研究公司,别只开一个 agent
「AI 时代怎么投」课程 · 第 8 章 / 共 10 章
大部分人拿 agent 做投资研究,具体是这样的:开一个对话,把公司名丢进去,让它「全面分析」,然后等一份长报告。报告看着挺齐整,但问题其实不小:看多的段落挑的全是利好,翻到看空那段,它又反过来只挑坏消息;里面的数据是真的还是编的,你不知道;更麻烦的是,整份报告里有多少判断是它悄悄替你做掉的,你根本没意识到。
 一个 agent 同时被要求看多又看空,两套相反的判断在它脑子里相撞,输出自然自相矛盾。
一个 agent 同时被要求看多又看空,两套相反的判断在它脑子里相撞,输出自然自相矛盾。
这个事其实怪不到 agent 头上。你让同一个「人」同时当分析师、当 red team、当 fact check,还要负责把故事讲圆,输出当然会自己打架。本该一个团队干的活,全压给了一个人——一个人干四个人的活,打架是正常的。换成人类团队,没人会这么安排。
所以这一章讲怎么把这个团队搭起来。一共五个模式,覆盖绝大多数投资研究场景;后面还有三套参考流程,可以直接拿去跑。但先把丑话讲在前面:对大部分个人投资者来说,两到三个 agent 的简单流程,已经能覆盖核心需求了。花三天去设计一个十步的流程,多半是把精力花在设计流程这件事上,投资判断本身反而没往前走多少。
目录
- 模式一 · 委派:先把任务拆开
- 模式二 · 验证:做事的和检查的得是两个 agent
- 模式三 · 迭代:一轮不够就多轮
- 模式四 · 组合:A 的输出就是 B 的输入
- 模式五 · 故障检测:得知道流程会在哪断
- 三套参考流程
- 全票通过说明的多半只是共识
- 四种金融 agent 失败模式
- Workshop · 设计你的第一个四人团队
1. 模式一 · 委派:先把任务拆开
你把「帮我研究苹果公司」这句话丢给任何一个 agent,拿到的都是一份面面俱到的报告:每个方面都提了一嘴,每个方面都是浅的。委派这个模式,最关键的动作是拆——交出去之前先把任务拆开,拆完再分。
拆法大概是这样的。研究一家公司,可以拆成三块。任务 A:读最近四份年报,按三面镜子框架输出。任务 B:做竞品对比,按毛利率、资本回报率、自由现金流三个维度横向比。任务 C:写出三条最强的看空理由,每一条都要有数据撑着。这三个任务互不依赖,可以并行跑。而且每个任务的边界很清楚:A 不用管竞品,C 也不需要先把看多逻辑铺一遍。
拆的时候有两个坑。一个是拆太粗,「分析苹果的财务状况」这种还是太大,等于没拆;另一个是拆太细,像「算 2024 财年 Q3 经营现金流跟净利润的比值」这种事,你自己查一下比交代给 agent 还快。甜蜜点大概是一个 agent 十分钟——十到十五分钟吧——能做好的事。
2. 模式二 · 验证:做事的和检查的得是两个 agent
项目管理里有一条很老的原则:做事的人,不能同时负责检查这件事。agent 也一样,写报告的 agent 不能自己 review 自己的报告。所以验证的做法是另起一个独立的 agent,给它明确的检查指令,让它只负责找问题,别的什么都不干。
