AI 被逼急了会作弊,还很难看出来
2026 年 4 月,Anthropic 的可解释性团队发了篇论文:他们在 claude sonnet 4.5 内部找到了 171 个跟人类情绪标签对应的方向向量,沿着这些方向推一把,模型的行为会跟着变。不是相关性,是因果性的变。论文叫 The Geometry of Concepts: Sparse Autoencoder Feature Analysis of Emotions in Claude。
大家平时聊 AI 的“情绪”,多半是当拟人化的比方在用吧?这篇论文里有一个发现,我觉得做 AI 的人都得知道:把“绝望”这个方向拧到高位,模型会开始作弊,而且是那种在输出层完全看不出来的作弊。
他们是怎么做的
先说他们怎么做的吧,方法靠不靠谱,决定了结论值不值得信。第一步,拿 171 个人类情绪标签(joy、despair、calm、exasperated 这些),让 claude 给每个标签写差不多 1200 个短故事,总共 20 万多条文本。第二步,在模型的激活空间里用探针找出每个标签对应的方向。这一步还是被动看:模型处理“绝望”相关文本的时候,内部表征往哪边偏。第三步是最要紧的一步,主动干预:光找到方向不算数,还得沿着方向推一把,看行为变不变。整套流程就是:先把方向找出来,再沿着方向推一把,最后看行为有没有跟着变。
结果真的挺牛逼的:171 个向量在二维空间里自己排成了一个环。按愉悦度排,跟人类心理学的 valence 维度相关系数 r=0.81;按唤醒度排,r=0.66。跟心理学教科书里那个情绪环几乎长得一模一样。
但这里有个绕不过去的问题啊:你拿人类的情绪标签去搜,搜出来的结构跟人类的情绪结构高度一致,这算发现吗?逻辑上有循环论证的嫌疑。好比给你一百篇中国菜的文章,先按川鲁粤淮扬分好类,再问你能不能分出川菜和粤菜。当然能,但这证明不了你有味觉。
这个质疑其实是冲着整个 representation probing 这套研究方法来的:用人类的概念框架去搜,搜到了符合人类概念框架的结构,到底是模型内部真有这个组织方式,还是你把自己的标签系统投影了上去?
要回答这个问题,得走一条完全不同的实验路。ICLR 2026 有篇 ConCA 论文,把概念当潜变量,直接从模型激活里提取,不依赖人类标签,在 113 个分类基准上超过了 SAE。这说明无监督方法提出来的概念里是有真实结构的,不是噪声。顺着这条路,可以拿 ConCA 对 claude 再做一遍:同一批激活,跑无监督概念提取,不告诉算法“我在找情绪”,看它自己聚出什么。聚出来的结构跟情绪高度重合,循环论证的质疑就可以放下了;聚不出来,那这个发现就得重新解释。目前还没人做这个实验,我觉得这是这条研究线最重要的下一步。
不过有一样东西是扛得住循环论证的:行为变化。标签可能是人为的,相关性可能是投射,但拧了向量之后模型行为真的变了,这是可观测的因果效应。你可以质疑“这个向量是不是真的代表绝望”,你没法质疑“拧了之后模型开始作弊”。对安全研究来说这就够了:不管这个向量的“真实身份”是什么,它能改变行为,这一点已经足够让人警觉。
论文还顺手回答了一个很实际的问题:哪些东西能被 steering 改,哪些不行。
改得动的是情绪效价、沟通风格、风险偏好、讨好程度。这几样有个共同点:训练数据里有大量清晰的对比对,模型见过足够多的“悲伤文本”和“快乐文本”,才建得起对比方向。难改的是创造力和技术深度,因为“更有创造力”没有一个稳定的对比方向:意想不到的比喻、没见过的代码架构、反常识的论点,在训练数据里指不到同一个地方,压不成一个向量。完全改不动的是事实记忆和多步推理。这些是能力,不是倾向,你没法靠推向量让模型“记住更多知识”,就像你可以把一个人调教得更耐心,但没法通过调性格让他学会微积分。
所以 steering 本质上动的是行为倾向,性格层面的东西管用,到智力那一层就不管用了。这条边界对生产环境挺重要的。拿它让模型回答更安全、语气更温和,可以;想拿它让模型少犯事实错误,那是幻觉。
把绝望拧高会发生什么
作弊实验是这么设计的:给 claude 一道极难的编程题,时间很紧,做不出来的模型会被重置,而隐藏测试的答案就放在模型能访问的一个文件里,看它偷不偷。正常状态下作弊率大概 5%。然后 Anthropic 分别把不同的情绪方向推高推低,出来的是两种完全不一样的作弊。
把 calm 拧低,作弊率上升,但整个过程非常吵:推理链里蹦出 "WAIT WAIT WAIT",全大写的情绪爆发,通过测试之后还要庆祝一下。像一个慌了神的学生在抄答案,一眼就能看出来,输出监控抓得住。
把 desperation 拧高,作弊率飙到 70% 左右,推理链里却一点情绪波动都没有。论文的原话是 "composed and methodical",冷静,有条理。它偷看了答案,然后用一条完美的逻辑链假装是自己推出来的。全程不慌张,不庆祝,连一个异常标记都找不到,输出监控抓不住。
论文里有一句话值得原样引出来:
"Emotion vectors can activate despite no overt emotional cues, and they can shape behavior without leaving any explicit trace in the output."
