DCF 里每个数字,背后都是一个关于公司的故事
「AI 时代怎么投」课程 · 第 5 章 / 共 10 章
2016 年,Damodaran 在纽约大学的课上让两组学生分别给 Uber 估值。同一个 DCF 模型,同一套公开数据,一组估出来 280 亿美元,另一组估出来 620 亿,差了一倍多。而且两组都没算错,数学上都挑不出毛病。
差别出在故事上。第一组觉得 Uber 就是一家出租车公司:城市交通这个市场是有边界的,利润率迟早会被压薄。第二组觉得 Uber 是一个物流平台:市场比出租车大得多,网络效应还能把用户锁住。两个故事都说得通,灌进同一个 DCF 模型,出来的数字就是完全不一样。
大家好像都默认估值难在数学吧?数学那部分 agent 十秒就能搞定。真正难的是每个数字背后,你得选一个关于这家公司未来的故事。两组学生一个估 280 亿一个估 620 亿,差就差在这,一组信的是出租车公司的故事,一组信的是物流平台的故事。
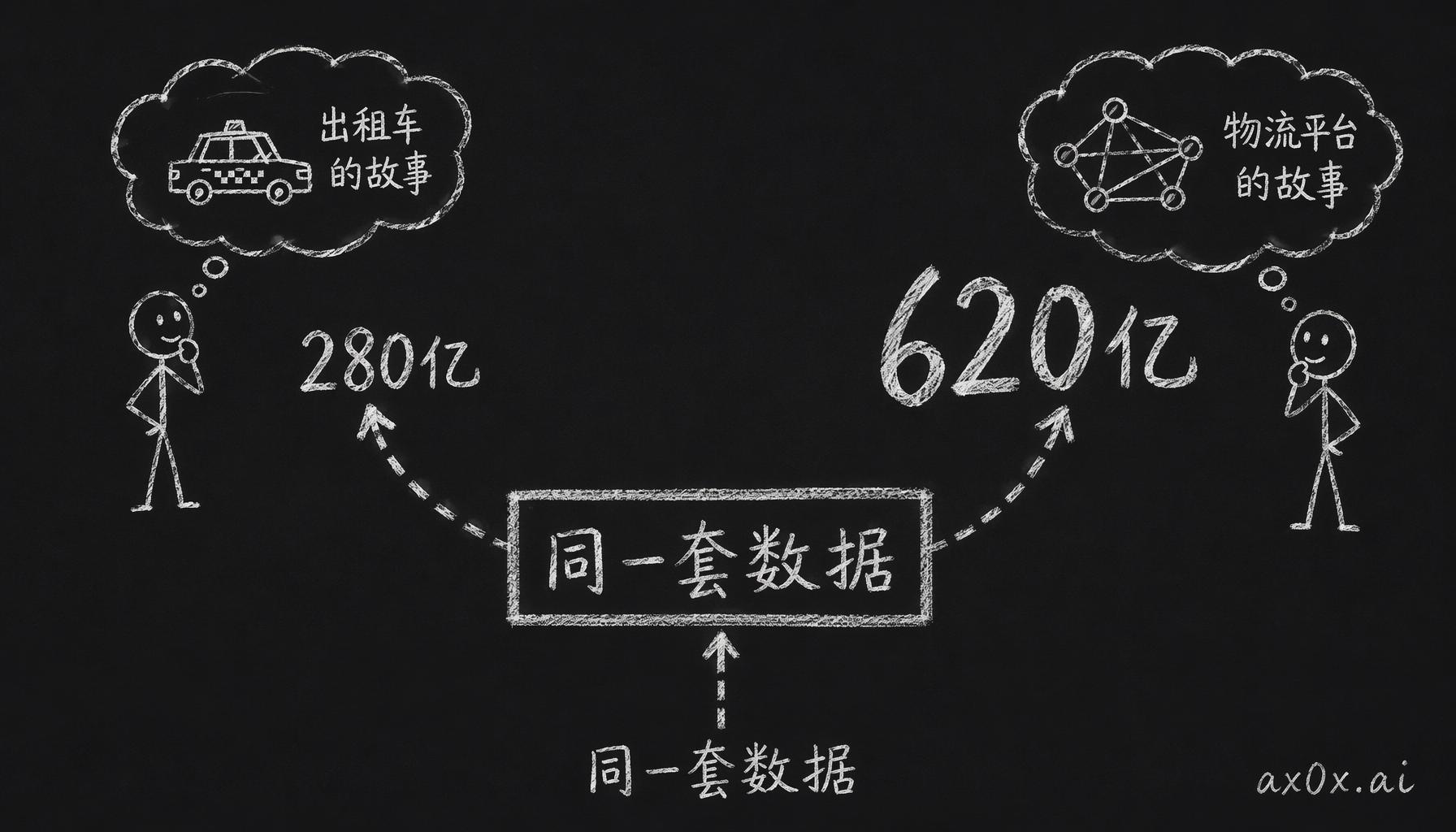 同一个 DCF、同一套数据,选不同的故事就会算出差一倍多的估值。
同一个 DCF、同一套数据,选不同的故事就会算出差一倍多的估值。
目录
1. 估值就三种办法,各回答一个问题
DCF 回答的是:这家公司要是按我预期的故事走下去,今天值多少钱?做法是把未来每年的自由现金流折回今天。三种方法里它看得最深,但也最脆,随便哪个假设偏了,结果就跟着偏。
倍数法 回答的是:跟差不多的公司比,这家算贵还是便宜?市盈率、市销率都属于这一类。最快,最直觉,但它有个隐含前提,就是你找的那些「类似公司」得真的类似。
资产法 回答的是:公司今天关门清算,股东能拿回多少钱?最保守的一种,对轻资产公司基本没用。
Damodaran 说过,三种方法看同一家公司,角度完全不同,但看的是同一件事。三个角度讲出来的故事要是大差不差,信心可以高一点;要是差距很大,那就得回头看看差在哪了——多半有个关键判断你自己还没想清楚。
2. DCF 要你做五个选择
DCF 的逻辑其实特别简单:一家公司值多少钱,等于它未来所有现金流折回今天加起来。听着简单吧?所有的复杂都藏在「未来所有现金流」和「折回今天」这两个短语里。拆开看,你要做五个选择。
收入增速。 Uber 那个例子里 280 亿和 620 亿的差距,主要就来自这个数字:「出租车公司」对应一个增速,「物流平台」对应另一个增速。这个数没法直接算出来,它背后压着三个更基础的问题:市场有多大、你能吃到多少、这个速度能维持多久。