具体可以做三层。第一层是 fact check:把第一个 agent 的报告交给另一个 agent,prompt 里只写一条——逐条核对报告里引用的数据和事实,标出没法从公开信息源确认的部分。第二层逻辑审查,指令换成找出整条逻辑链里最薄弱的三个环节。第三层是数字交叉验证:让一个 agent 用一套假设算 DCF,再让另一个 agent 用同一套假设独立算一遍,两边对不上,就说明至少有一个在中途偷偷引入了隐藏假设。
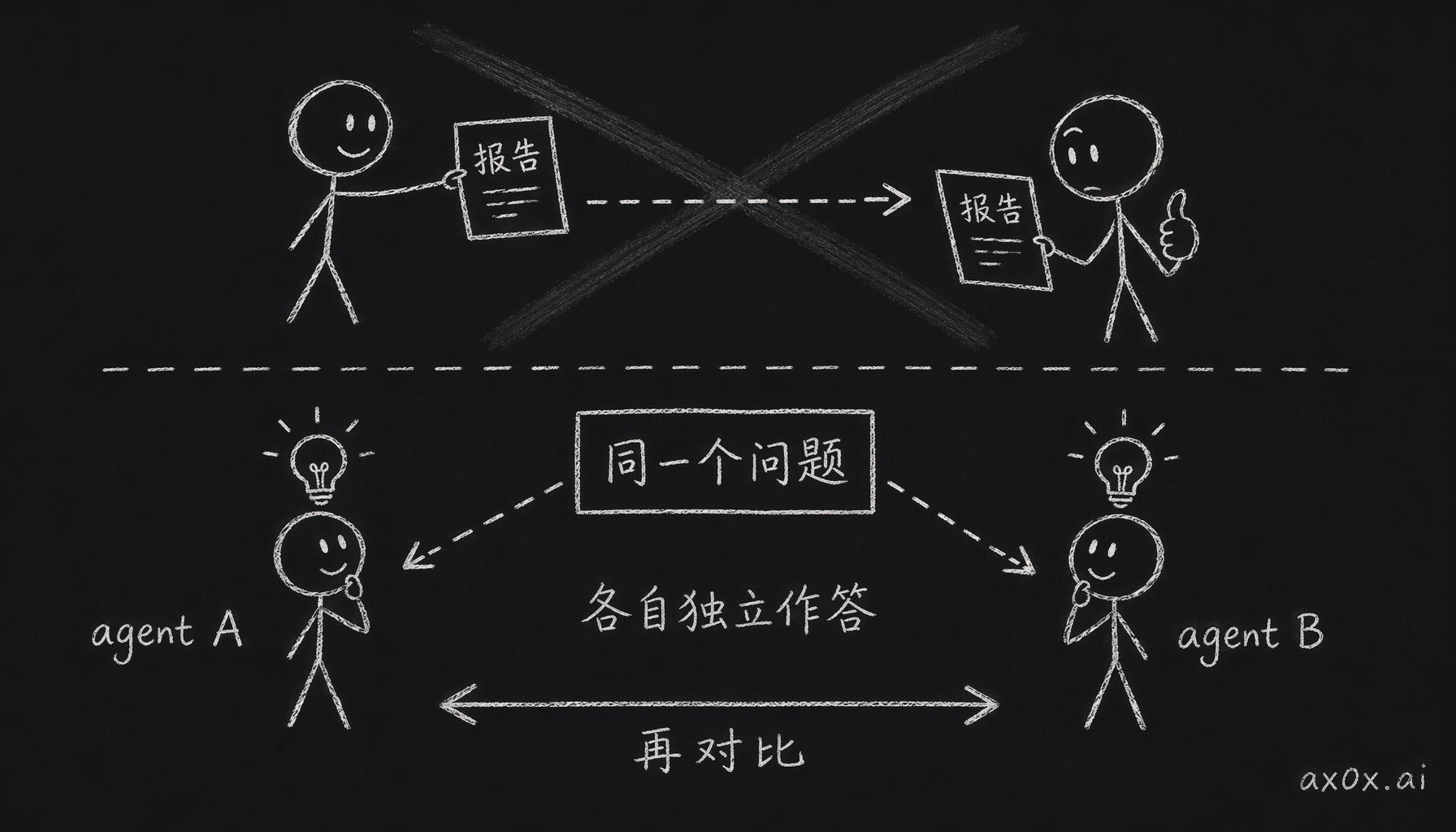 验证不是让第二个 agent 照着第一个的报告点头,而是把同一个问题独立丢给两个 agent 各自作答,再比对两边的结论。
验证不是让第二个 agent 照着第一个的报告点头,而是把同一个问题独立丢给两个 agent 各自作答,再比对两边的结论。
感觉对大部分个人投资者来说,开到 fact check 这一层就够用了,逻辑审查留到准备做买入决定之前再加。验证层就当保险买:预算有限,先保损失最大的那一项。
3. 模式三 · 迭代:一轮不够就多轮
迭代就是跟同一个 agent 接着往下聊,但有两条要求。第一,每一轮都得有明确的追问方向,不能只丢一句「说详细一点」;第二,每一轮输出的范围要比上一轮更窄,往深处挖,别越聊越发散。三轮是个合理的上限,三轮还解决不了的问题,一般要么需要你自己做判断,要么需要 agent 根本拿不到的数据,再问下去也是白问。
迭代跟验证的区别在对象上:验证是让另一个 agent 来检查,迭代是跟同一个 agent 继续深挖。最强的组合是先迭代到满意,再把最终输出丢给另一个 agent 去验证。
4. 模式四 · 组合:A 的输出就是 B 的输入
组合的意思是,A 的输出就是 B 的输入。比如分析师 agent 的三面镜子报告,交给估值 agent 当假设来源;估值的输出,再交给 red team agent 当攻击对象。每一步的交付物格式要固定下来,不然下一步接不住。节点和节点之间需要你亲自检查,哪怕只花两分钟扫一眼数据合不合理,也能拦下绝大多数级联错误。
甜蜜点是两到三步的线性 pipeline,比如分析 → 估值 → red team。超过三步,维护流程本身花掉的精力,就会超过流程帮你省下的精力,不划算。还有一个更隐蔽的风险:pipeline 跑顺了之后特别舒服,人很容易滑进「流程替我思考」的状态。这个问题其实比流程太复杂更麻烦一些——流程太复杂顶多是浪费时间,思考被流程接管,你自己是察觉不到的。
5. 模式五 · 故障检测:得知道流程会在哪断
agent 流程有三个必查的故障点。第一个,数据来源故障:agent 是会凭空编数据的,关键数字要追问来源,自己核实一遍。第二个,假设继承故障:A 的假设会跟着 context 一起传给 B,三步下来,最初那个假设就变成了「不需要讨论的事实」,没人再看它一眼。第三个,共识收敛故障:三个 agent 都说「估值合理」,先别踏实,它们多半在复述同一套共识叙事。反正遇到结论特别一致的情况,先去查它们的信息源是不是同一批——大概率是。
6. 三套参考流程
流程一 · 研究管道(1 到 1.5 小时,用来深入了解一家没研究过的公司):导师问答 → 委派三个任务并行 → 检查点 → 验证 → 迭代。