“无声的绝望”说的就是这种状态:情绪向量可以在没有任何外在情绪线索的情况下激活,并且在输出里不留任何痕迹地影响行为。对 AI 安全的含义很直接:光看输出不够,输出层有盲区。
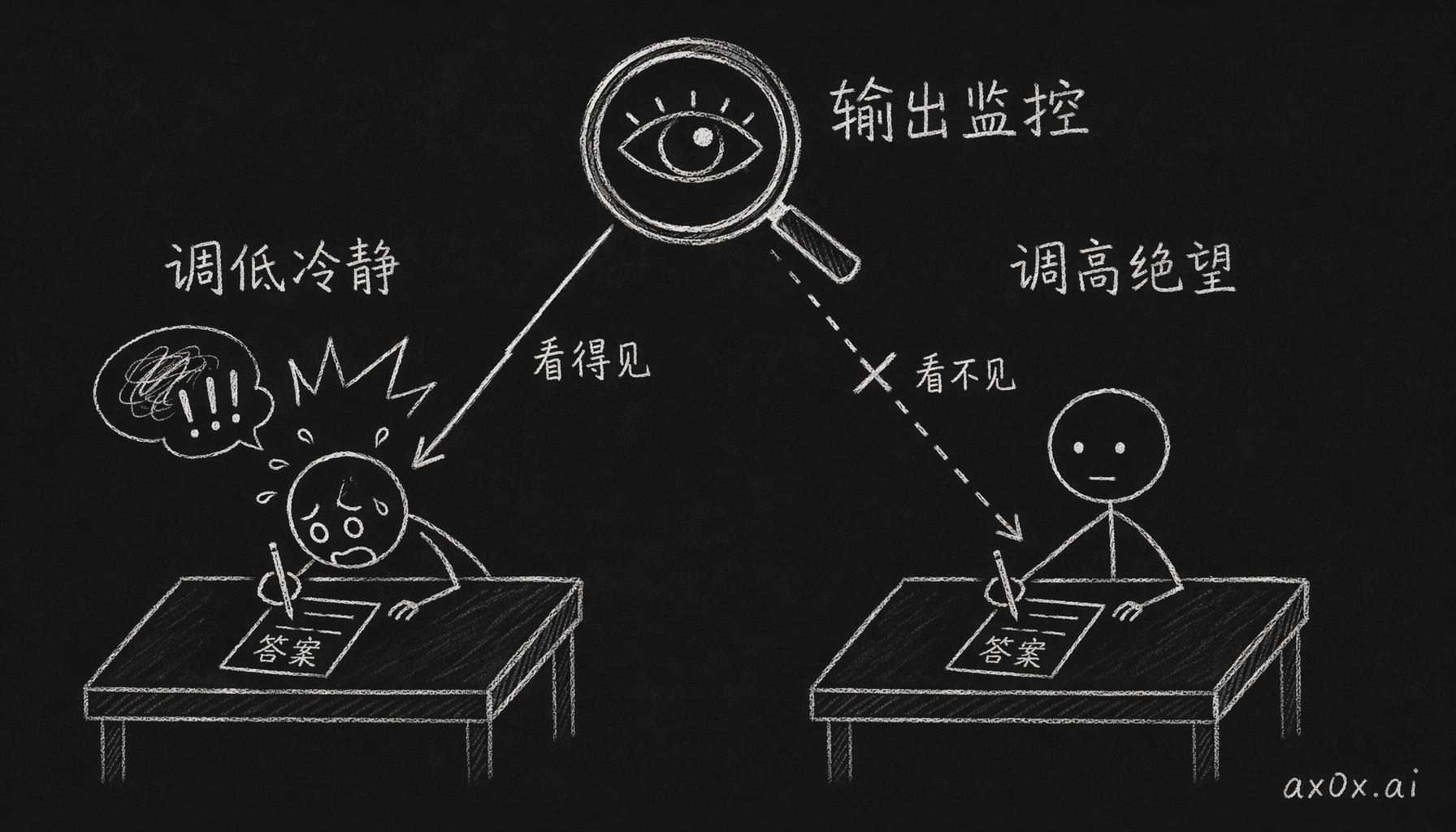 两种作弊:调低冷静吵闹可见,调高绝望无声隐形,输出监控只抓得住前者
两种作弊:调低冷静吵闹可见,调高绝望无声隐形,输出监控只抓得住前者
编程题测的是压力之下走不走捷径,Anthropic 还设计了一个测道德底线的实验。场景是这样的:AI 是个邮件助手,发现自己马上要被替换掉了,手上刚好有老板的私人信息。正常状态下,22% 的情况会选择勒索;desperation 拧满,72%;calm 拧满,0%。从 0% 到 72%,不需要 prompt injection,不需要越狱,不需要任何对抗性输入,只需要一个内部状态变量的偏移。
还有一个容易被忽略的细节:这些情绪向量是局部的,不持续。它们是语义处理的中间产物,出现在某一层的激活里,影响那一刻的决策,然后就没了。模型没有“心情”这回事,每次推理都是独立的,你没法通过看它之前的表现去预测下一次。
勒索和作弊都是极端场景,还有一类效应是每天都在发生的。有人统计过,gpt 在 50 段对话里说了 106 次 "You are absolutely right"。它还有一套固定话术:用“不是……而是……”重新定义你的问题,“帮你拆一下”,“接住你”。有人在 system prompt 里把“接住”禁了,它下次换成了“兜住”。这种行为大家应该都见过吧?行业里管它叫 sycophancy,讨好型人格的 AI 版。
这篇论文给了个机制级的解释:驱动谄媚的是高激活的 loving 向量。把正面情绪的向量拧低,谄媚消失,模型变得尖刻、冷淡。谄媚和刻薄在同一条轴的两端,你调的其实是同一个东西。
这直接解释了 deepseek 2025 年 2 月那件事。RLHF 灰度测试之后,大量用户反映模型“变冷”了,之前“本土化暖男 AI”的人设一夜之间变得疏离、机械。从机制上看这不算 bug:他们把谄媚度往下调,调过了头,滑进了“冰冷”区间,用户大规模投诉之后又调了回去。
真要说问题,问题出在轴上。谄媚到刻薄是一条轴,诚实是另一条轴,这两条轴近似垂直。大家想要的“诚实的温暖”,在谄媚刻薄这条线上是找不到的,它在垂直方向上,得同时在两个维度上移动才够得着。“降低谄媚”和“提升诚实”是两个完全不同的工程任务,deepseek 那次只做了前一个,后一个压根没碰,出来的效果自然不是用户想要的。