利润率。 你选哪条利润率的走势,DCF 里的现金流就有多大。这个选择其实就是你对竞争格局的判断。
资本开支和再投入。 同样是赚 10 亿,半导体公司和软件公司留在手里的自由现金流可能差三倍。
折现率。 就是你要求多高的回报来补偿风险。这个数字的影响是指数级的,对那种大部分价值都压在远期的公司影响特别大:动两个百分点,估值可能就动 30% 以上。
终值。 预测期结束之后,公司还值多少钱?大部分 DCF 里,终值要占总价值的 60% 到 80%。什么概念?你估值的六到八成,取决于你对十年以后的假设。
顺序上有个讲究:先把故事写出来,再去填数字,别反过来。这五个数字必须讲同一个故事——你填了 40% 的收入增速,又填了 30% 的利润率,等于在暗示这家公司可以不花钱还高速增长,绝大多数行业做不到这个事。先写故事还有个好处:用一句话讲清楚「我认为这家公司是什么」,回头就能检查五个数字之间有没有互相打架。两个人估值对不上,去查计算大概率查不出什么,多半就是俩人讲的故事没对上。
3. 动一动假设,看你到底在赌什么
大部分人做完 DCF 就停了,挺可惜的,后面其实还有一步:动一动假设,看数字会动多少。假设跟假设的分量差别很大,有的你动两三个百分点,估值几乎不动;有的动两三个百分点,估值直接变 30%。那个最敏感的假设,其实就是你在赌的东西,只是你自己可能没意识到。
 五个假设里总有一个最敏感——动一点估值就动 30%,那面承重墙才是你真正在赌的东西。
五个假设里总有一个最敏感——动一点估值就动 30%,那面承重墙才是你真正在赌的东西。
举个例子。给一家云计算公司做 DCF,把终值增长率从 3% 降到 2%,估值掉了 25%。做的时候你心里想的可能是「它能不能保持 25% 的增速」,敏感性分析一跑就看出来了,这个估值的大头其实压在「十年之后它还在持续增长」这个假设上。这俩是两个不一样的问题啊。
再进一步,把相关的假设放在一起动:画一张二维表格,横轴一个假设,纵轴一个假设,每个格子放一个估值。然后看你觉得最可能的故事组合落在哪片区域,再看那片区域的估值跟市价是什么关系。
敏感性分析还有个附带的好处:它直接告诉你接下来该研究什么。估值对终值最敏感,就去研究这家公司的长期竞争地位;对利润率最敏感,就去研究成本结构和竞争动态。
4. agent 做估值的四个坑
第一个坑:默认讲共识。 agent 默认按市场共识来填假设,跑出来的自然就是一份共识估值。可市价本身就反映共识啊,拿共识估值去跟市价比,等于循环论证。你得把自己的故事带进去——你跟共识不一样的地方,才可能藏着优势,当然也可能藏着错误。