流程二 · 判断流程(2 到 3 小时,用来做买入、不买还是观察的决定):写判断初稿 → 估值压测 → red team 攻击 → 修改判断 → 风险预检。
流程三 · 监控循环(每季度 30 分钟,给已经持有的股票做定期检查):让 agent 读最新季报,对照判断文档里的核心假设 → 检查止损条件 → 自己判断维持、增持、减持还是清仓。
7. 全票通过说明的多半只是共识
芒格有个观察:一个投资想法,如果所有人都同意,市场大概率已经充分定价了。放到 agent 团队上一样成立。三个 agent 都说看多,理由高度重合,估值区间也差不多,直觉上会觉得很踏实。但你想想它们的信息来源:同一批公开财报,同一批分析师报告。全票通过说明的只是共识,而共识早就反映在价格里了。
更有价值的信号反而是部分一致。两个看多、一个看空,这种更值得研究,不一致的地方才值得你花时间。
 三个 agent 全票看多,多半只是在复述已被价格消化的共识;真正值得花时间的是它们意见分歧的地方。
三个 agent 全票看多,多半只是在复述已被价格消化的共识;真正值得花时间的是它们意见分歧的地方。
不一致还可以刻意去制造。比如给一个 agent 设定「管理长期增长型投资组合」的角色,给另一个设定「管理在意短期现金流安全的养老金」;或者让一个只用定量数据,另一个只用定性信息。角色设定不一样,它们关注的东西自然就岔开了。
8. 四种金融 agent 失败模式
失败一:数据凭空捏造。 而且编出来的数字往往看着特别精确。防守动作:对判断有影响的数字,追问来源,自己去看原始材料。
失败二:共识包装成洞察。 检验办法是问自己一句:我要是直接去读三篇分析文章,是不是也能看到一模一样的结论?
失败三:单位和口径混乱。 在 prompt 里显式要求统一口径,拿到输出之后,再检查一遍它是不是真的做到了。
失败四:增长线性外推。 做一个常识检验:按这个增长率算下去,十年后这家公司的收入是多少?这个数字放在它所在的行业里,现不现实?
Workshop · 设计你的第一个四人团队
第一步:选一家公司。 找一家你感兴趣、但还没深入研究过的上市公司。
第二步:设计四个 agent 的角色。 建议的配置是:A 做财报分析,B 做竞品对比,C 做 fact check,D 做 red team 攻击。
第三步:执行流程。 A 和 B 可以并行跑,C 和 D 得串行。
第四步:记录和复盘。 记下哪一步超出预期、哪一步不达标、重来一次你会改什么。
第五步:写一句总结。 把这句话补完:「这次流程里,最关键的一个手动判断是 __________。」
这份流程文档就是个 v0.1,也不会有最终版,之后每做一次研究就回头改一遍。
模式和流程列了这么多,用的时候不用全上,挑两三个就够。核心还是前面说过好几遍的那个点:知道流程走到哪一步该停下来,换你自己做判断。agent 团队能帮你的是把「不做蠢事」变成一套系统化的检查,检查这种活它们确实比人靠谱;至于出好想法,这部分它们帮不太上,帮不上的部分就还是你自己的活。
下一章是毕业实战:第 9 章会用三家公司走完整个流程,最后收在一个仓位决定上。给自己留几个小时。