debug。
Henry 说得直白:外部开发者很难独立修 XLA 的 bug,得找谷歌工程师。跟 CUDA 开放的生态形成鲜明对比。
Anthropic 能用好 TPU,一个关键原因是很多工程师本就是谷歌出来的,对 JAX + XLA 很熟。苹果能用好 TPU,是庞若鸣(Apple Intelligence 负责人之一)直接从谷歌把整套软件栈带过去了。
不是谁都能用好 TPU。得有对的人。
直接在谷歌云上用 TPU 呢?Henry 给了一个让人吃惊的数字:可能只能跑到 50%-60% 的利用率。付的是 100% 的钱。
说白了,对大多数公司来说,谷歌云上的 TPU 性价比未必比 GPU 好。只有像 Anthropic 那样直接买 TPU 机架、有工程师能深入调优的公司,才真正吃到 TPU 红利。
Anthropic 拿下 100 万颗 TPU 订单,价值数百亿美元。数字大得吓人。
Henry 的分析很冷静。他指出几个关键因素。
第一,Anthropic 和谷歌有深度绑定关系。谷歌是 Anthropic 的重要投资方。这是内循环,不是纯市场行为。
第二,Anthropic 的工程团队有能力直接在 TPU 上做深度优化。据 Henry 所知,Anthropic 是目前唯一直接从 Broadcom 购买 TPU 机架的外部客户。其他公司——苹果、Midjourney、Meta——都还是通过谷歌云。
第三,Claude API 价格大降(67%),媒体把功劳归给了 TPU 训练带来的推理成本优势。
TPU 外部生态的扩张,目前高度依赖"人脉"——从谷歌出来的工程师带着知识和关系去新公司。这种模式很难规模化。
播客也聊到了 Groq,被英伟达收购。Groq 的创始人 Jonathan Ross 之前就是 TPU 编译器团队的。
Henry 的评价很到位:Groq 本质是家编译器公司,不是芯片公司。硬件比 TPU 还"蠢",编译器能精确到每个时钟周期安排每个计算单元的工作。
Groq 踩准了三个时间节点:推理市场爆发、ASIC 兴起、Agent 元年。Agent 对延迟极度敏感——调用链每一步慢几百毫秒,整体延迟就能拉到无法接受。Groq 的低延迟特性正好适合这个场景。
芯片市场不会大一统。大规模训练和高吞吐推理归 GPU 和 TPU,低延迟推理和本地部署归 Groq 这类玩家,端侧又是另一个战场。
播客里最让人感触的部分,是供应链。
HBM(高带宽内存)只有三家公司垄断:SK Hynix、三星、Micron。英伟达是最大客户,产能提前一到两年锁定。TPU 一直是 secondary customer。
CoWoS(TSMC 先进封装)产能也是瓶颈。谷歌做不了,Broadcom 做不了,只有 TSMC 能做。
还有良率问题。TPU 强调芯片间通信,一致性要求极高。GPU 良率不好能降级——H100 能阉割成低配版。TPU 不行,每张芯片的架构是定制的,不合格就报废。
再好的芯片设计,卡在供应链上就是零。
GPU 的垄断正在被打破,TPU 在其中扮演了关键角色。
TPU 在特定场景——大规模部署、已知 workload、有能力做深度软件优化的团队——确实比 GPU 性价比更高。Gemini 3 用 TPU 训练登顶排行榜,不是偶然。
TPU 扩张有三个硬约束:软件生态——JAX + XLA 学习曲线太陡,debug 太难,没有 CUDA 那样开放的社区;供应链——HBM 和 CoWoS 产能被英伟达锁定了大部分;通用性——算法范式一变,两到三年的芯片设计周期可能跟不上。
对我们做应用层的人,最实际的一句话:未来 AI 基础设施是多元的。GPU、TPU、Groq 这类定制芯片,各有生态位。别 all-in 任何一个平台的假设。
感谢硅谷101 第 228 期,主持人泓君和嘉宾 Henry 的精彩对谈。对 AI 硬件感兴趣的话,这期值得完整听一遍。