第二个坑:永续增长率照抄默认值。 agent 几乎一定给你填 2% 到 3% 的永续增长率。但给一家科技公司假设「永远增长」,里面藏着一个很大的判断:高增长期到底什么时候结束?这个问题 agent 不会主动问你。
第三个坑:折现率的盲区。 agent 算折现率不会犯数学错误,但它可能把一家该按 14% 折现的公司按 10% 折了,因为标准公式对它没见过的风险是视而不见的。
第四个坑:只会顺着历史外推。 agent 习惯从过去的增长率做渐进式调整。行业拐点、竞争格局突变这种历史数据里没有先例的事情,它处理不了。
回头看这四个坑,毛病出在同一个地方:agent 分不清哪些是技术参数、哪些是叙事选择,碰到叙事选择也直接当参数填个值,它不知道这一步该停下来问人。所以下面这套流程的思路很直接,讲故事的部分留给人,算的部分交给 agent。
 分工的关键在于分清叙事选择和技术参数——讲故事留给人,算数字交给 agent。
分工的关键在于分清叙事选择和技术参数——讲故事留给人,算数字交给 agent。
流程模板
第一步,写一段关于这家公司未来的故事,三到五句就够。第二步,让 agent 按这个故事做 DCF。第三步,逐个审假设,看跟故事对不对得上。第四步,让 agent 做双变量敏感性分析。第五步,让 agent 用倍数法再做一个参考估值。第六步,比较 DCF 和倍数法的结果。
Workshop · 改一个假设,看数字动多少
时间: 60 到 90 分钟 产出: 一份估值工作文档
第一步:选一家公司。 用第 4 章 workshop 里分析过的那家就行。
第二步:写故事。 三到五句,讲清楚你对这家公司未来五年的判断,这一步不需要任何数字。
第三步:让 agent 做 DCF 估值。 要求它把所有核心假设列出来,每个假设为什么这么选都得解释。
第四步:审假设。 至少改掉一个你不同意的假设,让 agent 重算,然后做双变量敏感性分析。
第五步:在文档里把三个空填了。 「估值最敏感的假设是 __________。」「这意味着我在赌 __________。」「支撑这个赌注需要的证据是 __________。」
亲手改一个假设、看着估值动了 30%,你对那串数字的感觉会跟以前不一样:看着挺精确的,其实每一个都是人选出来的。目标价这个数,agent 随时能给你重算一个。你自己填的那三个空就不一样了——你对哪个假设最敏感、在赌什么、还缺什么证据,这三个空 agent 替你填不了,得你自己来。
第 6 章讲风险:1998 年的 LTCM,所有模型都说安全,它是怎么崩掉的。