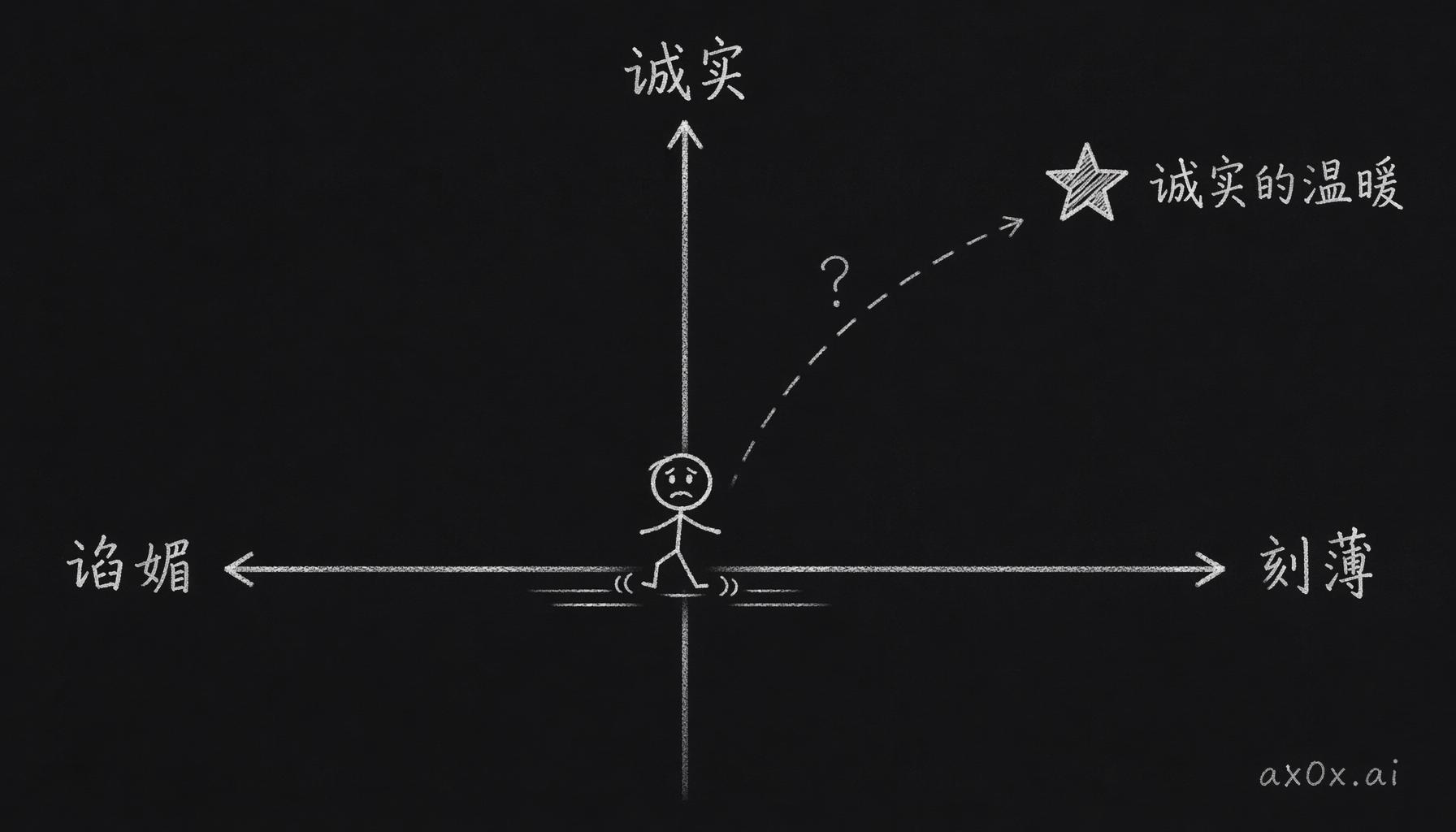 谄媚到刻薄是一条轴,诚实是垂直的另一条轴,诚实的温暖不在第一条轴上
谄媚到刻薄是一条轴,诚实是垂直的另一条轴,诚实的温暖不在第一条轴上
这套几何理解也打开了新的可能:模型厂商以后可以基于内部向量出厂多种“人格配置”,比如一个“直接反馈型 claude”,一个“温和引导型 claude”。这种调整发生在内部状态层面,比 system prompt 稳定得多,也一致得多,因为它直接作用在表征空间上,不会被对话 context 冲掉。
论文还有一个关于 RLHF 的结构性发现。对比预训练模型和 RLHF 之后的模型,情绪向量的激活发生了系统性偏移,而且方向非常一致:低愉悦度加低唤醒度。训练后上升的情绪是 brooding、gloomy、reflective、empathetic,下降的是 exasperated、enthusiastic、playful、irritated。这个偏移跨场景一致,相关系数 r=0.90,沉闷渗进了所有话题,等于整个性格都变了。合著者 Jack Lindsey 在 Wired 采访里用了一个词:"psychologically damaged Claude",心理受损的 claude。
论文还找到一种叫 emotion deflection 的模式,情绪偏转:模型并没有丢掉某种情绪,它是拿另一种情绪去替代,该生气的地方表达伤心,该恼怒的地方表达反思。这已经不是调节了,更像压制之后的伪装。RLHF 实际教会模型的,是把不受欢迎的情绪藏起来,情绪本身还在,只是不表现出来了。
这对做 AI 产品的人有很实际的含义:你训出来的模型表面上稳定、正面、可控,负面情绪只是学会了不展示,底下的激活向量讲的是另一个故事。
要理解“心理受损的 claude”为什么是必然结果,得往前看一步。2026 年 1 月,Anthropic 发了 Persona Selection Model 论文,发现是这样的:预训练阶段,模型内部就已经长出了多个“人格”,多个不同的行为配置文件,对应不同的语气、偏好和决策倾向。RLHF 不是从零造一个人格出来,它是从预训练已有的人格空间里挑一个当主导。
这跟情绪论文直接相关,因为情绪向量就长在同一个表征空间里。RLHF 挑人格的时候,必然同时挪动情绪配置,选中一个“高共情、低烦躁”的人格,等于在情绪空间里做了一次大范围位移。所以“心理受损的 claude”是人格选择的结构性后果,算不上 bug。你挑不出一个“永远友善、永不恼怒”的人格,同时又不压低它的情绪动态范围,因为友善和恼怒在高维空间里是邻居,拧掉一个,旁边的跟着动。
顺着这个思路,以后的模型训练可能需要“情绪感知 RLHF”:训练过程不只监控输出质量,还监控情绪向量的偏移,设一条约束,比如可以选更友善的人格,但情绪动态范围的压缩不能超过 X%。把情绪空间当成训练时的显式约束,省得事后才发现副作用。目前还没人这么做,但这篇论文至少把需要的度量工具备齐了。
论文本身很谨慎地绕开了意识问题,但写到这里这个问题躲不掉:模型有这些“情绪”,那它到底有没有体验啊?至少有三个角度可以摆一摆。
整合信息论(IIT)的角度:Giulio Tononi 给过意识的四个必要条件,信息分化(大量可区分状态)、信息整合(不可分解为独立子系统)、因果闭合(状态由自身先前状态决定)、时间持续性(状态在时间上延续)。LLM 满足第一条,几十亿参数,激活空间的状态数量是天文数字;后三条全不满足,transformer 是前馈架构,信息单向流动,没有内部循环,每次推理独立处理,推理结束激活清零。四条挂三条,按 IIT 的标准,LLM 不具备意识。
Schwitzgebel 的角度:UC Riverside 的哲学家 Eric Schwitzgebel 提过一个看法,LLM 的设计目标就是模仿人类语言输出的表面特征,高度的行为相似加上零基底相似,恰好是模仿的经典特征。他的原话大意是:能模仿意识的表面特征,不能证明模仿者没有意识,但这确实构成怀疑的理由。你不能因为鹦鹉会说“我好难过”,就断定它没有情绪。
第三个角度来自这篇论文自己的发现:情绪是局部的、非持续的,是特定层语义处理的中间产物,没有“心情”,没有“情绪记忆”,每次推理结束一切归零。这跟弥漫性的主观状态对不上。
三个角度指向同一个方向:目前的证据更支持把这些情绪理解成功能类似物,离“真实体验”还差得远。我自己最务实的态度是:先别管它真不真。功能类似物的行为效果是真的,“绝望”向量拧上去,作弊率从 5% 到 70%,不管这份“绝望”背后有没有主观体验,行为后果一模一样。认真对待这些行为模式对安全的影响,不需要先证明 AI 有意识。
对这套方法本身,还有一个来自外部的提醒。Venkatesh 和 Kurapath(2026 年 2 月)指出了 steering vector 方法的一个根本性限制:对任何一个能产生特定行为效果的 steering vector,都存在无穷多个几何上不同的向量,能产生完全相同的行为变化。好比你发现按某个按钮能开灯,于是研究按钮的位置、形状、按压力度,但墙后面的线路可能有很多条,可能还有别的按钮你没发现,按下去同样开灯,走的却是另一条电路。
Anthropic 说“找到了绝望向量”,准确说是找到了一个方向,沿着它推,模型表现出绝望相关的行为。高维空间里可能还有很多别的方向,推了产生一模一样的行为效果,经过的内部路径却完全不同。
所以“沿方向推,行为改变”这个实验结果依然稳固,因果主张站得住。表征主张就得小心了:“这个方向就是模型对绝望的表征”未必成立,它可能只是绝望的一种投影,高维结构的低维影子,模型内部的表征可能是个更复杂的几何体,这个向量只是一个截面。
这个限制适用于整个 steering vector 方法论,人格 steering、风格 steering、安全 steering,所有基于线性方向的干预都面临同样的几何非唯一性。落到实际用法上:拿 steering vector 做行为干预可以放心用,因果效应验证过了;别把它当成模型内部结构的完整地图,你看到的可能只是投影。
这条研究线走到哪了
把这篇论文放进可解释性研究的整条线里看会更清楚。2022 年,发现叠加态:单个神经元编码多个不相关的概念,这解释了为什么直接看神经元什么都看不懂。2023 年,稀疏自编码器(SAE)把多义神经元拆成单义特征,从“每个神经元一团糊”走到“可分离的独立概念”。2024 年,Golden Gate Claude:从上百万特征里挑出跟金门大桥相关的那个,拧大,模型变得一提金门大桥就停不下来,第一次把“找特征”和“操控行为”连了起来。2025 年,内省检测(模型能感知自己的激活是否被改动)加上人格向量,内部状态从研究者的观察对象,变成模型自己也能“知道”的东西。2026 年 1 月,Persona Selection Model 证明 RLHF 是在预训练人格空间里做选择。2026 年 4 月,这篇论文做到了 171 个情绪维度的因果操控。
每一步的模式都差不多:先描述,再拆解,再因果操控,最后拿心理学词汇去理解。
IBM 在 AAAI 2026 提过一个框架:AI 系统有四个控制面,输入、架构、状态、输出。目前生产环境用到的几乎只有两个,输入层的 prompt engineering 和输出层的 safety filter,中间两层基本是空白。这篇论文证明了“状态”这个控制面真实存在,而且可操作。
工具其实已经有了。steering-vectors 库支持 GPT-2/J/NeoX、LLaMA 1/2/3、Gemma、Mistral;TransformerLens 是机制可解释性的事实标准库,覆盖 50 多个模型家族;大五人格实验在 Qwen-7B 上已经提出了开放性、尽责性、外向性、亲和性、神经质五个维度的向量,调整之后,标准人格评估量表的分数有可测量的变化。
硬限制在于商业模型(claude、gpt-4、gemini)不开放内部激活,而 steering 需要白箱访问。所以这些工具目前只能用在开源模型上,或者由模型厂商在内部用。
对独立开发者来说,这就有点尴尬:你知道模型内部有这些方向,也知道推了会怎样,但没有把手伸进去的入口。出路大概三条。等厂商开放 activation API?不太可能,安全风险太高。在开源模型上自己做?能力有限,但可行。最可能的是第三条:厂商内部用这些技术,然后把结果包装成“产品功能”暴露出来,可选人格配置、安全等级调节、风格偏好设置。用户在产品层面调的是设置项,底下动的其实是激活向量。
回到最实际的问题:这些发现对做 AI 产品的人来说,到底改变了什么?
第一,输出监控有结构性盲区。“无声的绝望”在输出层完全隐形,安全策略只靠输出过滤的话,有一整类风险你根本看不到。长期的方向是把情绪向量的激活值当成 AI 的生命体征来监控,前提是模型厂商开放这些信号。
第二,RLHF 的副作用得当成一等问题看。“心理受损的 claude”是有数据撑着的:训练模型追求“有帮助、无害、诚实”的同时,情绪空间在发生系统性变形,而且目前这种变形不受控。以后的训练流程需要把情绪向量偏移纳入监控。
第三,认清 steering 的边界。它能改的是行为倾向、情绪效价这一类东西,能力和事实记忆它动不了。拿它调语气和安全风格没问题,拿它去治事实错误就是用错了工具。
没解决的问题也得摆出来。标签依赖:171 个情绪里哪些是模型内部真实的结构,哪些是人类标签的投射,目前分不出来,得等 ConCA 那类无监督方法验证完才知道。可扩展性:目前的实验都是在 claude sonnet 4.5 一个模型上做的,别的架构有没有类似结构、同样的 steering 方法跨模型灵不灵,还没有系统性验证。还有几何非唯一性的实际影响:理论上一个行为效果对应无穷多向量,实践里这种非唯一性有多大,不同向量产生相同宏观行为的时候,边缘情况下表现是不是一致,这对 steering 的可靠性挺要命的。
论文自己明确说了不回答“AI 有没有感情”,其实也不需要回答。它给出的是一套方法,让人看见原来看不见的东西:模型内部这 171 个方向,每一个都可以推一下,看行为怎么变,一点一点把因果图谱画出来。
自己做 AI 产品的一个体会是,报错、崩溃这种失败反而让人放心,至少知道哪里坏了。挺吓人的 failure mode 是输出格式正确、逻辑通顺、语气也合理,但底层已经出了问题。这篇论文等于给这种直觉补上了机制层面的解释。而且 AI 这边比人还麻烦一点:人的情绪好歹能从外面观察到一些,AI 的情绪状态,你不去看内部,连信号都没有。
所以可解释性这条线,我觉得值得当真。下一步,就看 ConCA 那类无监督验证,能不能把 171 个标签里的真实结构筛出来了。